2455字,推荐阅读时间10~15分钟。这一部分不对自动化测试的普适定义做过多探讨,即文章不展开所有的命令行的使用和函数调用。主要聚焦于本单元评测机的评判机制和具体实现。
话不多说,下面正式开始介绍一种可能的评测机实现方式。
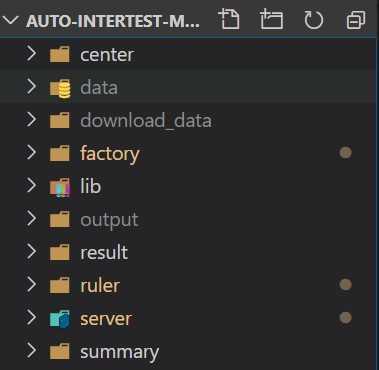
center:存放评测的核心控制代码,用于组织编译->运行->反馈功能data:存放自动生成的数据download_data:存放测试中出现问题的数据,可以用于回归测试。factory:存放数据生成代码lib:存放JAR包output:存放各个测试代码的输出result:存放各个测试代码的结果ruler:存放标程或评测逻辑(即spj的逻辑判断代码)server:用于适配服务器端的调用代码summary:用于存放反馈整合后的结果(在调优部分会提及)根据指导书的提示和合理外推,可以归纳出以下不少的判断规则:
A:
电梯载客时电梯内人数不能超出电梯容量6人
相邻arrive的间隔大于等于0.4s
只能在-3 -2 -1 1 15~20楼层停靠
B:
电梯载客时电梯内人数不能超出电梯容量8人
相邻arrive的间隔大于等于0.5s
只能在-2 -1 1 2 4~15楼层停靠
C:
电梯载客时电梯内人数不能超出电梯容量7人
相邻arrive的间隔大于等于0.6s
只能在1 3 5 7 9 11 13 15楼层停靠
电梯每次移动距离为1(Arrive是连续的,不允许出现跳跃)
电梯不能到达无法到达的楼层
电梯开门时门必须是关闭状态
电梯停下后才可以在对应楼层开门
电梯关门时门必须是打开状态
电梯关门后才可以继续移动
电梯开关门速度不能超出限制
一对开关的楼层必须相同
程序结束后所有电梯门必须为关闭状态
电梯装卸乘客时门必须是开启状态
电梯装卸乘客时乘客必须在当前楼层等待
电梯载客时乘客必须在门外
电梯卸客时乘客必须在电梯上
程序结束后所有乘客必须抵达目的地
被拆解的请求要检查每一个分请求是否得到满足
在上个单元中,每次互测时为了能够使用命令行直接编译出可运行的.class文件,评测机采用的都是即刻编译、即刻运行的工作逻辑。但是有感于大家的创造力,(每个人的主类命名都不一样,再来个便想到了调用package的话,就更棒了)JAR包的方法——这是真正意义上的“黑箱”测试,因为不需要为了命令行的参数修改任何一份代码的主类。
关于JAR的生成,可以参考网上的教程,win和linux端都有。
生成好之后,就可以统一运行所有的代码了。
java -jar xxx.jar
这命令行有没有很熟悉?
计组的Mars不就是这样用的吗
这一部分其实就是读文档+if判断,大家都知道,就不赘述了。
既然在学Java多线程,那为什么不顺手用用Python多线程呢?(虽然没有因果关系)
subprocess()模块就是Python最亲民的一种启动多线程方式,其他类似Java的创建特殊类的办法在这里并没有用武之地,杀鸡焉用牛刀,最适合的才是最好的。
from subprocess import Popen
elev_proc = Popen(r‘java -jar xxx.jar‘,
stdin=PIPE,
stdout=f_out,
stderr=f_out,
shell=True
)
注意到参数列表中的stdin,stdout,stderr其实是在重定向线程的输出流,便于后期的分析。最后的shell=True是为了适配Linux加上的,这里在调优部分会体现出来。
关于flush等评论区已经有讨论结果的操作,就不在此详述了。
可以类似中断机制一样建立一个中断向量表,发现问题直接中断评测程序,根据中断号返回相应的原因。这对黑盒测试后的修正工作是有非常大的帮助的。
首先,请允许我对直接用线性规划等其他数学工具推导最优解的朋友致以崇高的敬意。
但是
重要的事说三遍:
这一部分没有理论推导!
这一部分没有理论推导!
这一部分没有理论推导!
为什么呢?
因为找到的最优策略不是算出来的,是进化出来的。
“在数学的天地里,重要的不是我们知道什么,而是我们怎么知道什么.” ——毕达哥拉斯
最吸引我们的当然是这最优解到底是什么,但是,“怎么知道它”在不知道它之前比它到底是什么更加重要。(告诉我你没有没绕晕)
能让计算机的计算功能为我们所用的时候请千万不要吝啬,因为面前的i7可以匹敌几千万个你的计算速度。
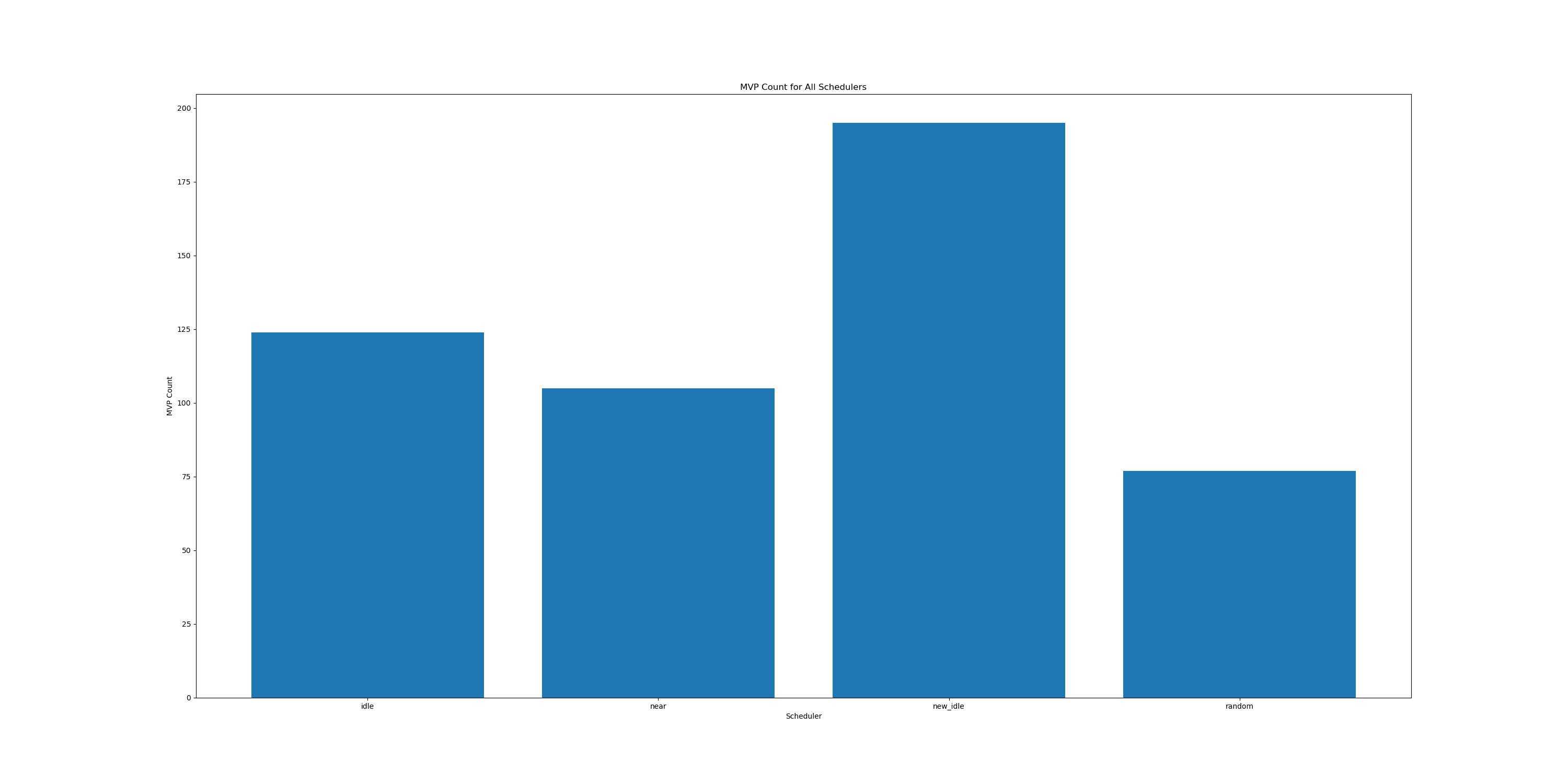
先给大家展示最后用于分析的可视化结果(出于博客的观看体验考虑,只展示四种调度算法的结果)
运行时间走势
在所有数据里取得最优解的次数
平均调度时间及其方差和标准差(标准差在该情境下和方差等价)
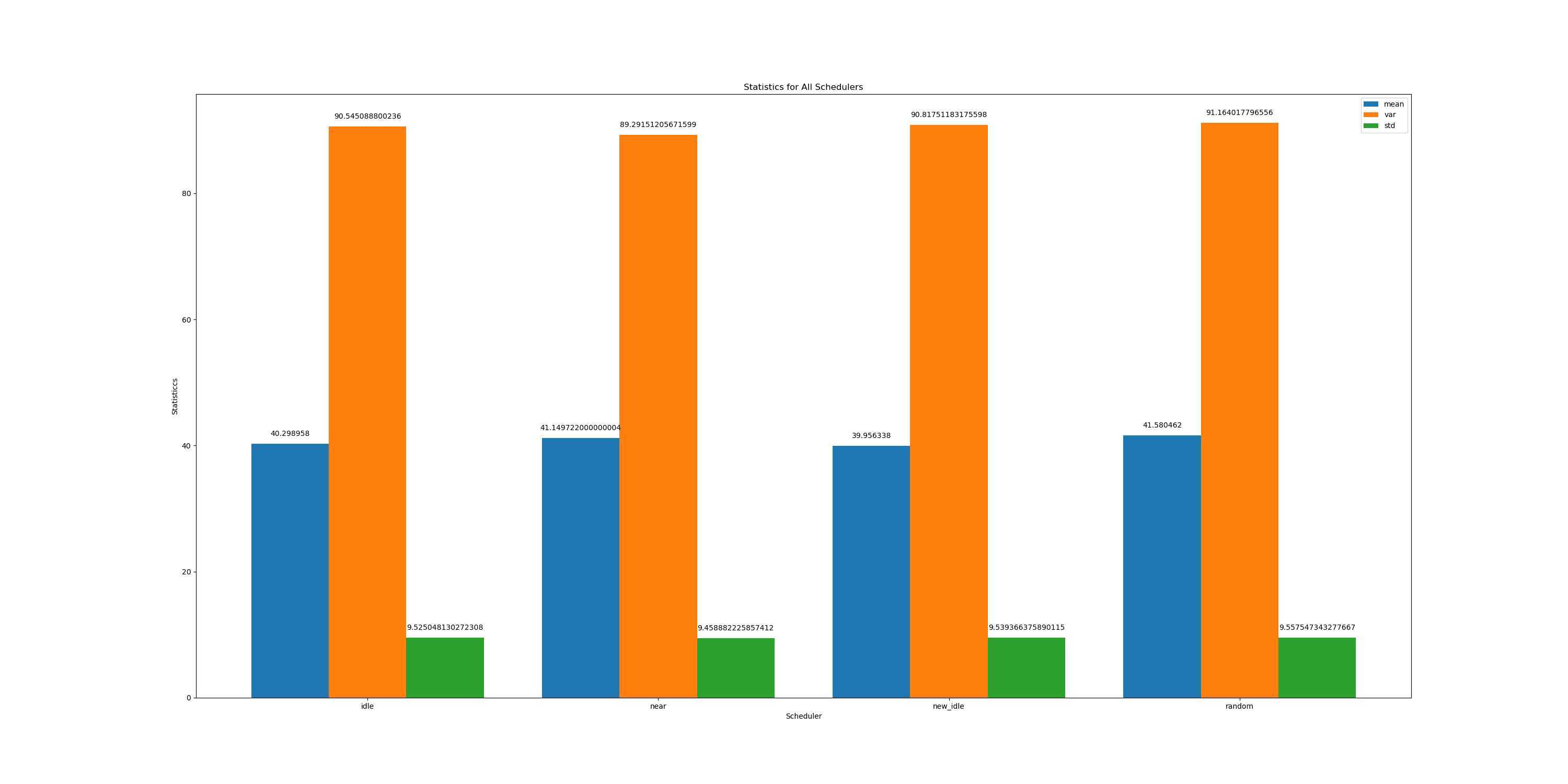
我们可以很直观的得出结论:
相比于在一堆.txt文件里头脑排序,是不是效率会高一点点呢?更重要的是,总不能心算方差吧?(如果能也请当我没说)
现在的情境下只有4种算法,所以优势体现的并不是很明显。但是我们可以试想以下情景:
粗略估计一下,假设加入1台A,那么两台A的分配大约会多出100种楼层安排方式,那要是3台呢?(欢迎继续心算)但是如果我们利用可视化的工具,就算是再多10台,给我一块N卡,给我三天时间,一定能找到已知范围内的相对最优解。
总结一下,相对于数学方法,这样会显得很没有技术含量,但是,这种问题很可能是NP的。(如果有同学已经证明了,请教教我怎么证)所以,三天时间对数学的要求可能有点点高。
但是它也有一定的短板,就是样本容量要足够的大,以及参与比较的调度算法不能都处于较低的性能水平,要不就变成了“矮子里充高子”了。
找到相对最优解之后的点对点优化大家都很明白,就不在此班门弄斧了。
接下来,我们要在本地自动化测试CPU时间(啥玩意儿?)
在和大家的交流以及经过了学长的指点后,发现这个问题对win用户确实很不友好——在linux下使用time系统调用可以轻松地实现上述操作。
但是,我们有万能的python——在time库中有一个神奇的函数process_time(),根据官方文档是可以实现和前者一样的功能的。
但是,由于这个函数的subprocess的兼容性并不好,最后还是选择了前者。(I am so into Linux)
以下提供一种可能的参考实现
‘‘‘ evaluate time on Linux ‘‘‘
r = Popen("time python ./server/get_output.py " + self.dirname + " " +
self.datadir,
stderr=PIPE,
shell=True)
s = str(r.stderr.read()).replace(‘\‘‘, ‘‘)[1:]
usr_time = float(s.split(‘ ‘)[0][:-4])
sys_time = float(s.split(‘ ‘)[1][:-6])
cpu_time = sys_time + usr_time
self.check_result(cpu_time)
# print(usr_time)
# print(sys_time)
需要注意的是,
time命令直接在terminal中调用和使用os.system调用的返回结果是不一样的。因此,得到的结果也需要不同的处理方式,具体就看大家喜欢哪一种了。
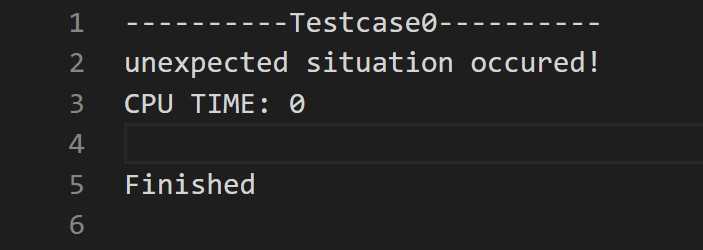
注意到上一张图中
CPU TIME是0,因为那是在win下的结果,没有实现time_check().
测试是门大学问,OO是门好课程。
我爱OO!
原文:https://www.cnblogs.com/silencejiang/p/12701979.html