------------恢复内容开始------------
Trie树是很神奇的一棵树,一次建树多次使用。
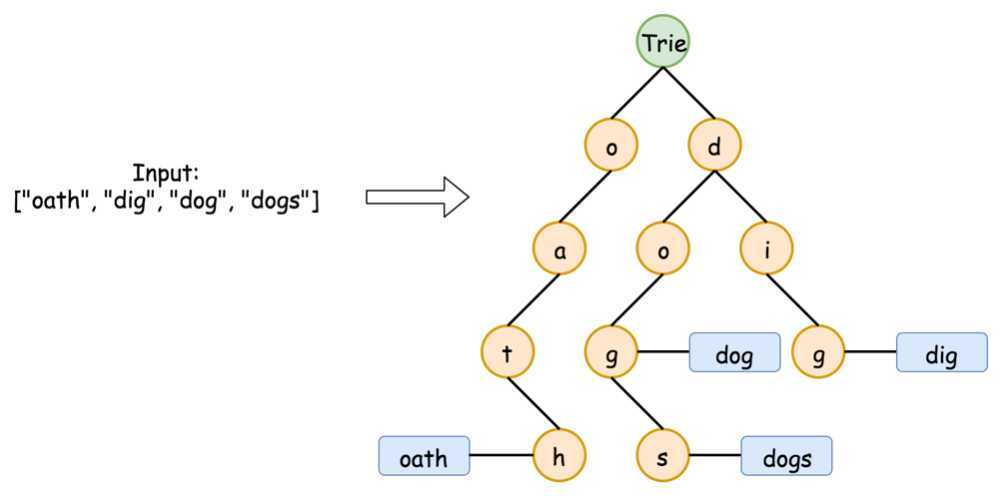
1、每个结点有一个布尔值,标示着是否有以本结点为终止的单词,比如说delete这个单词,到了最后一层的e才可以标true,前面的都是前缀部分,不是完整单词。
2、然后每个结点还有一个数组,里面有26个Trie对象,不存放数据,如果某位置没有实例化对象,就表示没有这个字母,如果有实例化对象,则该对象自己也有一个布尔和26个Trie,就可以继续到这26个里面找对应的位置是否有对象。因为数组对象就是一个地址,而数组[i]就是一个指针指到元素保存的位置上去,指针把字母表连了起来。
说不明白还是盗一张图(力扣上的大佬画的)看看:


因此呢,插入操作就是,先把遍历指针指在第一个结点,然后把字符串分成字符数组,从头开始遍历,如果当前Trie数组的对应位置有实例化就算了,没有就new一下,把当前的遍历指针挪到这个位置上,然后找下一个字母的对应位置。
查找单词呢也是类似的,从根节点开始,要是有结点值为null的就说明到该字母为止就没有了,返回false;要是一直查完了单词里所有字母,就看最后一个字母那里的对象的boolean是否为true,如果是false就说明没有这样的单词,它只是一个前缀而已。如果查找前缀就不用在意该boolean了。
Java代码:
class Trie { private boolean isword=false; Trie[] next=new Trie[26]; /** Initialize your data structure here. */ public Trie() {} /** Inserts a word into the trie. */ public void insert(String word) { Trie cur=this; char[] arr=word.toCharArray(); for(char c:arr){ if(cur.next[c-‘a‘]==null) cur.next[c-‘a‘]=new Trie(); cur=cur.next[c-‘a‘]; } cur.isword=true; } /** Returns if the word is in the trie. */ public boolean search(String word) { Trie cur=this; char[] arr=word.toCharArray(); for(char c:arr){ if(cur.next[c-‘a‘]==null) return false; cur=cur.next[c-‘a‘]; } return cur.isword; } /** Returns if there is any word in the trie that starts with the given prefix. */ public boolean startsWith(String prefix) { Trie cur=this; char[] arr=prefix.toCharArray(); for(char c:arr){ if(cur.next[c-‘a‘]==null) return false; cur=cur.next[c-‘a‘]; } return true; } }
用一个Hard题来练一练手:
给定一个二维网格 board 和一个字典中的单词列表 words,找出所有同时在二维网格和字典中出现的单词。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。
同一个单元格内的字母在一个单词中不允许被重复使用。
输入:
words = ["oath","pea","eat","rain"] and board =
[
[‘o‘,‘a‘,‘a‘,‘n‘],
[‘e‘,‘t‘,‘a‘,‘e‘],
[‘i‘,‘h‘,‘k‘,‘r‘],
[‘i‘,‘f‘,‘l‘,‘v‘]
]
输出: ["eat","oath"]
在这之前还有一个中等题,要求在一个矩阵里找一个单词。常见办法就从矩阵里的每一个位置出发,向上下左右搜索,用递归的方法,返回条件是把给的单词匹配到了最后或者超出了矩阵边界。
这道hard也可以用这样暴力的方法,先从矩阵每个点出发找一遍第一个单词的,再找第二个单词,。。。就是这个过程吧,想想都觉得累。
聪明的话就可以使用我们了不起的Tire树啦!~
1、用给的几个单词构建一个Tire树,一个指针用在矩阵里,一个用在Trie树里;
2、从矩阵的每一个字母开始,看Trie树的当前结点有没有该字母;
3、Trie树里当前结点有这个字母,Trie的指针移到该字母,然后矩阵指针移动到矩阵中该字母上下左右的邻居;
4、再比对Trie树当前结点有没有匹配的,如果有就重复3;如果没有匹配的,或者矩阵里该元素已经匹配过了。
举个栗子,给定的几个单词就像导师,各自有自己的要求(字母的组合),也可能有一些共同的要求(前缀)。每来一个学员组合(矩阵中的字母组成的字符串)导师们会来比较,看符不符合自己的要求,不能符合任意导师的全部要求,就让学员组合及时return,换别组来;只要全部符合其中一位的话那这个学生组合就被收徒(加入结果集)。如果在一个组合里,某学员已经存在了就不能重复加入,因此也要return。比如在矩阵里往右走后又往左走回来,就会重复。
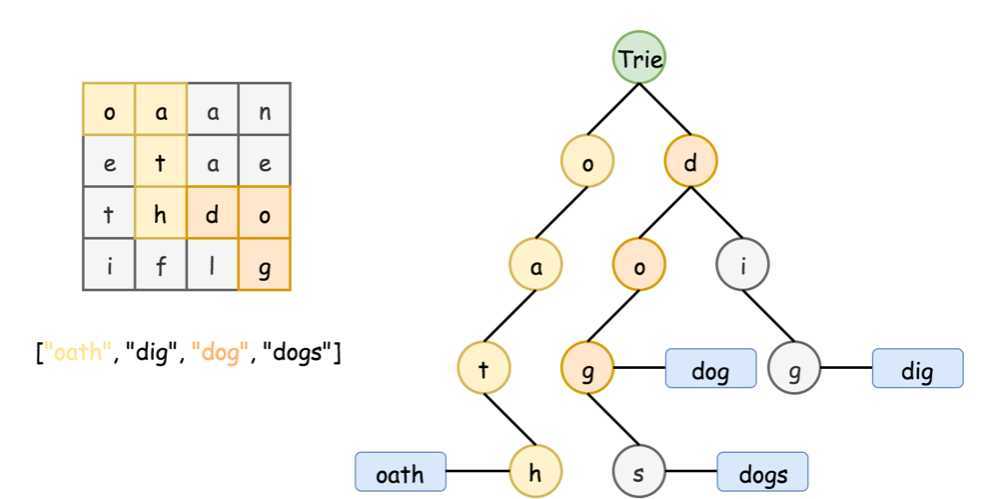
Java代码
class TrieNode{//树的结点 public TrieNode[] next; public String word;//如果是单词的末尾,直接保存该单词 public TrieNode() { next = new TrieNode[26]; word = null; for (int i = 0; i < 26; i++) { next[i] = null; } } } class Trie {//构造一个字典树 public TrieNode root ; public Trie(){ root=new TrieNode(); } public Trie(String[] words){//用传入的字符串数组构造 root=new TrieNode(); for(int i=0;i<words.length;i++){ char[] arr=words[i].toCharArray(); TrieNode cur=root; for(char c:arr){ if(cur.next[c-‘a‘]==null){ cur.next[c-‘a‘]=new TrieNode(); } cur=cur.next[c-‘a‘]; } cur.word=words[i]; } } }; class Solution { public List<String> findWords(char[][] board, String[] words) { Trie trie=new Trie(words); List<String> res = new ArrayList<>(); int rows = board.length; if (rows == 0) { return res; } int cols = board[0].length; for (int i = 0; i < rows; i++) { for (int j = 0; j < cols; j++) { find(board, trie.root, res ,i, j);//每个元素都可以作为起点 } } return res; } public void find(char[][] board,TrieNode root,List<String> res,int i,int j){ if(i<0 || j<0 || i>=board.length || j>=board[0].length )return;//越界返回 char target=board[i][j]; if(target==‘$‘ || root.next[target-‘a‘]==null)return;//已经在本条路上遍历过或者不匹配字典树 TrieNode node=root.next[target-‘a‘]; if(node.word!=null){//到了单词的末尾 res.add(node.word); node.word=null; } board[i][j]=‘$‘;//标记一下本条路线已经走过该点 find(board,node,res,i+1,j); find(board,node,res,i-1,j); find(board,node,res,i,j+1); find(board,node,res,i,j-1); board[i][j]=target;//当回到这里就是该点后的所有情况(上下左右)都走完了 } }
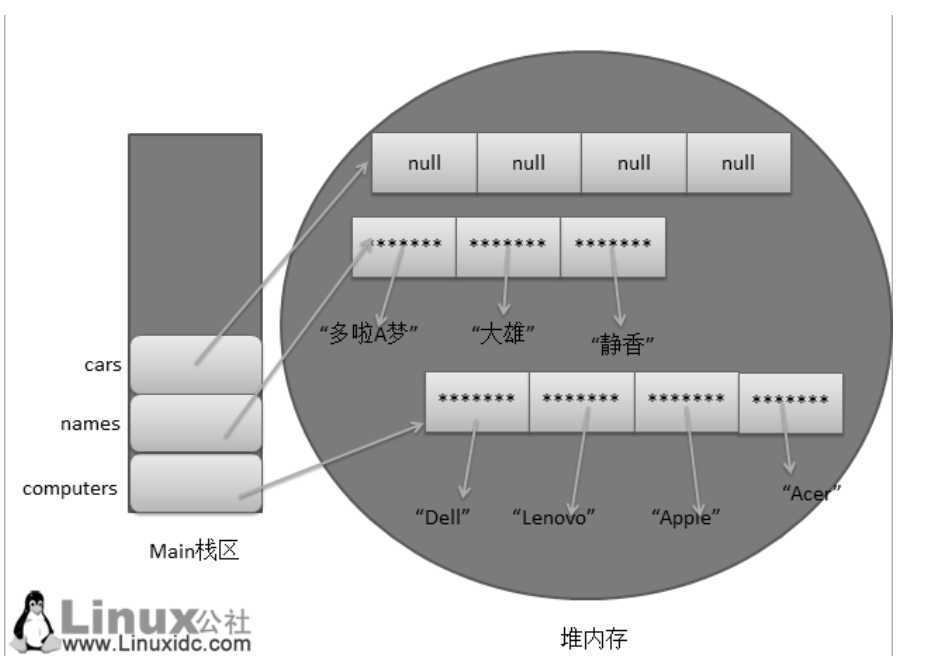
PS:Java里面的数组是怎么保存的?
静态编译:程序员初始化时就给好了值
动态编译:没有赋值,在程序运行中给值
在jvm栈里只保存了一个引用,指向堆里的对象,数组也是对象哦~
如果数组元素不是基本数据类型,那么每个对象又是一个引用,指向字符串常量池中该字符串的位置。
多维数组其实就是一个一位数组,只不过它的每个数组对象都是一个指向另一个数组的引用,也就是保存数组的数组。

------------恢复内容结束------------
原文:https://www.cnblogs.com/zhangmora/p/12633882.html