目标网站:https://so.gushiwen.org/shiwen/default.aspx?
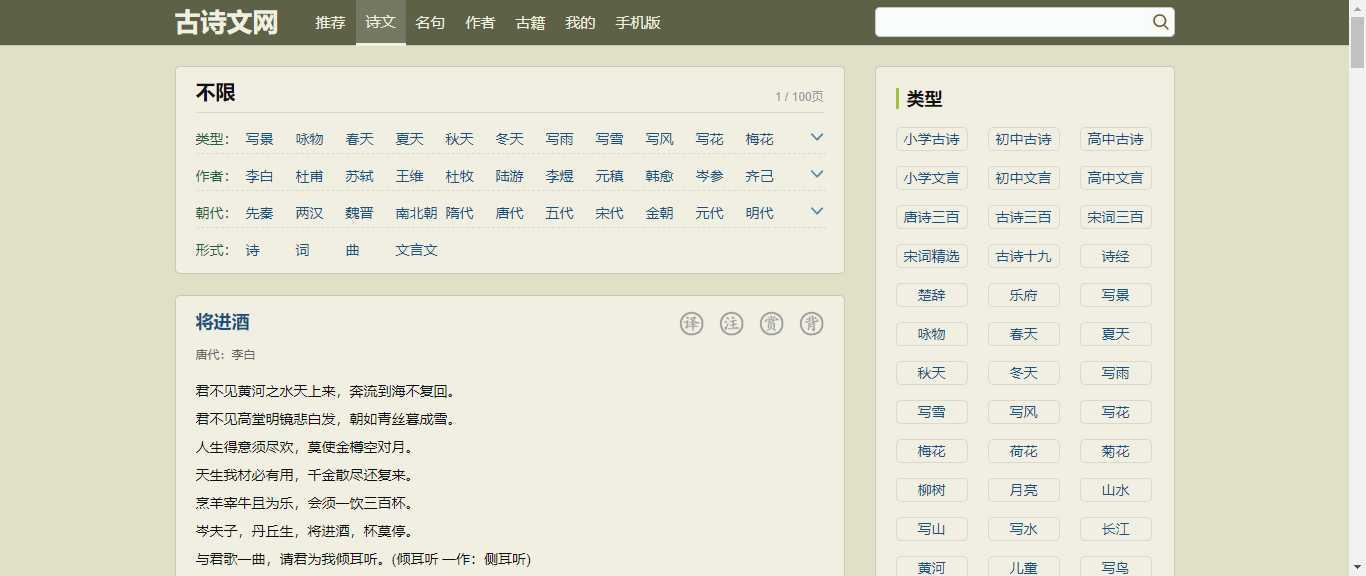
爬取目标网站的文本,如古诗的内容,作者,朝代,并且保存到本地中。

# -*- coding:utf-8 -*- #爬取古诗网站 import requests import re #下载数据 def write_data(data): with open(‘诗词.txt‘,‘a‘)as f: f.write(data) for i in range(1,10): #目标url地址 url = "https://so.gushiwen.org/shiwen/default.aspx?page={}".format(i) headers={‘User-Agent‘: ‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11‘, ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, ‘Accept-Charset‘: ‘ISO-8859-1,utf-8;q=0.7,*;q=0.3‘, ‘Accept-Encoding‘: ‘none‘, ‘Accept-Language‘: ‘en-US,en;q=0.8‘, ‘Connection‘: ‘keep-alive‘} html = requests.get(url ,headers = headers).content.decode(‘utf-8‘) # print(html) p_title = ‘<p><a style="font-size:18px; line-height:22px; height:22px;" href=".*?" target="_blank"><b>(.*?)</b></a></p>‘ title = re.findall(p_title, html) # 提取内容 p_context = ‘<div class="contson" id=".*?">(.*?)</div>‘ context = re.findall(p_context, html, re.S) #提取年代 p_years = ‘<p class="source"><a href=".*?">(.*?)</a>‘ years = re.findall(p_years,html,re.S) #提取作者 p_author = ‘<p class="source"><a href=".*?">.*?</a><span>:</span><.*?>(.*?)</a>‘ author = re.findall(p_author,html) # print(context) # print(title) # print(years) # print(author) for j in range(len(title)): context[j] = re.sub(‘<.*?>‘, ‘‘, context[j]) #‘gbk‘ codec can‘t encode character ‘\u4729‘ ,没有这行会出现报错 context[j] = re.sub(r‘\u4729‘, ‘‘, context[j]) # print(title[j]) # print(years[j]) # print(author[j]) # print(context[j]) #写入数据 write_data(title[j]) write_data(‘\n‘+ years[j]) write_data(‘ :‘+ author[j]) write_data(context[j]) print(‘下载第{}页成功‘.format(str(i)))
本次爬虫难点在于,正则表达式的使用,如使用正则表达式匹配古诗正文、古诗作者、古诗标题。正则表达式的使用,需要找到需要匹配的内容的前项和后项,这样才能精准的定位到需要匹配的内容。如匹配古诗正文:
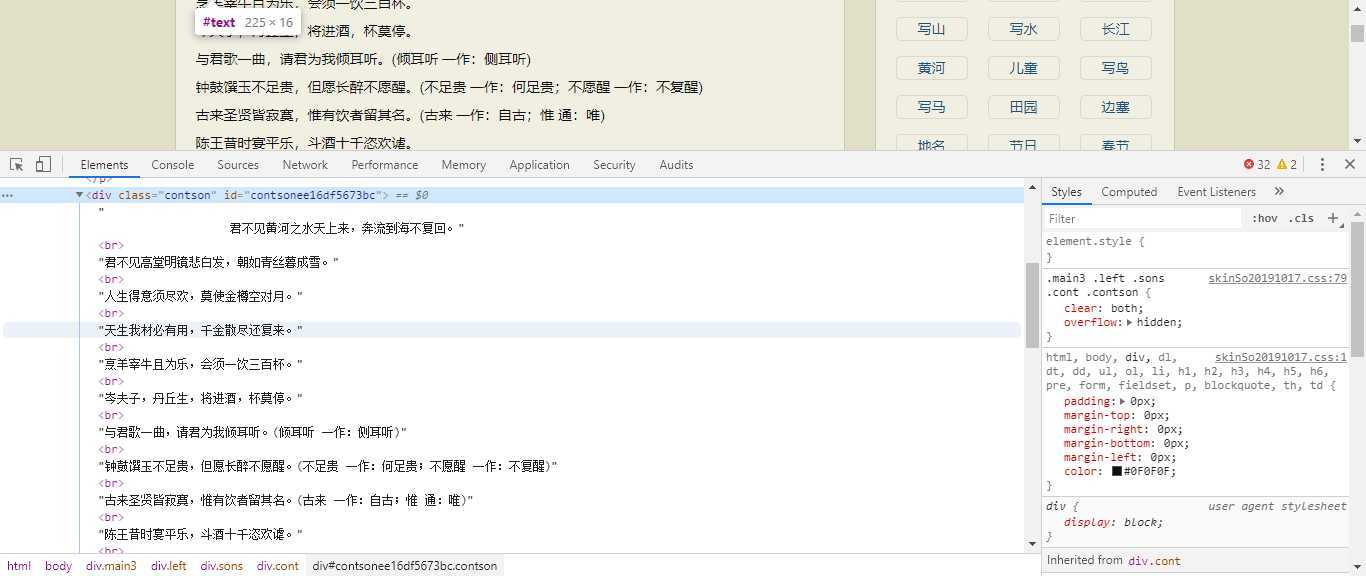
# 提取内容 p_context = ‘<div class="contson" id=".*?">(.*?)</div>‘ context = re.findall(p_context, html, re.S)
需要匹配的内容是括号中的内容,前项是‘<div class="contson" id=".*?">,后项是</div>。这里需要注意的地方有两点,第一:id=”.*?“这里必须使用非贪婪模式,即加上?,如果不加?它会继续匹配下一个内容,这样就无法匹配到我们需要的内容;第二:(.*?)加?这里也使用了非贪婪模式,只匹配括号中的内容一次。而且匹配标题、作者年代、作者姓名,方法都类似,这里就不一一介绍了。
学习笔记(爬虫):爬取古诗网站,获取每一篇古诗,并保存到本地
原文:https://www.cnblogs.com/maxxu11/p/12669005.html