主要功能包括分词,添加自定义词典,关键词提取,词性标注,并行分词,Tokenize:返回词语在原文的起始位置,命令行分词等功能。
代码对 Python 2/3 均兼容
全自动安装:easy_install jieba 或者 pip install jieba / pip3 install jieba
半自动安装:先下载 http://pypi.python.org/pypi/jieba/ ,解压后运行 python setup.py install
手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
通过 import jieba 来引用
安装完jieba库之后,我们可以利用其来获得文章中的词频。
分析刘慈欣小说《三体》(一二三部合集)出现次数最多的词语。
首先下载好《三体》以txt格式、utf-8编码。导入jieba库:
import jieba
打开文件:
txt = open("santi.txt", encoding="utf-8").read()
使用全模式进行分词,返回列表:
words = jieba.lcut(txt)
定义空集合,并借此进行进行统计:
counts = {}
for word in words:
counts[word] = counts.get(word,0) + 1
dict_items转换为列表,并以第二个元素排序:
items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True)
以格式化打印前30名:
for i in range(30):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
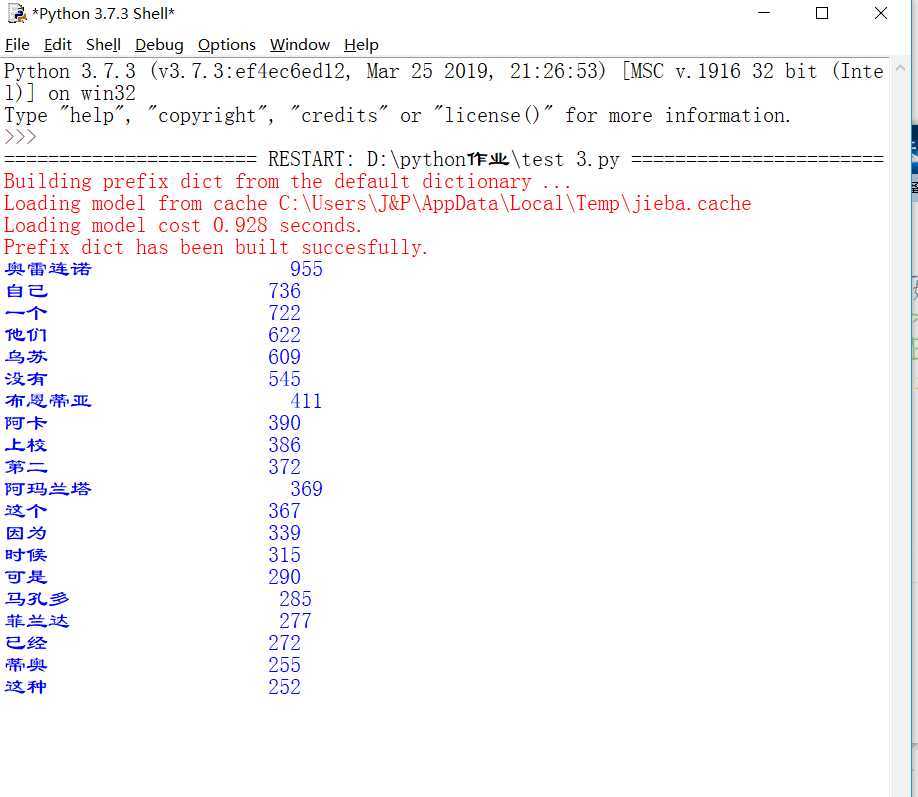
运行结果如下图


from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
def create_word_cloud(filename):
text = open("百年孤独.txt","r",encoding=‘utf-8‘).read() #打开自己想要的文本
wordlist = jieba.cut(text, cut_all=True) # 结巴分词
wl = " ".join(wordlist)
wc = WordCloud( #设置词云
background_color="white", # 设置背景颜色
max_words=20, # 设置最大显示的词云数
font_path=‘C:/Windows/Fonts/simfang.ttf‘, # 索引在C盘上的字体库
height=500,
width=500,
max_font_size=150, # 设置字体最大值
random_state=150, # 设置有多少种随机生成状态,即有多少种配色方案
)
myword = wc.generate(wl) # 生成词云
plt.imshow(myword) # 展示词云图
plt.axis("off")
plt.show()
wc.to_file(‘img_book.png‘) # 把词云保存下
txt=open("百年孤独.txt","r",encoding=‘utf-8‘).read() #打开自己想要的文本
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1: #排除单个字符的分词结果
continue
else :
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(20):
word,count=items[i]
print ("{0:<20}{1:>5}".format(word,count))
if __name__ == ‘__main__‘:
create_word_cloud(‘百年孤独‘) #运行编辑的函数,获得词云

原文:https://www.cnblogs.com/567823a/p/12638413.html