博主本人热爱学习,读者阅读过程中如果发现有错误的地方或是有更好的实现方式,请与本人联系(qq:1805608587),或是在评论区留言,谢谢!
文章说明:本文是作者原创,请尊重个人劳动成果,转载需注明出处
1.1.划分一个LVM
LVM技术介绍:
名词解释:
PV(Phsical Volume,物理卷),PV是VG的组成部分,有分区构成,多块盘的时候,可以把一块盘格式化成一个主分区,然后用这个分区做成一个PV,只有一块盘的时候,可以这块盘的某一个分区做成一个PV,实际上一个PV就一个分区。
VG(Volume Group, 卷组),有若干个PV组成,作用就是将PV组成到以前,然后再重新划分空间。
LV就是从VG中划分出来的卷,LV的使用要比PV灵活的多,可以在空间不够的情况下,增加空间。
LVM的优点:
卷组VG可以使多个硬盘空间看起来像是一个大硬盘。
1.逻辑卷LV可以创建跨多个硬盘空间的分区。
2.在使用逻辑卷LV时,可以在空间不足时动态调整大小(动态扩容),不需要考虑逻辑卷LV在硬盘上的位置,不用担心没有可用的连续的空间。
3.LVM允许创建快照,用来保存文件系统的备份。
注意:LVM是软件的卷管理方式,RAID是硬件磁盘管理的方法。对于重要的数据使,用RAID保护物理硬盘不会因为故障而中断业务,再用LVM来实现对卷的良性管理,更好的利用硬盘资源。
LVM有两种写入机制:线性(写完一个PV再写下一个PV,默认)、条带(平均)
LVM常用的命令
|
功能 |
PV管理命令 |
VG管理命令 |
LV管理命令 |
|
scan 扫描 |
pvscan |
vgscan |
lvscan |
|
create 创建 |
pvcreate |
vgcreate |
lvcreate |
|
display 显示 |
pvdisplay |
vgdisplay |
lvdisplay |
|
remove 移除 |
pvremove |
vgremove |
lvremove |
|
extend 扩展 |
|
vgextend |
lvextend |
|
reduce 减少 |
|
vgreduce |
lvreduce |
1.1.1磁盘分区
fdisk /dev/sda
1.1.2更新分区表
partprobe /dev/sda
1.1.3创建PV
pvcreate /dev/sda5
1.1.4创建VG
vgcreate vg0 /dev/sda5
vgs
vgdisplay
1.1.5创建LV并格式化
lvcreate -n lv0 -L +1g vg0
mkfs.ext4 /dev/vg0/lv0 --主分区才需要格式化,逻辑分区无法格式化
lvs
lvdisplay
1.1.6挂载磁盘
mount /dev/vg0/lv0 /opt
df -lh
至此,LVM管理完成
1.2.扩容与删除 --原则上不删除和裁剪
1.2.1扩充VG
vgextend vg1 /dev/sda6
1.2.2扩充LV
(LV扩容依赖于VG的容量):
lvextend -L +1g /dev/vg0/lv0
resize2fs /dev/vg0/lv0 (或者xfs_growfs /dev/vg0/lv0 决定于文件系统类型 )
1.2.3移除LV
(先卸载再移除)
lvremove /dev/vg0/lv2
1.2.4移除VG
(先卸载与移除对应的LV)
vgreduce vg1 /dev/sda6
1.2.5移除PV
(先移除对应的LV与VG)
vgreduce /dev/sda6
raid技术介绍:
磁盘阵列(RAID)是利用硬件技术将数个硬盘整合成为一个大硬盘的方法,操作系 统只会看到最后被整合起来的大硬盘。 由于磁盘阵列是由多个硬盘组成,所以可以达成 速度性能、备份等任务。
至少两块磁盘:
raid0:等量模式,100M数据分成50M,数据分别写入硬盘1硬盘2,磁盘写入读取快,但是没有备份功能,一块硬盘损坏直接导致数据丢失
raid1:映象模式,完全备份。100M数据同时写入两块硬盘,可完全备份数据,但是性能上没有任何提高,且有效利用率是1/2
至少三块磁盘(一般用四块硬盘,有一块当备盘):
raid5:有备份功能,任何一块磁盘损坏了(只允许一块硬盘损坏)都可以恢复,提高了读写速度,但是磁盘使用率:2/n
注意:RAID是磁盘管理的方法,LVM是软件的卷管理方式。对于重要的数据使,用RAID保护物理硬盘不会因为故障而中断业务,再用LVM来实现对卷的良性管理,更好的利用硬盘资源。
2.1.raid0
(没有备盘-x选项)
[root@localhost ~]# mdadm -C /dev/md0 -a yes -n 2 -l 0 /dev/sda{5,6}
[root@localhost ~]# mkfs.ext4 /dev/md0
[root@localhost ~]# mdadm -D /dev/md0
2.2.raid1
(没有备盘-x选项)
[root@localhost ~]# mdadm -C /dev/md0 -a yes -n 2 -l 1 /dev/sda{5,6}
[root@localhost ~]# mkfs.ext4 /dev/md0
[root@localhost ~]# mdadm -D /dev/md0
2.3.raid5
2.3.1划分四块raid磁盘
[root@localhost ~]# fdisk /dev/sda
...
Command (m for help): p
/dev/sda5 27258880 27463679 102400 fd Linux raid autodetect
/dev/sda6 27465728 27670527 102400 fd Linux raid autodetect
/dev/sda7 27672576 27877375 102400 fd Linux raid autodetect
/dev/sda8 27879424 28084223 102400 fd Linux raid autodetect
2.3.2更新分区表
[root@localhost ~]# partprobe /dev/sda
2.3.3创建raid5
[root@localhost ~]# yum install -y mdadm-4.1-1.el7.x86_64
[root@localhost ~]# mdadm -C /dev/md0 -a yes -l 5 -n 3 -x 1 /dev/sda{5,6,7,8}
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
注意:
-C表示创建,
-a表示起名为md(0123…),
-l表示创建raid类型为015(本次实验为创建raid5),
-n表示需要三块磁盘(分区),
-x表示需要一块磁(分区)作为备份盘,
/dev/sda{5,6,7,8,}表示指定的分区
2.3.4格式化分区
[root@localhost ~]# mkfs.ext4 /dev/md0
2.3.5创建挂载目录
[root@localhost ~]# mkdir yy
2.3.6挂载raid5
[root@localhost ~]# mount /dev/md0 yy
2.3.7查看挂载信息
[root@localhost ~]# df -lh
Filesystem Size Used Avail Use% Mounted on
tmpfs 98M 0 98M 0% /run/user/0
/dev/md0 186M 1.6M 171M 1% /root/yy
[root@localhost ~]#
使用三块盘(共300M)制作raid5,却只显示186M?这就是raid5的原理,因为raid5的磁盘使用率为n-1/n,还有一块是备用盘(100M),因为还未使用,所以没有占用空间
2.3.8查看当前系统的raid情况
[root@localhost ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sda7[4] sda8[3](S) sda6[1] sda5[0]
200704 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU]
unused devices: <none>
[root@localhost ~]#
其中 sda8[3](S)“S”表示备用盘
2.3.9查看md0属性信息
[root@localhost ~]# mdadm -D /dev/md0
Number Major Minor RaidDevice State
0 8 5 0 active sync /dev/sda5
1 8 6 1 active sync /dev/sda6
4 8 7 2 active sync /dev/sda7
3 8 8 - spare(备用) /dev/sda8
[root@localhost ~]#
2.3.10模拟raid5故障
2.3.11将sda5状态设置为fail
[root@localhost ~]# mdadm /dev/md0 -f /dev/sda5
mdadm: set /dev/sda5 faulty in /dev/md0
[root@localhost ~]#
2.3.12检查磁盘阵列状态
[root@localhost ~]# mdadm -D /dev/md0
Number Major Minor RaidDevice State
3 8 8 0 active sync /dev/sda8
1 8 6 1 active sync /dev/sda6
4 8 7 2 active sync /dev/sda7
0 8 5 - faulty /dev/sda5
发现sda8已经自动顶替sda5(损坏的磁盘),在企业中,发现损坏的磁盘,则使用新磁盘更换即可
将故障盘单独卸载, 等到修复好了以后又可以挂上去^_^
2.3.13卸载raid盘
[root@localhost ~]# mdadm -r /dev/md0 /dev/sda5
mdadm: hot removed /dev/sda5 from /dev/md0
2.3.14挂载raid盘
[root@localhost ~]# mdadm -a /dev/md0 /dev/sda5
mdadm: added /dev/sda5
2.3.15关闭raid
(需要先卸载再关闭)
[root@localhost ~]# umount yy
[root@localhost ~]# mdadm -S /dev/md0
mdadm: stopped /dev/md0
[root@localhost ~]# mdadm -D /dev/md0
mdadm: cannot open /dev/md0: No such file or directory
[root@localhost ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
unused devices: <none>
2.3.16重启raid
[root@localhost ~]# mdadm -A /dev/md0 /dev/sda{5,6,7,8}
在您的系统中添加一个新的分区,并满足一下要求
方法一:
3.1.1新增磁盘
[root@rhcsa ~]# fdisk /dev/sda
Command (m for help): n
Partition type:
p primary (2 primary, 1 extended, 1 free)
l logical (numbered from 5)
Select (default p): l
Adding logical partition 5
First sector (27258880-29353983, default 27258880):
Using default value 27258880
Last sector, +sectors or +size{K,M,G} (27258880-29353983, default 29353983): +512M
Command (m for help): t
Partition number (1-3,5, default 5): 5
Hex code (type L to list all codes): L
Hex code (type L to list all codes): 82
Changed type of partition ‘Linux LVM‘ to ‘Linux swap / Solaris‘
Command (m for help): w
[root@rhcsa ~]# partprobe
3.1.2格式分区
[root@rhcsa ~]# mkswap /dev/sda5
Setting up swapspace version 1, size = 524284 KiB
no label, UUID=b5cb0ecc-5ee9-4191-93dc-a746acfb1971
[root@rhcsa ~]#
3.1.3开启swap
[root@rhcsa ~]# swapon -av /dev/sda5
swapon /dev/sda5
swapon: /dev/sda5: found swap signature: version 1, page-size 4, same byte order
swapon: /dev/sda5: pagesize=4096, swapsize=536870912, devsize=536870912
[root@rhcsa ~]#
3.1.4查看swap:
[root@rhcsa ~]# swapon -s
Filename Type Size Used Priority
/dev/dm-1 partition 3071996 0 -2
/dev/sda5 partition 524284 0 -3
[root@rhcsa ~]#
3.1.5自动挂载:
[root@rhcsa ~]# vim /etc/fstab
UUID="b5cb0ecc-5ee9-4191-93dc-a746acfb1971" swap swap defaults 0 0
验证语法:
[root@rhcsa ~]# mount -a
方法二:
3.1.6关闭swap空间
[root@rhcsa ~]# swapoff -v /dev/VolGroup/LogVol01
3.1.7扩展swap
括展正在使用的swap 分区的逻辑卷设定用作swap 分区的逻辑卷:
[root@rhcsa ~]# lvextend -L +1G /dev/VolGroup/LogVol01
3.1.8格式化新swap空间
[root@rhcsa ~]# mkswap /dev/VolGroup/LogVol01
3.1.9打开swap
[root@rhcsa ~]# swapon -va
3.1.10查看swap
[root@rhcsa ~]# free -lh
total used free shared buffers cached
Mem: 1.0G 842M 159M 2.9M 22M 493M
Low: 1.0G 842M 159M
High: 0B 0B 0B
-/+ buffers/cache: 326M 675M
Swap: 2.0G 0B 2.0G
[root@rhcsa ~]#
方法三
新建swapfile
通过此种方式进行swap 的扩展,首先要计算出block的数目。具体为根据需要扩展的swapfile的大小,以M为单位。block=swap分区大小*1024, 例如,需要扩展64M的swapfile,则:block=64*1024=65536.
然后做如下步骤:
dd if=/dev/zero of=/swapfile bs=1024 count=65536
Setup the swap file with the command:
mkswap /swapfile
To enable the swap file immediately but not automatically at boot time:
swapon /swapfile
To enable it at boot time, edit /etc/fstab to include the following entry:
/swapfile swap swap defaults 0 0
After adding the new swap file and enabling it, verify it is enabled by viewing the output of the command cat /proc/swaps 或者 free.
总结
三种方法都能对swap 分区进行扩展,但是推荐使用第一、二种方法。
mount简介:挂载文件
所谓的“挂载”就是利用一个目录当成进入点,将磁盘分区的数据放置在该目录下; 也就是 说,进入该目录就可以读取该分区的意思。这个动作我们称为“挂载”,那个进入点的目录我们 称为“挂载点”。
参数与选项
显示程序版本
-h:显示辅助讯息
-v:显示较讯息,通常和 -f 用来除错。
-a:将 /etc/fstab 中定义的所有档案系统挂上。
-F:这个命令通常和 -a 一起使用,它会为每一个 mount 的动作产生一个行程负责执行。在系统需要挂上大量 NFS 档案系统时可以加快挂上的动作。
-f:通常用在除错的用途。它会使 mount 并不执行实际挂上的动作,而是模拟整个挂上的过程。通常会和 -v 一起使用。
-n:一般而言,mount 在挂上后会在 /etc/mtab 中写入一笔资料。但在系统中没有可写入档案系统存在的情况下可以用这个选项取消这个动作。
-s-r:等于 -o ro
-w:等于 -o rw
-L:将含有特定标签的硬盘分割挂上。
-U:将档案分割序号为 的档案系统挂下。-L 和 -U 必须在/proc/partition 这种档案存在时才有意义。
-t:指定档案系统的型态,通常不必指定。mount 会自动选择正确的型态。
-o async:打开非同步模式,所有的档案读写动作都会用非同步模式执行。
-o sync:在同步模式下执行。
-o atime、-o noatime:当 atime 打开时,系统会在每次读取档案时更新档案的『上一次调用时间』。当我们使用 flash 档案系统时可能会选项把这个选项关闭以减少写入的次数。
-o auto、-o noauto:打开/关闭自动挂上模式。
-o defaults:使用预设的选项 rw, suid, dev, exec, auto, nouser, and async.
-o dev、-o nodev-o exec、-o noexec允许执行档被执行。
-o suid、-o nosuid:
允许执行档在 root 权限下执行。
-o user、-o nouser:使用者可以执行 mount/umount 的动作。
-o remount:将一个已经挂下的档案系统重新用不同的方式挂上。例如原先是唯读的系统,现在用可读写的模式重新挂上。
-o ro:用唯读模式挂上。
-o rw:用可读写模式挂上。
-o loop=:使用 loop 模式用来将一个档案当成硬盘分割挂上系统。
4.1.fstab
4.1.1创建挂载目录
[root@rhcsa ~]# mkdir /archive -p
4.1.2挂载磁盘
[root@rhcsa ~]# mount /dev/sda3 /archive/
[root@rhcsa ~]# df -lh
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 976M 2.6M 907M 1% /archive
4.1.3卸载磁盘
[root@rhcsa ~]# umount /dev/sda3 /archive/
4.1.4设置自动挂载
[root@rhcsa ~]# vim /etc/fstab
输入:
/dev/sda3 /archive ext4 defaults 0 2
也可以使用UUID:
UUID="41759337-bd73-410c-85a4-18fa6f1eba27" /archive ext4 defaults 0 2
4.1.5检查语法:
[root@rhcsa ~]# mount -a
[root@rhcsa ~]# df -lh
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 976M 2.6M 907M 1% /archive
[root@rhcsa ~]#
4.1.6重启验证:
[root@rhcsa ~]# reboot
[root@rhcsa ~]# df -lh
/dev/sda3 976M 2.6M 907M 1% /archive
4.2.autofs+smb
4.1.7.设置密码文件
mkdir /secure/ -p
vim /secure/sherlock.passwd
输入:
username=tansk
password=123456
挂载验证:
mount -t cifs -o credentials=/secure/sherlock.passwd //192.168.247.59/samba_test /cc
cd /cc
ls
4.1.8.autofs设置
cp -a /etc/auto.misc /etc/auto.aa
vim /etc/auto.master
输入:
/cc /etc/auto.aa
vim /etc/auto.aa
输入:
smb -fstype=cifs,credentials=/secure/sherlock.passwd ://192.168.247.59/samba_test
4.1.9.启动服务验证:
service autofs restart
cd /cc/smb/
ls
4.3.挂载本地光盘
Yum软件仓库的作用是为了进一步简化RPM管理软件的难度以及自动分析所需软件包及其依赖关系的技术。可以把Yum想象成是一个硕大的软件仓库,里面保存有几乎所有常用的工具,而且只需要说出所需的软件包名称,系统就会自动搞定一切。
既然要使用Yum软件仓库,就要先把它搭建起来,然后将其配置规则确定好才行。
4.3.1.编辑配置文件
复制代码
[root@desktop ~]# cd /etc/yum.repos.d/
[root@desktop yum.repos.d]# cat my.repo
[centos7]
name=centos7
baseurl=file:///media/cdrom
gpgcheck=0
enabled=1
[root@desktop yum.repos.d]#
4.3.2.创建挂载目录手动挂载
[root@desktop ~]# mkdir -p /media/cdrom/
[root@desktop ~]# mount -o loop -t iso9660 /dev/cdrom /media/cdrom
4.3.3.测试验证
[root@desktop ~]# yum clean all
[root@desktop ~]# yum makecache
[root@desktop ~]# yum repolist
4.3.4.设置自动挂载
[root@desktop ~]# blkid /dev/cdrom
/dev/cdrom: UUID="2018-11-25-23-54-16-00" LABEL="CentOS 7 x86_64" TYPE="iso9660" PTTYPE="dos"
[root@desktop ~]# echo "UUID=2018-11-25-23-54-16-00 /media/cdrom iso9660 defaults 0 0" >>/etc/fstab
[root@desktop ~]# mount -av
4.4.挂载Windows目录
4.4.1.Windows设置共享文件:
查看共享目录下面的文件:
4.4.2.设置挂载
[root@localhost ~]# yum install cifs-utils -y
[root@localhost ~]# mount -t cifs -o username=Administrator,password=yourpassword //172.16.5.220/test /share
[root@localhost ~]# cd /share/
[root@localhost share]# ll
total 2
-rwxr-xr-x. 1 root root 9 Oct 31 22:32 cc.txt
-rwxr-xr-x. 1 root root 162 Oct 31 22:46 ~$ndowsLinux共享.docx
-rwxr-xr-x. 1 root root 333 Oct 31 22:44 test01.sh
-rwxr-xr-x. 1 root root 0 Oct 31 22:45 WindowsLinux共享.docx
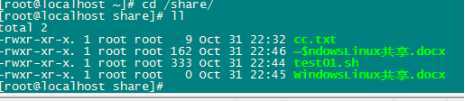
挂载了共享目录,可任意互传。
4.4.3.小结
PS:在两台Linux主机,使用SSH协议,所以可以使用SCP命令,但是Linux和windows在没有工具的情况下,可以使用cifs协议进行通讯的,所以以上方法也是基于cifs协议进行磁盘共享,文件互传。
Linux的设备都是以文件的型态存在, 那分区的文件名又是什么? 如何进行磁盘分区?磁盘分区有哪些限制?目前的 BIOS 与 UEFI 分别是啥?MSDOS 与 GPT 又是啥?
5.1.磁盘的组成
磁盘的组成主要有盘片、机械手臂、磁头与主轴马达所组成, 而数据 的写入其实是在盘片上面。盘片上面又可细分出扇区(Sector)与磁道(Track)两种单位, 其中扇区的物理量设计有两种大小,分别是 512Bytes 与 4KBytes。假设磁盘只有一个盘片, 那么盘片有点像下面这样:
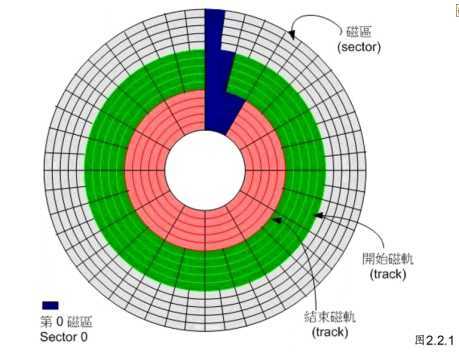
通常磁盘可能有多个盘片,所有盘片的同一 个磁道我们称为柱面 (Cylinder), 通常那是文件系统的最小单位,也就是分区的最小单位 啦!为什么说“通常”呢?因为近来有 GPT 这个可达到 64bit 纪录功能的分区表, 现在我们甚 至可以使用扇区 (sector) 号码来作为分区单位! 所以说,我们就是利用参考对 照柱面或扇区号码的方式来处理啦!
整颗磁盘的第一个扇区特别的重要,因为他记录了整 颗磁盘的重要信息! 早期磁盘第一个扇区里面含有的重要信息我们称为MBR (Master Boot Record) 格式,但是由于近年来磁盘的容量不断扩大,造成读写上的一些困扰, 甚至有些大 于 2TB 以上的磁盘分区已经让某些操作系统无法存取。因此后来又多了一个新的磁盘分区格 式,称为 GPT (GUID partition table)! 这两种分区格式与限制不一样!
第一个扇区(512Bytes)内容只有两个:
MBR(446)+分区表(64)
如果整颗硬盘的第一个扇区(就是MBR与partition table所在的扇区)物理实 体坏掉了,那这个硬盘大概就没有用了! 因为系统如果找不到分区表,怎么知道如何读取柱面区间呢?
分区格式选择:
0-2T MBR,分区最小单位:柱面
>2T GPT(GUID),分区最小单位:扇区
5.2.MBR与GPT分区表
5.2.1.MBR_partition
MBR分区表在磁盘第一个扇区,记录整颗硬盘分区的状态,有64 Bytes。
由于分区表所在区块仅有64 Bytes容量,因此最多仅能有四组记录区,每组记录区记录了该区 段的启始与结束的柱面号码
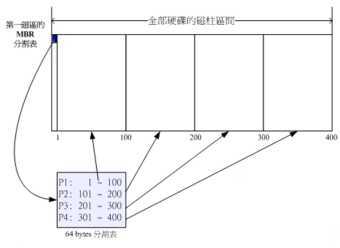
假设上面的硬盘设备文件名为/dev/sda时,那么这四个分区在Linux系统中的设备文件名如下 所示, 重点在于文件名后面会再接一个数字,这个数字与该分区所在的位置有关喔! P1:/dev/sda1
P2:/dev/sda2
P3:/dev/sda3
P4:/dev/sda4
上图中我们假设硬盘只有400个柱面,共分区成为四个分区,第四个分区所在为第301到400 号柱面的范围。 当你的操作系统为Windows时,那么第一到第四个分区的代号应该就是C, D, E, F。当你有数据要写入F盘时, 你的数据会被写入这颗磁盘的301~400号柱面之间的意思。 由于分区表就只有64 Bytes而已,最多只能容纳四笔分区的记录, 这四个分区的记录被称为 主要(Primary)或延伸(Extended)分区。 根据上面的图示与说明,我们可以得到几个重 点信息:
1.其实所谓的“分区”只是针对那个64 Bytes的分区表进行设置而已!
2.硬盘默认的分区表仅能写入四组分区信息 这四组分区信息我们称为主要(Primary)或延伸(Extended)分区 ,延伸分区属于逻辑分区,最多只能有一个(操作系统限制)
3.分区的最小单位“通常”为柱面(cylinder)
4.当系统要写入磁盘时,一定会参考磁盘分区表,才能针对某个分区进行数据的处理
5.逻辑分区内的延伸分区可以重新分割
5.2.2.GPT_partition
因为过去一个扇区大小就是 512Bytes 而已,不过目前已经有 4K 的扇区设计出现!为了相容 于所有的磁盘,因此在扇区的定义上面, 大多会使用所谓的逻辑区块位址(Logical Block Address, LBA)来处理。GPT 将磁盘所有区块以此 LBA(默认为 512Bytes 喔!) 来规划, 而第一个 LBA 称为 LBA0 (从 0 开始编号)
GPT没有逻辑分区的划分,所有分区都是主分区
与 MBR 仅使用第一个 512Bytes 区块来纪录不同, GPT 使用了 34 个 LBA 区块来纪录分区 信息!同时与过去 MBR 仅有一的区块,被干掉就死光光的情况不同, GPT 除了前面 34 个 LBA 之外,整个磁盘的最后 33 个 LBA 也拿来作为另一个备份!这样或许会比较安全些吧! 详细的结构有点像下面的模样:
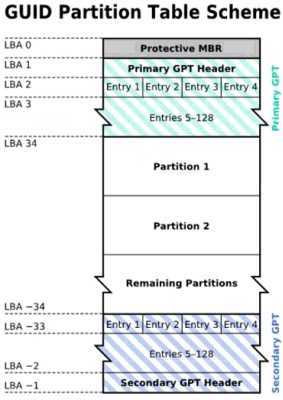
LBA0 (MBR 相容区块):与 MBR 模式相似的,这个相容区块也分为两个部份,一个就是跟之前 446 Bytes 相似的 区块,储存了第一阶段的开机管理程序! 而在原本的分区表的纪录区内,这个相容模式 仅放入一个特殊标志的分区,用来表示此磁盘为 GPT 格式之意。而不懂 GPT 分区表的 磁盘管理程序, 就不会认识这颗磁盘,除非用户有特别要求要处理这颗磁盘,否则该管 理软件不能修改此分区信息,进一步保护了此磁盘喔!
LBA1 (GPT 表头纪录):这个部份纪录了分区表本身的位置与大小,同时纪录了备份用的 GPT 分区 (就是前面谈 到的在最后 34 个 LBA 区块) 放置的位置, 同时放置了分区表的检验机制码 (CRC32),操作系统可以根据这个检验码来判断 GPT 是否正确。若有错误,还可以通 过这个纪录区来取得备份的 GPT(磁盘最后的那个备份区块) 来恢复 GPT 的正常运 行!
LBA2-33 (实际纪录分区信息处):从 LBA2 区块开始,每个 LBA 都可以纪录 4 笔分区纪录,所以在默认的情况下,总共可 以有 432 = 128 笔分区纪录喔!因为每个 LBA 有 512Bytes,因此每笔纪录用到 128 Bytes 的空间,除了每笔纪录所需要的识别码与相关的纪录之外,GPT 在每笔纪录中分 别提供了 64bits 来记载开始/结束的扇区号码,因此,GPT 分区表对於单一分区来说, 他的最大容量限制就会在“ 264 512Bytes = 263 1KBytes = 233TB = 8 ZB ”,要注意 1ZB = 230TB 啦! 你说有没有够大了?
5.2.3.BIOS与UEFI
虽然新版的 Linux 大多认识了 GPT 分区表,没办法,我们 server 常常需要比较大容量的磁盘 嘛!不过,在磁盘管理工具上面, fdisk 这个老牌的软件并不认识 GPT 喔!要使用 GPT 的 话,得要操作类似 gdisk 或者是 parted 指令才行!。 开机管理程序方面, grub 第一版并不认识 GPT 喔!得要 grub2 以后才会认识的!
并不是所有的操作系统都可以读取到 GPT 的磁盘分区格式!同时,也不是所有的硬件都可 以支持 GPT 格式!是否能够读写 GPT 格式又与开机的检测程序有关! 那开机的检测程序 又分成啥鬼东西呢?就是 BIOS 与 UEFI 。
操作系统也是软件,那么我的计算机又是如何认识这个操作系 统软件并且执行他的? 明明开机时我的计算机还没有任何软件系统,那他要如何读取硬盘内 的操作系统文件啊?嘿嘿!这就得要牵涉到计算机的开机程序了!
CMOS是记录各项硬件参 数且嵌入在主板上面的储存器,BIOS则是一个写入到主板上的一个固件(再次说明, 固件就 是写入到硬件上的一个软件程序)。这个BIOS就是在开机的时候,计算机系统会主动执行的 第一个程序了!
接下来BIOS会去分析计算机里面有哪些储存设备,我们以硬盘为例,BIOS会依据使用者的设置去取得能够开机的硬盘, 并且到该硬盘里面去读取第一个扇区的MBR位置。 MBR这个仅 有446 Bytes的硬盘容量里面会放置最基本的开机管理程序, 此时BIOS就功成圆满,而接下 来就是MBR内的开机管理程序的工作了。
这个开机管理程序(MBR内含的:boot loader))的目的是在载入(load)核心文件, 由于开机管理程序是操作系统在安装 的时候所提供的,所以他会认识硬盘内的文件系统格式,因此就能够读取核心文件, 然后接 下来就是核心文件的工作,开机管理程序与 BIOS 也功成圆满,将之后的工作就交给大家所 知道的操作系统啦!
简单的说,整个开机流程到操作系统之前的动作应该是这样的:
1. BIOS:开机主动执行的固件,会认识第一个可开机的设备;
2. MBR:第一个可开机设备的第一个扇区内的主要开机记录区块,内含开机管理程序;
3. 开机管理程序(boot loader):一支可读取核心文件来执行的软件;
4. 核心文件:开始操作系统的功能...
注意:如果你的分区表为 GPT 格式的话,那么 BIOS 也能够从 LBA0 的 MBR 相容 区块读取第一阶段的开机管理程序码, 如果你的开机管理程序能够认识 GPT 的话,那么使用 BIOS 同样可以读取到正确的操作系统核心喔!换句话说, 如果开机管理程序不懂 GPT ,例 如 Windows XP 的环境,那自然就无法读取核心文件,开机就失败了!
boot loader的主要任务有下面这些项目:
1.提供菜单:使用者可以选择不同的开机项目,这也是多重开机的重要功能!
2.载入核心文件:直接指向可开机的程序区段来开始操作系统;
3.转交其他loader:将开机管理功能转交给其他loader负责。--Linux多个内核的时候是不是可以选择核心开机?就是那么一回事。
开机 管理程序除了可以安装在MBR之外, 还可以安装在每个分区的开机扇区(boot sector),假设你的个人计算机只有一个硬盘,里面切成四个分区,其中第一、 二分区分别安装了Windows及Linux, 你要如何在开机的时候选择用Windows还是Linux开机 呢?假设MBR内安装的是可同时认识Windows/Linux操作系统的开机管理程序, 那么整个流 程可以图示如下:
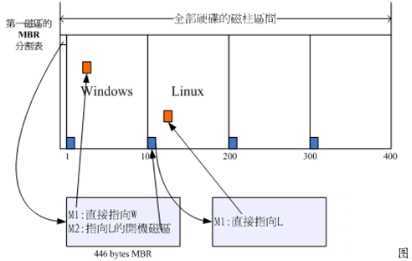
MBR的开机管理程序提供两个菜单,菜单一(M1)可以直接载入 Windows的核心文件来开机; 菜单二(M2)则是将开机管理工作交给第二个分区的开机扇区 (boot sector)。当使用者在开机的时候选择菜单二时, 那么整个开机管理工作就会交给第 二分区的开机管理程序了。
1.每个分区都拥有自己的开机扇区(boot sector)
2.图中的系统盘为第一及第二分区, 实际可开机的核心文件是放置到各分区内的!
3.loader只会认识自己的系统盘内的可开机核心文件,以及其他loader而已;
4.loader可直接指向或者是间接将管理权转交给另一个管理程序。
那现在请你想一想,为什么人家常常说:“如果要安装多重开机, 最好先安装Windows再安装 Linux”呢?这是因为:
Linux在安装的时候,你可以选择将开机管理程序安装在MBR或各别分区的开机扇区, 而 且Linux的loader可以手动设置菜单(就是上图的M1, M2...),所以你可以在Linux的boot loader里面加入Windows开机的选项; Windows在安装的时候,他的安装程序会主动的覆盖掉MBR以及自己所在分区的开机扇 区,你没有选择的机会, 而且他没有让我们自己选择菜单的功能。
因此,如果先安装Linux再安装Windows的话,那MBR的开机管理程序就只会有Windows的项 目,而不会有Linux的项目 (因为原本在MBR内的Linux的开机管理程序就会被覆盖掉)。 那 需要重新安装Linux一次吗?当然不需要,你只要用尽各种方法来处理MBR的内容即可。 例如 利用Linux的救援模式来挽救MBR啊!
我们现在知道 GPT 可以提供到 64bit 的寻址,然后也能够使用较大的区块来处理开机管理程 序。但是 BIOS 其实不懂 GPT !还得要通过 GPT 提供相容模式才能够读写这个磁盘设备 ~而且 BIOS 仅为 16 位的程序,在与现阶段新的操作系统接轨方面有点弱掉了! 为了解决这 个问题,因此就有了 UEFI (Unified Extensible Firmware Interface) 这个统一可延伸固件界 面的产生。
UEFI 主要是想要取代 BIOS 这个固件界面,因此我们也称 UEFI 为 UEFI BIOS 就是了。 UEFI 使用 C 程序语言,比起使用组合语言的传统 BIOS 要更容易开发!也因为使用 C 语言 来撰写,因此如果开发者够厉害,甚至可以在 UEFI 开机阶段就让该系统了解 TCP/IP 而直接 上网! 根本不需要进入操作系统耶!这让小型系统的开发充满各式各样的可能性!
5.2.4.分区的好处
数据的安全性: 因为每个分区的数据是分开的!所以,当你需要将某个分区的数据重整 时,可以将其他重要数据移 动到其他分区。
提高系统的性能: 由于分区将数据集中在某个柱面的区段,假设当中第一个分区位 于柱面号码1~100号,如此一来当有数据要读取自该分区时, 磁盘只会搜寻前面1~100的 柱面范围,由于数据集中了,将有助于数据读取的速度与性能。
原文:https://www.cnblogs.com/tanshouke/p/12699682.html