引用网上一段话:
\b 是正则表达式规定的一个特殊代码(好吧,某些人叫它元字符,metacharacter),代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是 \b 并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。
如果需要更精确的说法,\b 匹配这样的位置:它的前一个字符和后一个字符不全是(一个是,一个不是或不存在) \w。
很多人不怎么理解正则中的 \b 含义,看到上面一段话后,很多人还是不怎么理解 \b 究竟是怎样的一个“位置”。
今天就来说说我的理解。
什么是位置
It‘s a nice day today.
‘I‘ 占一个位置,‘t‘ 占一个位置,所有的单个字符(包括不可见的空白字符)都会占一个位置,这样的位置我给它取个名字叫“显式位置”。
注意:字符与字符之间还有一个位置,例如 ‘I‘ 和 ‘t‘ 之间就有一个位置(没有任何东西),这样的位置我给它取个名字叫“隐式位置”。
“隐式位置”就是 \b 的关键!通俗的理解,\b 就是“隐式位置”。
此时,再来理解一下这句话:
如果需要更精确的说法,\b 匹配这样的位置:它的前一个字符和后一个字符不全是(一个是,一个不是或不存在) \w。
我用我的话来翻译一下这句话:
“隐式位置” \b,匹配这样的位置:它的前一个“显式位置”字符和后一个“显式位置”字符不全是 \w。
此刻,有没有一种豁然开朗的感觉?有么有?有么有?有么有?
实例讲解
就用 "It‘s a nice day today." 举例说明:
正确的正则:\bnice\b
分析:第一个 \b 前面一个字符是空格,后面一个字符是 ‘n‘,不全是 \w,所以可以匹配出 ‘n‘ 是一个单词的开头。第二个 \b 前面一个字符是 ‘e‘,后面一个字符是空格,不全是 \w,可以匹配出 ‘e‘ 是一个单词的结尾。所以,合在一起,就能匹配出以 ‘n‘ 开头以 ‘e‘ 结尾的单词,这里就能匹配出 "nice" 这个单词。
错误的正则:a\bnice
分析:我见过有人类似于这样来写正则,想要达到的目的是匹配出上一个单词以 ‘a‘ 结尾,下一个单词以 ‘n‘ 开头的部分,这里想匹配出 "a nice"。但是这个正则表达的可不是这个目的,\b 前面是字符 ‘a‘,后面是字符 ‘n‘,两个都是“显式字符”,显然违背了 \b 的含义,所以这就是个错误的表达式,匹配不出任何东西。想要匹配出 "a nice",正确的正则写法是:a\b.\bnice(不能换行)
模式修正符
| 模式修正符 | 描述 |
|---|---|
| re.I | 匹配时忽略大小写 |
| re.M | 多行匹配 |
| re.L | 本地化识别 |
| re.U | unicode |
| re.S | 让.匹配包括多行 |
| \S | 匹配非空白字符 |
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例
#!/usr/bin/python import re print(re.match(‘www‘, ‘www.runoob.com‘).span()) # 在起始位置匹配 print(re.match(‘com‘, ‘www.runoob.com‘)) # 不在起始位置匹配
结果
(0, 3)
None
#!/usr/bin/python3 import re line = "Cats are smarter than dogs" # .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符 matchObj = re.match( r‘(.*) are (.*?) .*‘, line, re.M|re.I) if matchObj: print ("matchObj.group() : ", matchObj.group()) print ("matchObj.group(1) : ", matchObj.group(1)) print ("matchObj.group(2) : ", matchObj.group(2)) else: print ("No match!!")
以上实例执行结果如下:
matchObj.group() : Cats are smarter than dogs matchObj.group(1) : Cats matchObj.group(2) : smarter
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
#!/usr/bin/python3 import re print(re.search(‘www‘, ‘www.runoob.com‘).span()) # 在起始位置匹配 print(re.search(‘com‘, ‘www.runoob.com‘).span()) # 不在起始位置匹配
结果
(0, 3)
(11, 14)
#!/usr/bin/python3 import re line = "Cats are smarter than dogs" searchObj = re.search( r‘(.*) are (.*?) .*‘, line, re.M|re.I) if searchObj: print ("searchObj.group() : ", searchObj.group()) print ("searchObj.group(1) : ", searchObj.group(1)) print ("searchObj.group(2) : ", searchObj.group(2)) else: print ("Nothing found!!")
结果
searchObj.group() : Cats are smarter than dogs searchObj.group(1) : Cats searchObj.group(2) : smarter
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
前三个为必选参数,后两个为可选参数。
#!/usr/bin/python3 import re phone = "2004-959-559 # 这是一个电话号码" # 删除注释 num = re.sub(r‘#.*$‘, "", phone) print ("电话号码 : ", num) # 移除非数字的内容 num = re.sub(r‘\D‘, "", phone) print ("电话号码 : ", num)
以上实例执行结果如下:
电话号码 : 2004-959-559
电话号码 : 2004959559
compile函数用于编译正则表达式,生成一个Pattern对象,Pattern对象有一系列的方法,常用的有:
match(string[, pos[, endpos]])
如果没有指定pos和endpos,默认为0和len(string),即match函数将会从头部(左侧第一个字符)开始进行匹配,若匹配成功将返回Match对象,没有匹配成功,则返回None。
search(string[, pos[, endpos]])
与match的差别是可以从任何地方开始,只要待匹配的字符串中有可匹配对象,就会匹配成功,返回Match对象。也是只匹配一次。
上面的方法只匹配一次,如果我们想把字符串中所有匹配的情况都找出来该怎么办办呢?我们可以使用findall(string,[, pos[, endpos]]),findall会找到所有能够匹配的结果,结果是以列表形式返回的所有子串。
findall中的pattern用小括号,会只返回小括号中的匹配的东西,形成元组列表
import re a = "123abc456899opopo" pat = ‘12(.*?)4(.*?)po‘ res = re.compile(pat).findall(a) print(res)
结果是:
[(‘3abc‘, ‘56899o‘)]
split(string[, maxsplit])
split(string[, maxsplit])
split函数根据能够匹配的子串来分割字符串,结果以列表形式返回。
import re p = re.compile(r‘a‘) res = p.split(‘abcadeacd‘) print(res)
结果是:
[‘‘, ‘bc‘, ‘de‘, ‘cd‘]
‘a’被去除,’a’左右两侧的子串被装进列表中返回。
https://blog.csdn.net/SeeTheWorld518/article/details/49302829
https://www.jianshu.com/p/5ce8100d30a0
ASCII、Unicode和UTF-8的关系
如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
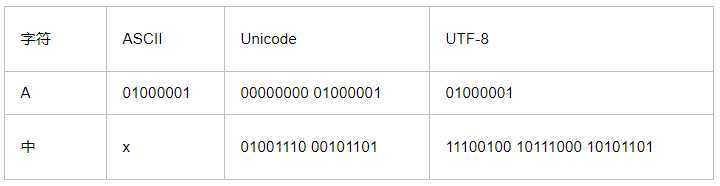
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
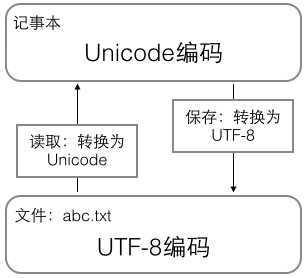
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
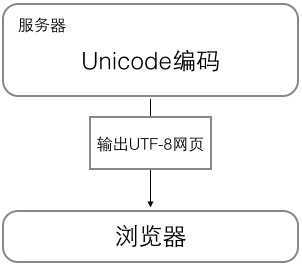
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
Python 3版本中,字符串是以Unicode编码的
>>> ‘\u4e2d\u6587‘ ‘中文‘ >>> ‘中文‘ ‘中文‘
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b‘ABC‘
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> ‘ABC‘.encode(‘ascii‘) b‘ABC‘ >>> ‘中文‘.encode(‘utf-8‘) b‘\xe4\xb8\xad\xe6\x96\x87‘ >>> ‘中文‘.encode(‘ascii‘) Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: ‘ascii‘ codec can‘t encode characters in position 0-1: ordinal not in range(128)
str—>encode()—>byte
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b‘ABC‘.decode(‘ascii‘) ‘ABC‘ >>> b‘\xe4\xb8\xad\xe6\x96\x87‘.decode(‘utf-8‘) ‘中文‘
bytes—>decode()—>str
如果bytes中包含无法解码的字节,decode()方法会报错:
>>> b‘\xe4\xb8\xad\xff‘.decode(‘utf-8‘) Traceback (most recent call last): ... UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xff in position 3: invalid start byte
你眼前看到字符,都是在内存中的,保存到磁盘中的文件只是一堆二进制,在你打开文件的瞬间,这堆二进制进入内存,转为字符呈现在你的眼前。二进制和字符之间显然是有某种规则的,在python3中的规则默认是Unicode。
python 3.x默认的字符编码是unicode,默认的文件编码是utf-8。
在python2文件中,如果你打开一个文件,它默认认为是ASCII编码的,字符编码也是ASCII,它会去直接把那堆二进制去向ASCII匹配,如果有中文根本匹配不到,于是会报错。经常在文件开头看到“ #-*-coding:utf-8 -*- ”语句,它的作用是告诉python解释器此.py文件是utf-8编码,需要用utf-8的编码去读取这个.py文件。
如果是python3文件,你打开一个文件,它默认是utf-8,字符编码是unicode,它会根据utf-8的规则解读这堆二进制,正常解读了就转为遵守Unicode规则的另一堆二进制,然后根据unicode的映射关系就能正常展示在你眼前。
爬虫中经常见到乱码,网站服务器会向你发一堆二进制(bytes),这堆二进制遵守它们的编码规则,如utf-8,而你的python3接收到后总时要转为Unicode后才呈现给你的,如果你不告诉python3接收到的数据使用了什么编码,它就没法进行转换为Unicode的操作,往往会导致乱码。
比如,你好 你收到的是 \xe4\xbd\xa0\xe5\xa5\xbd ,这是utf-8编码,如果被被认为使用ASCII编码,就会用ASCII的方式解读数据去转为Unicode,自然解读不了出错,你要告诉python编码方式是utf-8,encoding就是告诉python使用的编码格式
resp = requests.get(url) resp.encoding = ‘utf-8‘
在python中,把Unicode转为其他编码格式叫编码encode,把其他编码格式转为Unicode叫解码decode
其实不管是Unicode和其他编码都是二进制,编码格式只是规则,但Unicode是默认编码,也就是说如果你的二进制符合Unicode格式他就会在你眼前显示成为字符,字符串都是Unicode,如果其他格式不会以字符的形式显示在你眼前,你可以看它的二进制的形式,如 b‘ \xe4\xbd\xa0\xe5\xa5\xbd‘,你不加b还是Unicode,还是普通字符串。其他编码格式都是bytes。
如,你读取一张图片,要用参数rb,以二进制的形式读,如果你不加,它就用默认的文件存储编码格式给你转Unicode,会出错。
CMD默认是Windows系统默认编码(GBK),你用cmd读取文件的时候,如果用utf-8保存的,打开文件时要设置encoding=utf8。
python3 urllib.request.urlopen()访问HTTPS网站的出错解决办法
使用以下代码:
urllib.request.urlopen(‘https://www.******.org‘)
在请求时会验证证书,没有证书或证书有误会出现:
urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:749)>
发现会报错,当使用urllib模块访问https网站时,由于需要提交表单,而python3默认是不提交表单的,所以这时只需在代码中加上以下代码即可:
import ssl ssl._create_default_https_context = ssl._create_unverified_context
跳过验证证书。
解决pymysql.err.InternalError: (1366, "Incorrect string value: ‘\\xF0\\x9F\\x8C\\xB8‘ for column ‘headline‘ at row 1")
当使用Python对MySQL数据库进行操作时,我们可能会遇到这种错误,这是因为编码所引起的错误,我们必须确保MySQL中的数据库中的编码支持utf8格式,才能将正常的中文格式的字符串插入到MySQL中,我们必须要确保如下character_set_server的格式为utf8,因为将中文插入到MySQL中,主要需要使用的是该驱动
火狐
Firefox全历史版本下载:http://ftp.mozilla.org/pub/mozilla.org//firefox/releases/
驱动geckodriver 下载地址:https://github.com/mozilla/geckodriver/releases/
selenium3.5
firefox 62
火狐关闭自动更新,上面的配置升级到最新版本会报错
linux版
下载依赖
yum install xorg-x11-server-Xvfb bzip gtk3
下载上面版本对应linux的火狐和驱动,解压
root@JD bigdata]# ln -s /bigdata/firefox/firefox /usr/bin/firefox [root@JD bigdata]# ln -s /bigdata/geckodriver /usr/bin/geckodriver
linux下将项目模块搜索路径放到环境变量中去
export PYTHONPATH=$PYTHONPATH:/bigdata/spider/src
原文:https://www.cnblogs.com/aidata/p/12498496.html