2. *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。
3. 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
iris=load_iris()#引入
X=iris.data[:,2]#数据
X=X.reshape(-1,1)
#print("鸢尾花完整数据:\n",X)
from sklearn.cluster import KMeans
est = KMeans(n_clusters=3)#构建模型
est.fit(X)#训练
kc = est.cluster_centers_#聚类中心
y_kmeans = est.predict(X) #预测每个样本的聚类索引
print("最佳聚类中心:\n",kc,"\n预测结果:\n",y_kmeans)
#print(kc.shape,y_kmeans.shape)
#散点图
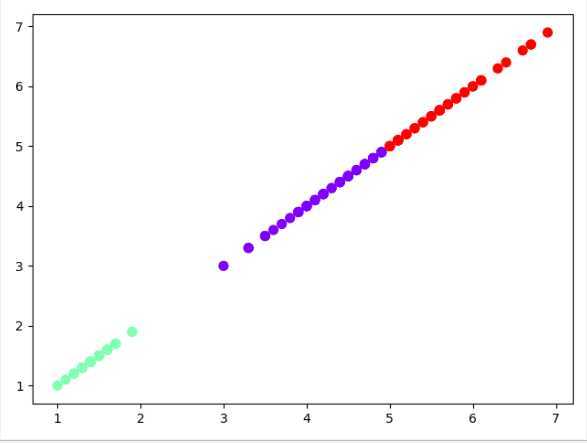
plt.scatter(X[:,0],X[:,0],c=y_kmeans,s=50,cmap=‘rainbow‘)#任意取2列数据作图
plt.show()
运行结果:

4. 鸢尾花完整数据做聚类并用散点图显示.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
iris=load_iris()#引入
X=iris.data#数据
#print("鸢尾花完整数据:\n",X)
from sklearn.cluster import KMeans
est = KMeans(n_clusters=3)#构建模型
est.fit(X)#训练
kc = est.cluster_centers_#聚类中心
y_kmeans = est.predict(X) #预测每个样本的聚类索引
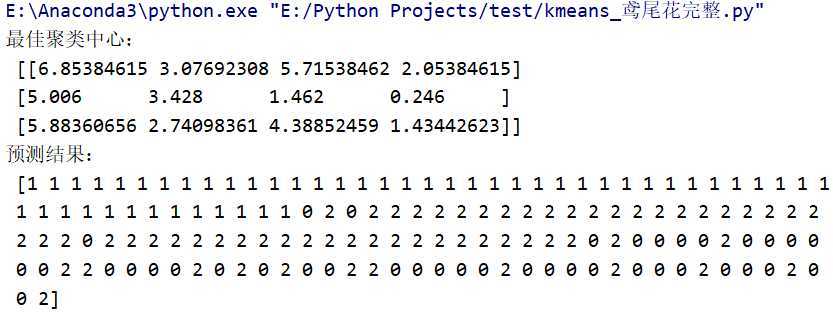
print("最佳聚类中心:\n",kc,"\n预测结果:\n",y_kmeans)
#print(kc.shape,y_kmeans.shape)
#散点图
plt.scatter(X[:,0],X[:,1],c=y_kmeans,s=50,cmap=‘rainbow‘)#任意取2列数据作图
plt.show()
运行结果:

5.想想k均值算法中以用来做什么?
分析各国足球队水平
原文:https://www.cnblogs.com/ray064/p/12693325.html