在程序运行的过程中,所有的变量都是在内存中,比如,定义一个dict:
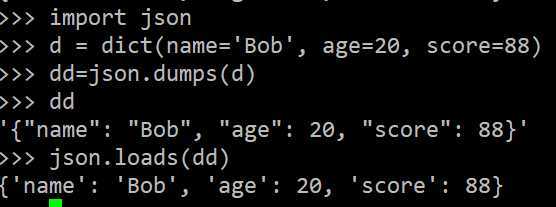
d = dict(name=‘Bob‘, age=20, score=88)
可以随时修改变量,比如把name改成‘Bill‘,但是一旦程序结束,变量所占用的内存就被操作系统全部回收。如果没有把修改后的‘Bill‘存储到磁盘上,下次重新运行程序,变量又被初始化为‘Bob‘。
我们把变量从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
Python提供了pickle模块来实现序列化。

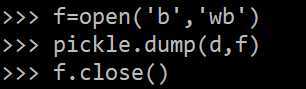
pickle.dumps()方法把任意对象序列化成一个bytes,然后,就可以把这个bytes写入文件。或者用另一个方法pickle.dump()直接把对象序列化后写入一个file-like Object:
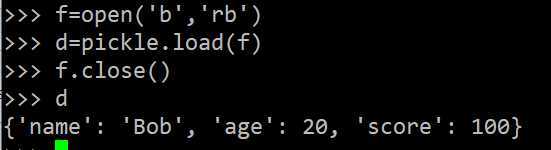
用pickle.loads()方法反序列化出对象,也可以直接用pickle.load()方法从一个file-like Object中直接反序列化出对象
JSON
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
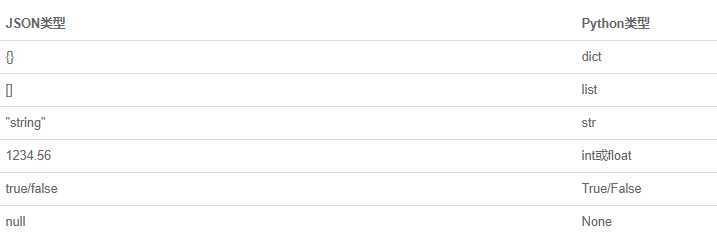
Python内置的json模块提供了非常完善的Python对象到JSON格式的转换

dumps()方法返回一个str,内容就是标准的JSON。类似的,dump()方法可以直接把JSON写入一个file-like Object。
要把JSON反序列化为Python对象,用loads()或者对应的load()方法,前者把JSON的字符串反序列化,后者从file-like Object中读取字符串并反序列化:
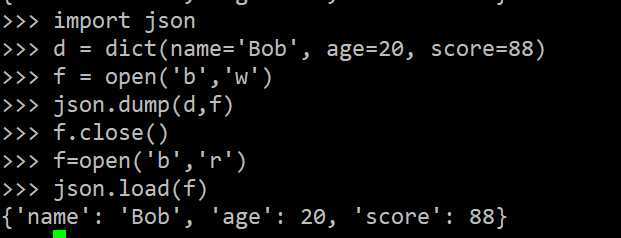
Python的dict对象可以直接序列化为JSON的{},不过,很多时候,我们更喜欢用class表示对象,比如定义Student类,然后序列化:
import json class Student(object): def __init__(self, name, age, score): self.name = name self.age = age self.score = score s = Student(‘Bob‘, 20, 88) print(json.dumps(s)) #TypeError: Object of type Student is not JSON serializable
默认情况下,dumps()方法不知道如何将Student实例变为一个JSON的{}对象。
可选参数default就是把任意一个对象变成一个可序列为JSON的对象,我们只需要为Student专门写一个转换函数,再把函数传进去即可:
def student2dict(std): return { ‘name‘: std.name, ‘age‘: std.age, ‘score‘: std.score } print(json.dumps(s, default=student2dict)) #{"name": "Bob", "age": 20, "score": 88}
原文:https://www.cnblogs.com/soberkkk/p/12639806.html