继续练习写sql, 不能停下来.
今天还额外对 Excel 拼接 sql 语句做了一个代码实现, 逻辑是蛮简单的, 发现其实很多东西都是蛮简单的, 只要一点点去做, 明白逻辑过后, 慢慢去调试, 都是可以弄出来的呀. 这就是解决问题的过程吧, 其实是快乐的, 尤其是当你开始写代码的那一刻, 心里已经想好了, 只是实现而已.
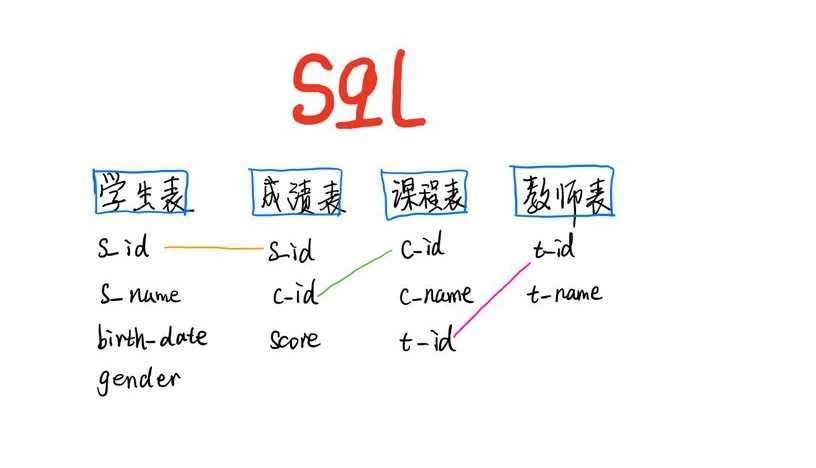
感觉练习上瘾了, 此种有真意哦, 莫非.
查询 两门及其以上, 不及格课程的学生学号, 姓名, 平均成绩
分析
先来看一波, 不及格的信息 从score 中有哪些 s_id.
select s_id from studnet where score < 60;
咱的测试数据是没有符合记录的, 我也懒得加了, 就直接走吧, 关键是理清这个逻辑即可.
然后呢, 然后, 按学号 group by, 组后过滤出, 选课数量大于 2 的哪些 s_id
select s_id from student where score < 60
group by s_id having count(distinct c_id) >= 2;
然后, 拿到学生姓名和平均成绩, 那 学生表 和 成绩表 要 inner join 呀
select
st.s_id as "学号",
st.s_name as "姓名"
from student as st
inner join score as sc
on st.s_id = sc.s_id
-- 满足2门一上的学号(子查询)
where st.s_id in (
select s_id from student where score < 60
group by s_id having count(distinct c_id) >= 2
);
是空的,都不用运行, 测试数据中没有这方面的记录, 脑补一波就好, 不想增加了.
最后是, 平均成绩 要对 s_id 做 group by 了. s_name 也要加上, 不然可能会报错的,因为, s_name 出现在了 select 中, 而并未出现在 group by 中, 这样二者是有问题的. 做了 group by 后, select 只能放跟 group by 中的字段 或者是聚合函数.
select
st.s_id as "学号",
st.s_name as "姓名",
avg(s_score) as "平均成绩"
from student as st
inner join score as sc
on st.s_id = sc.s_id
-- 满足2门一上的学号(子查询)
where st.s_id in (
select s_id from student where score < 60
group by s_id having count(distinct c_id) >= 2
)
group by s_id, s_name;
总体思路, 就是先子查询出, 那些 score < 60 and 选课数 > 2 的这些学号; 最后作为 in.
然后学生表 和 score 做 inner join -> 满足学号的那些记录后, 再进行 group by 学号, 姓名 对 avg(score) 就搞定了.
查询 "0001" 课程 分数小于95按分数降序排列学生的信息
分析
这个就简单了呀. 关联 student 和 score 然后 where 后, order by 即可呀
mysql> select * from score;
+------+------+-------+
| s_id | c_id | score |
+------+------+-------+
| 0001 | 0001 | 80 |
| 0001 | 0002 | 90 |
| 0001 | 0003 | 99 |
| 0002 | 0002 | 60 |
| 0002 | 0003 | 80 |
| 0003 | 0001 | 80 |
| 0003 | 0002 | 80 |
| 0003 | 0003 | 80 |
+------+------+-------+
8 rows in set (0.00 sec)
就是 1, 3 号同学呗.
select
a.*,
b.score
from student as a
inner join score as b
on a.s_id = b.s_id
where
b.c_id = "0001" and b.score < 95
-- 最后再降序按 score
order by b.score;
+------+-----------+------------+--------+-------+
| s_id | s_name | birth_date | gender | score |
+------+-----------+------------+--------+-------+
| 0001 | 王二 | 1989-01-01 | 男 | 80 |
| 0003 | 胡小适 | 1991-12-21 | 男 | 80 |
仔细想想, 平时业务中写的一些 sql 本质上也是这些 学生表, 成绩表 的 join, 子查询 , 过滤, 排序而已, 因此, 掌握这类的思维逻辑, 和写法就已经成功一大半了.
嗯, 我最近反而是一设计多表关联的, 就想写成套娃的形式, 就是很多最后再来一个大括号, 有点像写 Java 那种感觉, 主函数, 然后在私有方法, 变量, 再 子函数... 这样一层层套下去哦.
select * from
(select
a.*,
c_id,
b.score
from student as a
inner join score as b
on a.s_id = b.s_id) as c
where score < 95 and c_id = "0001"
order by score desc;
+------+-----------+------------+--------+-------+
| s_id | s_name | birth_date | gender | score |
+------+-----------+------------+--------+-------+
| 0001 | 王二 | 1989-01-01 | 男 | 80 |
| 0003 | 胡小适 | 1991-12-21 | 男 | 80 |
核心点就是,将最后的输出前的东西, 给拼成一张大表来取字段数据, 这样的好处是, 最后可以不用别名来找字段, 但问题是在拼接的时候, 对于列的选取, 重复列都是好好考虑的点. 想想, 还是别名的方式吧, 这样可能会更加稳一点.
对于这个题, 其是还有种情况, 在做 inner join 的时候, 是将其默认为 1: 1 的关系, 那如果是 1: n 也是可以的. 但如果是 n: n 的关系, 这就不好弄了呀. 就多尝试一下, 没啥问题就这样吧.
以前, 我是新手嘛, 就在 group by 后, 到底 where 放在 group by 之后... 想想都蠢, 根本就没有意义的呀. 慢慢想这个过程, 就大致能理清楚了, 还是要多加练习哦.
原文:https://www.cnblogs.com/chenjieyouge/p/12650124.html