一、jieba库的相关函数


二、词频统计((以下内容以百度搜索的散文为例)
步骤:
1、下载散文文本并以txt形式保存到与Python相同文件夹中
2、编写代码

三、wordcloud库的相关函数
w = wordcloud.WordCloud()
| 方法 | 描述 |
| w.generate(txt) |
向WordCloud对象w中加载文本txt >>>w.generate() |
| w.to_file(filename) |
将词云输出为图像文件,.png或.jpg格式 >>>w.to_file("outfile.png") |
配置对象参数
| 参数 | 描述 |
| width |
指定词云对象生成图片的宽度(默认像素400) >>>w = wordcloud.WordCloud(width=600) |
| height |
指定词云对象生成图片的高度(默认像素200) >>>w = wordcloud.WordCloud(height=400) |
| min_font_size |
指定词云中字体最小的字号,默认4号 >>>w = wordcloud.WordCloud(font_step=2) |
| max_font_size |
指定词云字体中的最大字号,根据高度自动调节 >>>w = wordcloud.WordCloud(max_font_size=20) |
| font_step |
指定词云中字体字号的步进间隔,默认为1 >>>w = wordcloud.WordCloud(font_step=2) |
| font_path |
指定字体文件的路径,默认为None >>>w = wordcloud.WordCloud(font_path="msyh.ttc") |
| max_words |
指定词云显示的最大单词数量,默认为200 >>>w = wordcloud.WordCloud(max_words=20) |
| background_color |
指定词云图片的背景颜色,默认为黑色 >>>w = wordcloud.WordCloud(background_color="white) |
四、生成词云的两种方法:
1、

2、

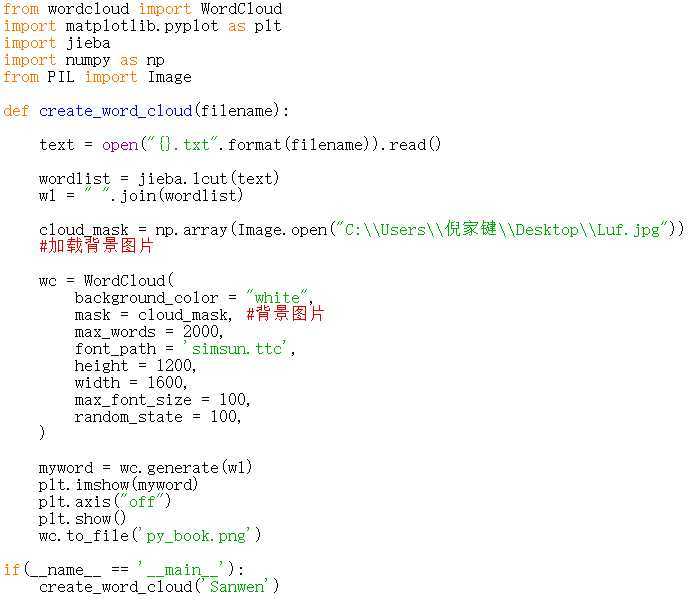
五、 加载背景图片生成词云
| 参数 | 描述 |
| stop_words |
指定词云的排除词列表,即不显示的单词列表 >>>w = wordcloud.WordCloud(stop_words={"Python"} |
| mask |
指定词云形状,默认为长方形 一、引用imread()函数 目前目前 scipy库不包含 imread 函数,imread函数在imageio库里。
二、使用其他库:numpy库、matplotlib库、PIL库 |


原图 词云
原文:https://www.cnblogs.com/ni23/p/12631966.html
