一、论文主要内容
collobert 的那个联合训练,虽然提出了神经网络,但仅仅是一个简单的前向反馈网络,抛弃了上下文长距离的依赖,仅仅依赖与窗口大小之内的单词依赖,其次,由于仅仅依赖于单词嵌入,它无法利用明确的字符级别特征,如前缀和后缀,这可能很有用,特别是在单词嵌入的罕见单词中。
一个新模型:bi-sltm-CNNs;
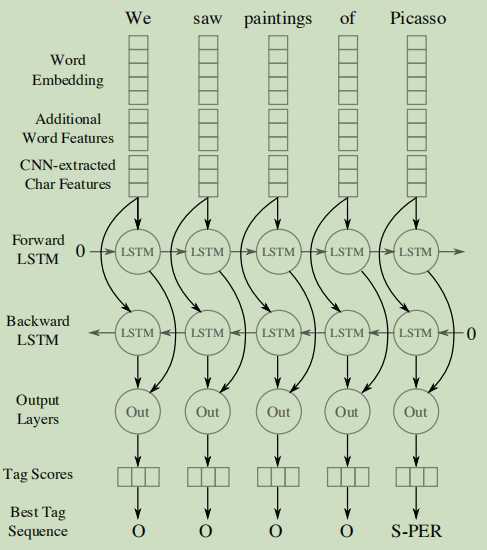
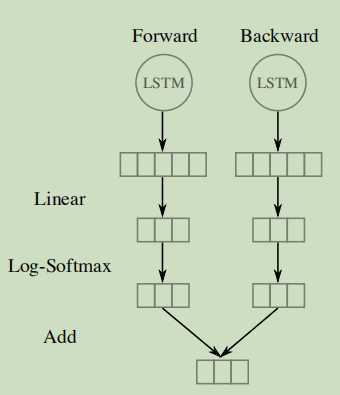
(1)序列标签和双向LSTM:将提取的每个词的特征反馈给前向和后向LSTM网络中,输出层铜线一个线性层和一个log-softmax层将每个时间步长解码为每个标签的对数概率,再将两个向量简单的相加产生最后的输出向量。
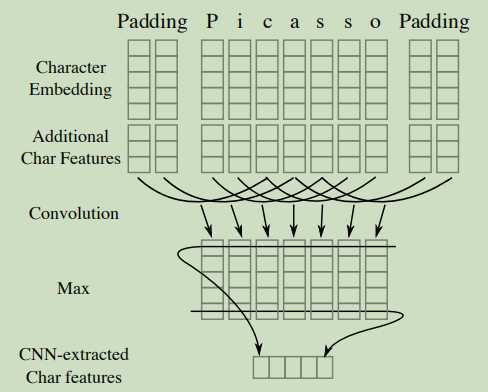
(2)使用CNN提取字符特征:每个词都要经过一个卷积以及一个最大层,从字符嵌入以及附加的特征(比如字符类型)中提取一个新的特征向量。且再字符的两边填充了特殊的padding字符。CNN的窗口大小和输出层向量大小都是超参数。
一个新方法:一种新的神经网络部分词汇匹配编码方法,并将其与现有方法进行了比较
二、模型相关工作----word embedding、character embedding、additional character-level features
附加的字符级特征:大写、小写、标点符号以及其他,词典(词汇特征)
目标函数:
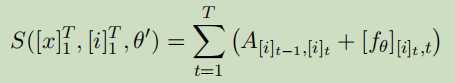
句子级别对数似然,用softmax:
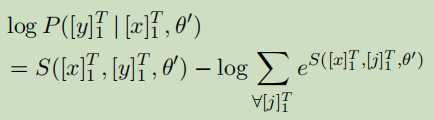
通过梯度下降以及动态规划算法优化, 在推理时,给定神经网络输出[fθ]i,t我们使用Viterbi算法找到标记序列[i]T1,使分数S([x]T1,[i]T1,θ0)最大化。
三、个人想法
1、就前四篇论文来说,最先是传统的神经网络模型与Log-bilinear CRF;其次就是将NER任务优化的模型是一个前向反馈模型加CRF的联合训练模型;再之后就是词嵌入加CRF模型;最后就是这篇双向LSTM加CNN模型,这也是当前最基础的NER任务模型,代码可深入了解;
2、本文,主要是基于句子级别的对数似然进行计算优化,以及添加了附加的特征,当我们使用现在的词向量训练词嵌入时,再加上一些特征工程,应该会比以前的效果好很多,不过此文主要是针对外文,中文的双向LSTM和CRF模型,要另阅读文章。
3、中文的NER任务,主要还是再分词上,词的边界清楚,切分词很正确,加上标注的一些标签,NER任务的完成度会很高的
4、中文中存在很多简写、缩写,这些更需要一个好多模型去学习,但是这些模型学习对了,又会出现过拟合,这是个很难的问题,而且简写的时候还会出现歧义,这是正在研究的一个问题----实体消歧。
5、如果实体消歧也加入人工特征词典,应该也能准确判断,此时重要的有两个点,一个是,人工特征词典是一个泛化的,另一个是,如何将这些加入再实体识别中。
6、基于前几篇文章,实体消歧,最主要的还是先大部分完成准确识别,之后再通过人工特征加入,这样可以进行实体消歧。
第四篇:Named Entity Recognition with Bidirectional LSTM-CNNs
原文:https://www.cnblogs.com/xujia-go/p/12674671.html