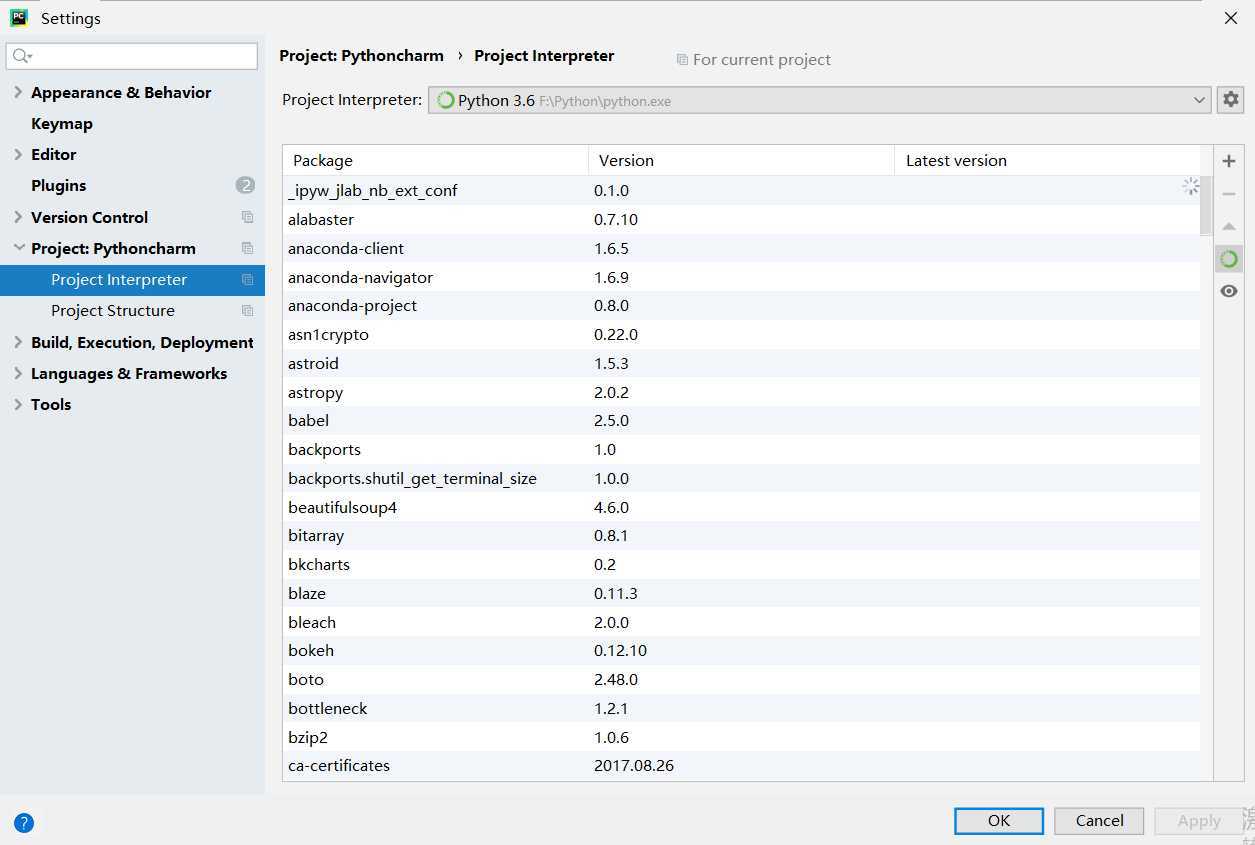
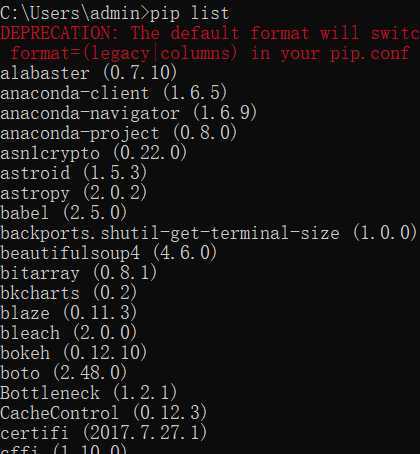
1)贴上Python环境及pip list截图,了解一下大家的准备情况。暂不具备开发条件的请说明原因及打算。

2)贴上视频学习笔记,要求真实,不要抄袭,可以手写拍照。
什么是机器学习:

机器学习一般流程:
![]()
机器学习的一些方法:

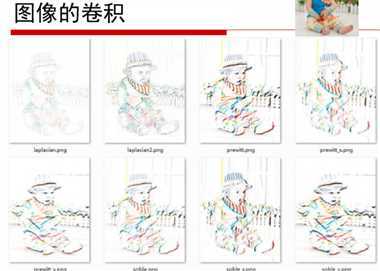
 等等。。。
等等。。。
对于数学知识则讲解了构造数列、自然参数、导数、常用函数的导数、积分应用、Taylor公式-Maclaurin公式、Taylor公式的应用、方向导数、梯度、Γ函数、凸函数、概率论。
3)什么是机器学习,有哪些分类?结合案例,写出你的理解。
机器学习人工智能的一个分支。我们使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式进行学习;随着训练次数的增加,该系统可以在性能上不断学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。
机器学习分类:
1. 监督学习
监督学习是利用已标记的有限训练数据集,通过某种学习策略/方法建立一个模型,实现对新数据/实例的标记(分类)/映射。监督学习要求训练样本的分类标签已知,分类标签的精确度越高,样本越具有代表性,学习模型的准确度越高。监督学习在自然语言处理、信息检索、文本挖掘、手写体辨识、垃圾邮件侦测等领域获得了广泛应用。
监督学习的输入是标注分类标签的样本集,通俗地说,就是给定了一组标准答案。监督学习从这样给定了分类标签的样本集中学习出一个函数,当新的数据到来时,就可以根据这个函数预测新数据的分类标签。
2. 无监督学习
无监督学习是利用无标记的有限数据描述隐藏在未标记数据中的结构/规律。无监督学习不需要训练样本和人工标注数据,便于压缩数据存储、减少计算量、提升算法速度,还可以避免正负样本偏移引起的分类错误问题,主要用于经济预测、异常检测、数据挖掘、图像处理、模式识别等领域,例如组织大型计算机集群、社交网络分析、市场分割、天文数据分析等。
无监督学习与监督学习相比,样本集中没有预先标注好的分类标签,即没有预先给定的标准答案。它没有告诉计算机怎么做,而是让计算机自己去学习如何对数据进行分类,然后对那些正确分类行为采取某种形式的激励。
3. 半监督学习
半监督学习介于监督学习与无监督学习之间,其主要解决的问题是利用少量的标注样本和大量的未标注样本进行训练和分类,从而达到减少标注代价、提高学习能力的目的。
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是该模型首先需要学习数据的内在结构以便合理地组织数据进行预测。
4. 强化学习
强化学习是智能系统从环境到行为映射的学习,以使强化信号函数值最大。由于外部环境提供的信息很少,强化学习系统必须靠自身的经历进行学习。
强化学习的目标是学习从环境状态到行为的映射,使得智能体选择的行为能够获得环境的最大奖赏,使得外部环境对学习系统在某种意义下的评价为最佳。其在机器人控制、无人驾驶、下棋、工业控制等领域获得成功应用。
在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式。在强化学习下,输入数据直接反馈到模型,模型必须对此立刻做出调整。常见的应用场景包括动态系统以及机器人控制等。

原文:https://www.cnblogs.com/rushB/p/12634191.html