一、设计方案
1、名称:爬取知乎热榜的数据与做数据分析和可视化操作
2、内容:知乎的热门话题前16个,包括它的热度值
3、方案概况:(1)、思路:先去知乎热点网站上查看源代码,找到自己想要的数据和标签,开始动手写爬虫,爬去数据后,建立一个简便的可让人打开的文档或文件夹,
再进行数据的处理,分析,和可视化。完成整个设计
(2)、技术难点 1):分析网页时难以快速且准确的找到自己想要抓取的标签和抓取项目
2):对数据分析理解不够,以至于线性回归方程部分没写
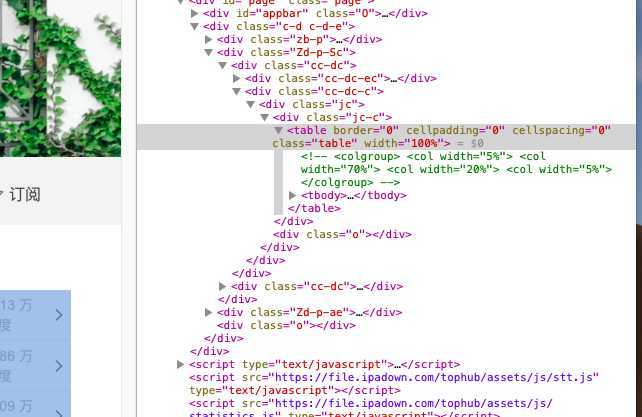
#分析网页源代码
分析得知,所有要抓取的内容均在table标签中
在这个标签中找到需要的内容
二、进行爬虫
#爬去所有需要的数据
url=‘https://tophub.today/n/mproPpoq6O‘
#伪装一个标题,能够爬取内容
headers={‘user-agent‘:‘45545454‘}
#设置延迟
response=requests.get(url,headers=headers,timeout=30)
#获取内容
html=response.text
biaoti=re.findall(‘<a href=.*? target="_blank" .*?>(.*?)</a>‘,html)[3:20]
redu=re.findall(‘<td>(.*?)</td>‘,html)[0:17]
#print(biaoti)
#print(redu)

#让数据更美观和有条理并且创建一个文件夹
#创建字典
dict = {‘内容‘:biaoti,‘阅读数量‘:redu}
x = pd.DataFrame(dict)
#print(x)
dict=[]
for i in range(16):
dict.append([i+1,biaoti[i],redu[i][:-3]])
#建立一个有关文件夹
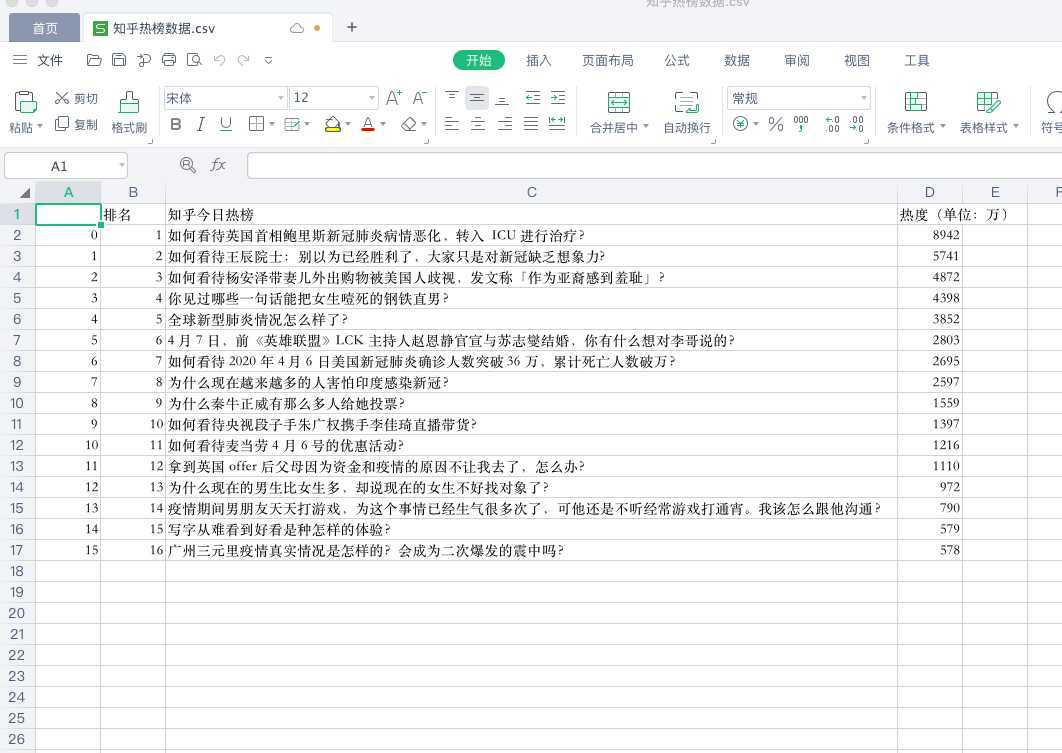
file=pd.DataFrame(dict,columns=[‘排名‘,‘知乎今日热榜‘,‘热度(单位:万)‘])
print(file)
#file.to_csv(‘/Users/xiaonico/Desktop/知乎热榜数据.csv‘)
三、处理文件
对数据的处理
#读取csv文件
df=pd.DataFrame(pd.read_csv(‘/Users/xiaonico/Desktop/知乎热榜数据.csv‘))
df.head()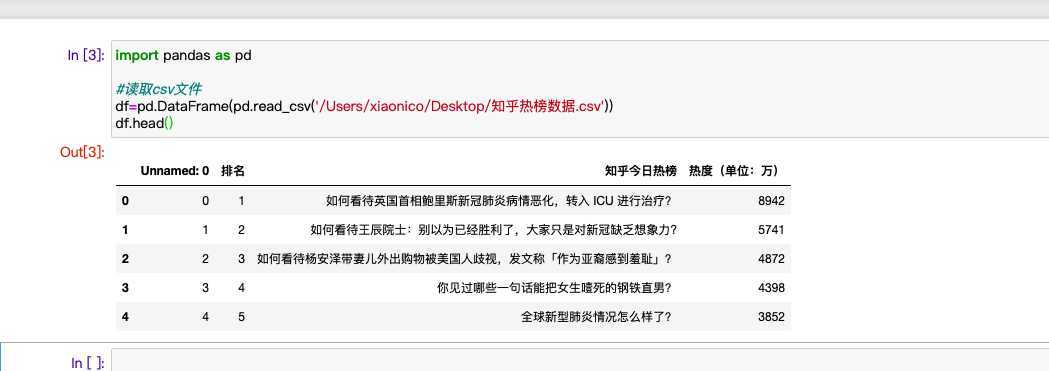
#数据清洗
#进行清洗,去除无效数据
df.drop(‘知乎今日热榜‘,axis=1,inplace=Ture)
df.head()
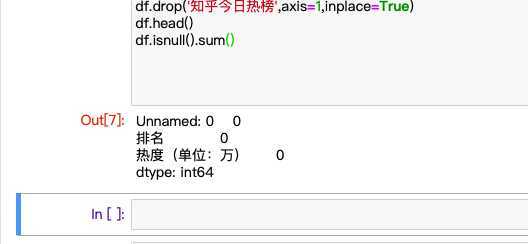
df.isnull().sum()#空值
#缺失值
df[df.isnull().values==True]
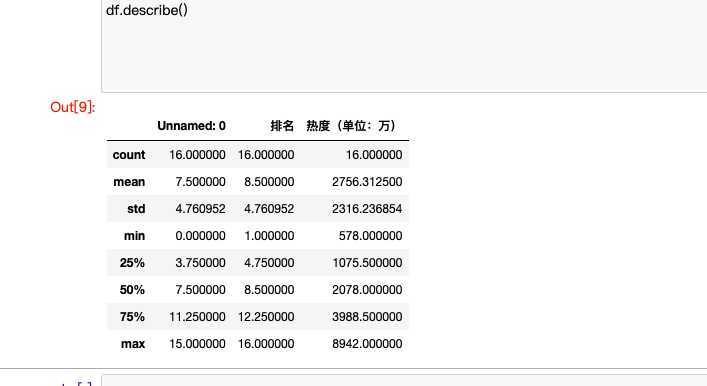
#describe()显示描述性统计指标
df.describe()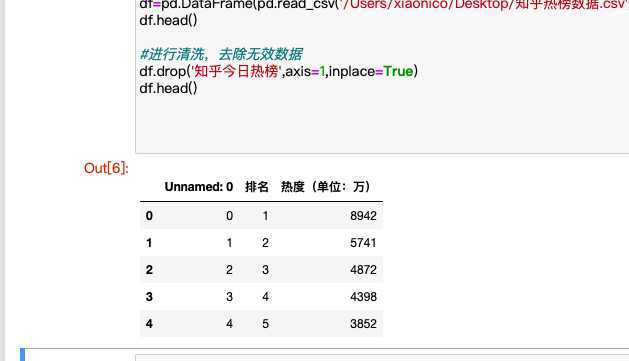

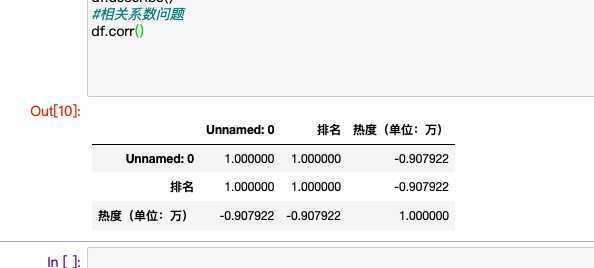
#进行相关数问题
#相关系数问题
df.corr()
四、数据可视化
#排名和热度之间的线性关系
sns.lmplot(x=‘排名‘,y=‘热度(单位:万)‘,data=df)
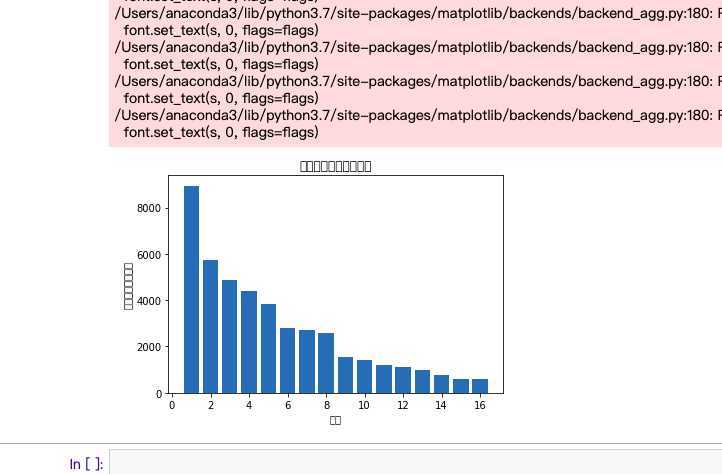
#绘制条形统计图
def build():
file_path = "‘知乎热榜数据.csv‘"
x = df[‘排名‘]
y = df[‘热度(单位:万)‘]
plt.xlabel(‘排名‘)
plt.ylabel(‘热度(单位:万)‘)
plt.bar(x,y)
plt.title("绘制排名与热度条形图")
plt.show()
build()
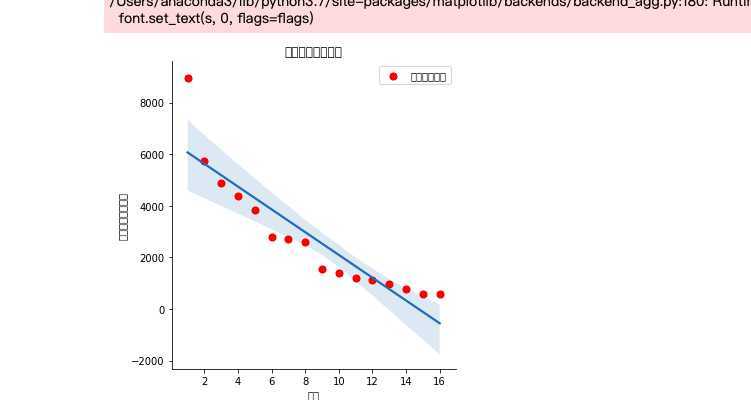
#画散点图
def sandian():
x = df[‘排名‘]
y = df[‘热度(单位:万)‘]
plt.xlabel(‘排名‘)
plt.ylabel(‘热度(单位:万)‘)
plt.scatter(x,y,color="red",label=u"热度分布数据",linewidth=2)
plt.title("排名与热度散点图")
plt.legend()
plt.show()
sandian()
#画折线图
def zhexian():
x = df[‘排名‘]
y = df[‘热度(单位:万)‘]
plt.xlabel(‘排名‘)
plt.ylabel(‘热度(单位:万)‘)
plt.plot(x,y)
plt.scatter(x,y)
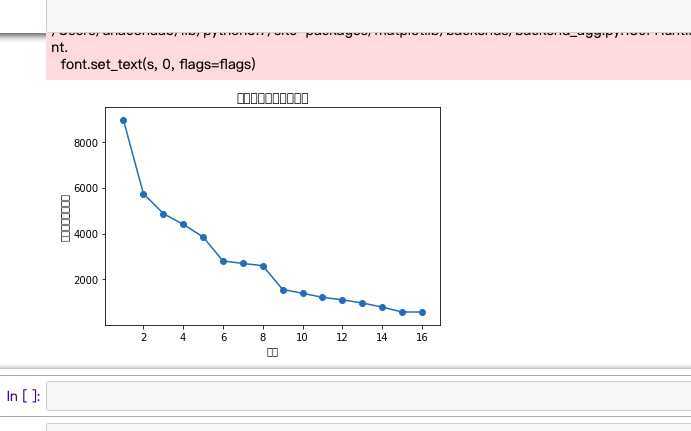
plt.title("排名与热度折线图")
plt.show()
zhexian()
#进行数据的回归方程不会
五、全部代码
#导入需要的库 import requests import re import os import pandas as pd from bs4 import BeautifulSoup import seaborn as sns #一、爬去所有需要的数据 url=‘https://tophub.today/n/mproPpoq6O‘ #伪装一个标题,能够爬取内容 headers={‘user-agent‘:‘45545454‘} #设置延迟 response=requests.get(url,headers=headers,timeout=30) #获取内容 html=response.text biaoti=re.findall(‘<a href=.*? target="_blank" .*?>(.*?)</a>‘,html)[3:20] redu=re.findall(‘<td>(.*?)</td>‘,html)[0:17] #print(biaoti) #print(redu) #print(html) #用bs4对需要的内容进行编辑 soup=BeautifulSoup(html,‘html.parser‘) title=soup.find_all(‘a‘,class_=‘list-title‘) point=soup.find_all(‘align‘,class_=‘inco_rise‘) #print(‘:^55}‘.format(‘知乎热榜川 #print(‘t{:^40}\t{:^10}.format( ‘标题,热度"》 #创建字典 dict = {‘内容‘:biaoti,‘阅读数量‘:redu} x = pd.DataFrame(dict) #print(x) dict=[] for i in range(16): dict.append([i+1,biaoti[i],redu[i][:-3]]) #建立一个有关文件夹 file=pd.DataFrame(dict,columns=[‘排名‘,‘知乎今日热榜‘,‘热度(单位:万)‘]) print(file) #file.to_csv(‘/Users/xiaonico/Desktop/知乎热榜数据.csv‘) #二、对数据的处理 #读取csv文件 df=pd.DataFrame(pd.read_csv(‘/Users/xiaonico/Desktop/知乎热榜数据.csv‘)) df.head() #进行清洗,去除无效数据 df.drop(‘知乎今日热榜‘,axis=1,inplace=Ture) df.head() df.isnull().sum()#空值 #缺失值 df[df.isnull().values==True] #describe()显示描述性统计指标 df.describe() #相关系数问题 df.corr() #三、数据可视化 #排名和热度之间的线性关系 sns.lmplot(x=‘排名‘,y=‘热度(单位:万)‘,data=df) #绘制条形统计图 def build(): file_path = "‘知乎热榜数据.csv‘" x = df[‘排名‘] y = df[‘热度(单位:万)‘] plt.xlabel(‘排名‘) plt.ylabel(‘热度(单位:万)‘) plt.bar(x,y) plt.title("绘制排名与热度条形图") plt.show() build() #画散点图 def sandian(): x = df[‘排名‘] y = df[‘热度(单位:万)‘] plt.xlabel(‘排名‘) plt.ylabel(‘热度(单位:万)‘) plt.scatter(x,y,color="red",label=u"热度分布数据",linewidth=2) plt.title("排名与热度散点图") plt.legend() plt.show() sandian() #画折线图 def zhexian(): x = df[‘排名‘] y = df[‘热度(单位:万)‘] plt.xlabel(‘排名‘) plt.ylabel(‘热度(单位:万)‘) plt.plot(x,y) plt.scatter(x,y) plt.title("排名与热度折线图") plt.show() zhexian()
六、总结:
对于所有的折线图,散点图,和数据分析,可以判断出,排名时随着热度的增长而增长的
小结:
对数据的抓取和分析,还有进行清洗与可视化让我们更加直观的看出来热度标题的数据,能够获取有用的数据,能够画出对于数据的各式图形,
可以让分析更加的快捷和方便,对于有需求的人来说是非常快捷而且方便的。
原文:https://www.cnblogs.com/lnico/p/12655040.html