一、本文中心内容
神经网络语言模型和词嵌入的经典论文,核心目标是将训练好的word embedding去完成词性标注(POS)、分块(短语识别CHUNK)、命名实体识别(NER)和语义角色标注(SRL)等任务,并且,本网络的语言模型只用来预训练word embedding,然后将其作为具体任务(任务的共同目标是标注)网络第一层(将词的one-hot表示变为word embedding)的参数继续再具体任务中训练。
本文运用到了多任务训练的模型,即共享one-hot到word embedding的转化层的参数,在多项任务上进行训练。统一标注,便于后续介绍,一个具有L层的前向反馈神经网络
本文中的神经网络分为这几个部分:
首先是词向量的构建,将一个词表示为一个向量,即表示为连续空间中的一个点,而不是最原始的one-hot表示。(1)每一个词表示为一个向量存储在表中供查询,lookup table(LW),对于每个词向量为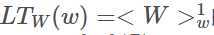 即大表中的第w列。(2)对于任意一个输入序列都可以用一个矩阵表示。(3)对于任何离散型特征可以进行扩展,如果每个词有多个离散特征,则每个离散特征对应一个查表,再将得到的离散特征进行拼接,得到输入矩阵。
即大表中的第w列。(2)对于任意一个输入序列都可以用一个矩阵表示。(3)对于任何离散型特征可以进行扩展,如果每个词有多个离散特征,则每个离散特征对应一个查表,再将得到的离散特征进行拼接,得到输入矩阵。
基于窗口方法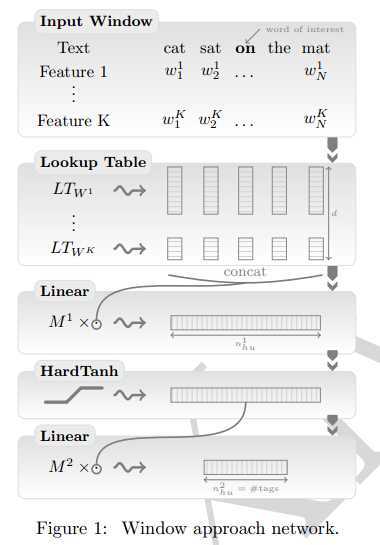
1、第一层,(通过查表操作将这些单词索引中的每一个映射为特征向量)输入层Input window,对于一个输入序列,每一个词对应一个tag并且有一个超参数k,根据特征个数进行查表曹祖,将输入表示为一个矩阵,并且可以拼接为一个固定长度的向量。
2、线性层,也就是第三层,和标注神经网络类似,将输入特征向量进行线性变换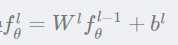
3、非线性变换层:进行hardtanh变换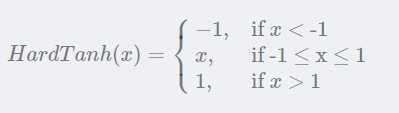
4、线性输出层:根据目标函数进行损失函数选择,一般选择softmax
其他考虑,对于一个长度为T的序列,将会产生T个输入,每一个词组成一个输入。并且窗口k是一个超参数可以采用CV进行选择。另外对于窗口小于k的词,可以添加PADDING词进行代替。该方法能够解决大部分的序列标注问题,但是对于SRL问题,常常需要指定某个谓词作为输入,此时该方法不能适用,需要考虑句子全部特征。
基于句子方法------相比于基于窗口的方法,加入卷积层照顾到全局特征
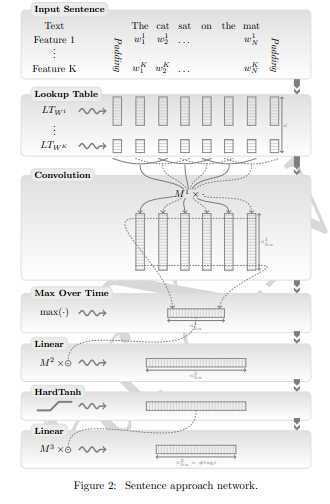
1、与窗口方法不同之处在于,查表定输入的矩阵后,经过一个CONV层,考虑整个句子特征,此时还会加入两个相对特征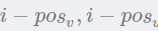 即距离谓词v和待标记词的相对距离。卷积变换为:
即距离谓词v和待标记词的相对距离。卷积变换为: ,得到 t 个卷积结果。最大化层:
,得到 t 个卷积结果。最大化层: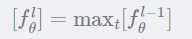 。
。
2、剩余步骤与窗口方法一致。
其次,训练样本时,对每个词求词级别对数似然(WLL),
对每个句子求句子级别对数似然,方法较复杂。再通过SGD进行优化,标准神经网络求解过程BP算法,每一步都是可导的。
二、提高效果手段
输出层采用排序标准而不是基于熵;利用语言模型进行初始化,word embedding过程;多任务学习,多个任务同时学习认为共享中间参数,最后几层作为特定任务的输出;特征字典;级联,将多个学习任务进行串联;模型组合;结构分析-Parsing;固定特征工程。
三、个人总结
1、本文给出了一个统一神经网络架构能够处理多种NLP任务,简单结构能够处理大部分问题,但是效果一般般。
2、句子级别的对数似然复杂度太高,导致训练复杂度很高
3、对于NLP问题来说,一个更好的词嵌入,是成功的一半,在这个时候,word2vec占据半壁江山,词嵌入在任务中的表现一般。
4、卷积模型,获取全局特征,或许在处理中,可以发挥出更好的优势。
5、词嵌入的训练由训练语言模型变成输出评价的分,这个思路值得深究。
第一篇:Natural Language Processing (Almost) from Scratch
原文:https://www.cnblogs.com/xujia-go/p/12667257.html