1)贴上Python环境及pip list截图,了解一下大家的准备情况。暂不具备开发条件的请说明原因及打算。
暂不具备开发环境,人还在老家,电脑没带。过几天就可以回去了。
2)贴上视频学习笔记,要求真实,不要抄袭,可以手写拍照。

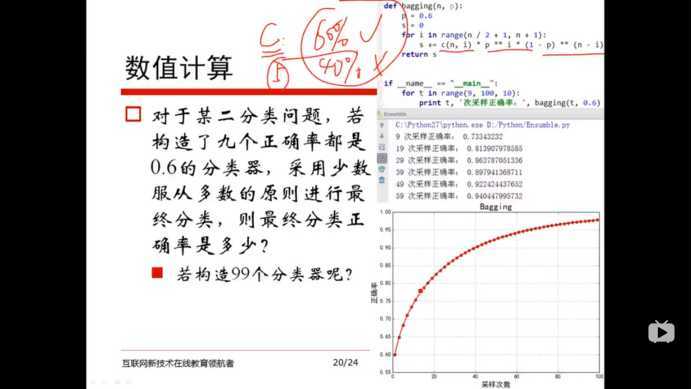
3)什么是机器学习,有哪些分类?结合案例,写出你的理解
机器学习:
机器学习是用机器学习算法来建立模型,当有新的数据过来时,可以通过模型来进行预测。
分类:
有监督式学习:
在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。监督式学习的常见应用场景如分类问题和回归问题。常见算法有逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network)。
无监督式学习:
在无监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法以及k-Means算法。
半监督式学习:
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)等。
强化学习:
在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见的应用场景包括动态系统以及机器人控制等。
原文:https://www.cnblogs.com/zghs/p/12662138.html