Python加油站
|
类型 |
说明 |
备注 |
|
int |
整数 |
数字 |
| str |
字符串 |
一般不存放大量的数据 |
|
bool |
布尔值 |
用来判断,True,False |
|
list |
列表 |
用来存放大量数据,用[]表示,里面可以装各种数据类型 |
|
tuple |
元祖 |
只读列表,用()表示 |
|
dict |
字典 |
{key:value} |
|
set |
集合 |
不重复 |
bit_length()返回一个数的二进制长度
布尔只有两个值:True ,False,一般是没有什么操作的
0 , "", [], tuple(), {}, None
所有的空都是false,所有的非空都是true
由‘ ," , ‘‘‘,"""括起来的内容就是字符串
字符串是不可变的数据类型,不论你执行任何操作,源字符串是不会改变的,每次操作都会返回新字符串
索引从0开始,使用[下标]可以获取到每一个字符,还可以倒着数
切片:[起始位置:结束位置:步长]
特点:顾头不顾尾;默认从左到右取值;当步长为负值时,可以从右往左取值
|
类型 |
含义 |
备注 |
|
upper() |
转换成大写 |
|
|
strip() |
去掉空白 |
|
|
replace(old,new) |
把XXX替换成XXX |
|
|
split() |
切割,返回列表 |
|
|
startswith() |
判断是否以XXX开头 |
|
|
find(),count(),index() |
显示字符串位置 |
|
|
len() |
字符串长度,python的内置函数 |
|
for 变量 in 可迭代对象:
s = "alex is a teacher" s1 = s.capitalize() ##把首字母变成大写 print(s1) s2 = s.title() ##把每个单词的首字母大写 print(s2) s = "nb" s1 = s.center(10,"*") ##强行使用*在原字符串左右两端进行拼接,拼接成10个单位 print(s1) s = " alex is a it" s1 = s.strip() ##默认去掉开头和结尾的空格 print(s1) username = input("请输入用户名:").strip() password = input("请输入密码:").strip() if username == ‘sunyun‘ and password == ‘123‘: print("successful") else: print("failed") s = "nb mayijinfu nb feige nb" print(s.strip("nb")) ##可以指定要去掉的内容 s = "nb mayi_jinfu nb feige nb" s2 = s.split("_") ##切完的结果是一个列表,列表中装的是字符串 print(s2) s = ‘‘‘蚂蚁金服 上班的 早上九点 晚上六点 ‘‘‘ lst = s.split("\n") print(lst) s = "我叫%s,我今年%s岁了,我喜欢%s" %("sunyun","28","nba") print(s) s = "我叫{},今年{}了,我喜欢{}" .format("sunyun","20","nba") print(s) s = "我叫{name},今年{age}了,爱好是{hobbies}" .format(name="sunyun",age="20",hobbies="nba") print(s) s = "alex is a it" print(s.startswith("alex") ) ##以什么开头 print(s.endswith("it") ) s = "I want to mayijinfu" print(s.count("a")) ##计算a出现的次数 s = "I want to mayijinfu" print(s.find("a")) ##查找XXXX在字符串中出现的位置,只找第一次出现的位置,没有就返回-1 print(s.index("a")) ##当字符串不存在的时候,报错 s = "123ad" print(s.isdigit() ) ##%d print(s.isalpha() ) ##字母 print(s.isalnum() ) ##是否由数字和字母组成 s = "蚂蚁金服集团在杭州" while n < 9: print(s[n]) n = n + 1 for c in s: ##迭代 print(c)
#请输出name变量中,对应e所在的索引位置
name = "alex leNb"
index = 0
for c in name:
if c == "e":
print(index)
index = index + 1
#计算两数相加
jisuan = input("请输入你要计算的内容:")
jisuan = jisuan.replace(" ","")
lst = jisuan.split("+")
print(int(lst[0])+ int(lst[1]))
#计算用户输入的内容中有多少个整数
zhengshu = 0
content = input("请输入内容:")
for c in content:
if c.isdigit():
zhengshu = zhengshu + 1
print(zhengshu)
#回家路上
while True:
content = input("请输入你要选择的路线A,B,C:")
if content == "A":
print("走大路回家")
traffic = input("请问,是选择公交还是步行?")
if traffic == "公交":
print("spend 10min to home")
elif traffic == "步行":
print("wait in here")
break
elif content == "B":
print("走小路回家")
break
elif content == "C":
print("绕路回家")
play = input("请选择去网吧还是去超市?")
if play == "网吧":
print("2小时到家")
elif play == "超市":
print("1.5小时到家")
break
else:
print("今晚加班,不回家!")
break
#计算1-2+3-4+5-6+.....+99的和,除过88
count = 1
sum = 0
while count <= 99:
if count == 88:
count = count + 1
continue
if count %2 == 0:
sum = sum - count
else:
sum = sum + count
count = count + 1
print(sum)
#输入一段话,判断里面大写,小写,数字,其他出现的次数
daxie = 0
xiaoxie = 0
shuzi = 0
other = 0
content = input("请输入一句话:")
for c in content:
if c.isupper():
daxie = daxie + 1
elif c.islower():
xiaoxie = xiaoxie + 1
elif c.isdigit():
shuzi = shuzi + 1
else:
other = other + 1
print(daxie,xiaoxie,shuzi,other)
name = input("请输入你的名字:")
location = input("请输入地点:")
hobby = input("请输入爱好:")
print("尊敬的{}最喜欢在{}打{}".format(name,location,hobby) )
#输入一个人名,判断是否在百家姓中
first_names = ‘‘‘
赵钱孙李,
周吴郑王,
冯程楚魏,
欧阳东郭
‘‘‘
sum = ""
name = input("请输入你的名字:")
for c in name:
sum = sum + c
if sum in first_names:
print("在百家姓中")
break
else:
print("不在百家姓中")
列表由[ ]来表示,每一项元素使用逗号隔开,列表什么都能装,也能 装对象的对象,是一个可变的数据类型
列表可以装大量的数据
列表和字符串一样,也有索引和切片,只不过切出来的内容是列表
lst = ["赵杰","李四","李青","马云"]
# lst.append("阿瑟") 只能在列表的末尾添加
# lst.insert(2,"鲁能") 在列表的某一位置插入
# lst.extend(["麻花藤"]) 迭代添加,会添加到原有列表的末尾,可以添加多个
print(lst)
data = lst.pop(2) ##返回被删除的数据
print(data)
print(lst)
lst.remove("李青") ##删除元素,如果列表中不存在会报错
print(lst)
del lst[1:3] ##切片删除
print(lst)
lst.clear() ##清空
print(lst)
lst = ["英雄联盟","反恐精英","王者荣耀","CF","天天跑酷"]
lst[0] = "扫雷"
lst[1:3] = ["卡丁车"]
lst[1::2] = ["haha","QQfeiche"]
print(lst)
lst = ["火锅","香锅","巫山烤鱼","烤鸭"]
for el in lst:
print(el)
lst = ["alex","gay","sunyun",["范大夫","李丽",[1,"火锅","fengzhua"],"詹姆斯"]]
print(lst[3][2][1])
lst = [1,3,4,66,76,45,69,100]
lst.sort() ##升序
print(lst)
lst = [1,3,4,66,76,45,69,100]
lst.sort(reverse=True) ##降序
print(lst)
lst = ["支付宝","蚂蚁金服","阿里云","私有云"]
lst.reverse() ##翻转
print(lst)
tu = tuple() ##空元组
tu = (3,) ##元组中如果只有一个元素,需要在括号中里写一个
print(type(tu))
print((1+3)*5)
print((5))
元组不能增删改,只能查找
tu = ("人民币","美元","英镑","欧元")
# tu.append("哈哈")
# tu[1] = "泰铢"
# del tu[2]
for c in tu:
print(c)
for i in range(1,5):
print(i)
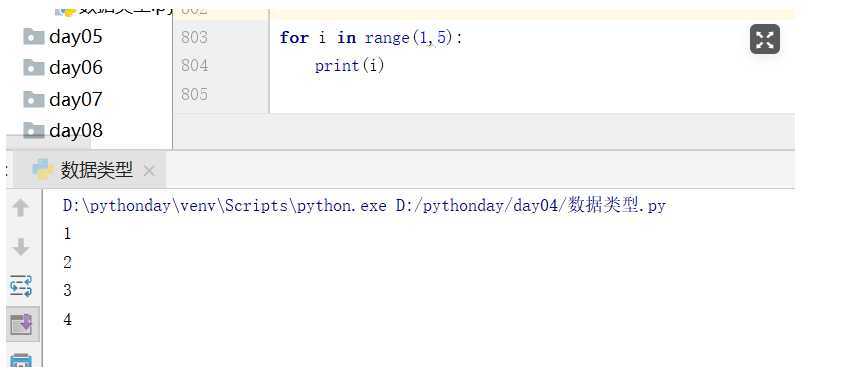
for i in range(1,10,2):
print(i)
for i in range(10,1,-1):
print(i)
#range在列表中的应用
lst = ["蚂蚁金服","阿里云","天猫","淘宝"]
for i in range(len(lst)):
print(i)
li = ["alex","WuSir","ritian","barry","wenzhou"]
#计算列表的长度并输出
# for i in range(len(li)):
# print(i)
#列表中追加元素"seven",并输出添加后的列表
# li.append("seven")
# print(li)
#请在列表的第一个位置插入元素"Tony",并输出添加后的列表
# li.insert(1,"Tony")
# print(li)
#请修改列表第二个位置的元素为sunun,并输出修改后的列表
# li[2] = "sunyun"
# print(li)
#请将列表l2[1,"a",3,4,"hear"]的每一个元素添加到列表li中,一行代码实现,不允许循环添加
# li.extend([1,"a",3,4,"hear"])
# print(li)
#请删除列表中的元素barry,并输出添加后的列表
# li.pop(3)
# print(li)
# li.remove("barry")
# print(li)
#请删除列表中的第二个元素,并输出删除的元素和删除元素后的列表
# data = li.pop(2)
# print(data)
# print(li)
#请删除列表中的第二至第四个元素,并输出删除元素后的列表
# del li[2:4]
# print(li)
#请将列表所有元素翻转,并输出翻转后的列表
# li.reverse()
# print(li)
#请计算出"alex"元素在列表li中出现的次数,并输出该次数
# c = li.count("alex")
# print(c)
li = [1,3,2,"a",4,"b",5,"c"]
#通过对li列表的切片形成新的列表l1,l1 = [1,3,2]
li1 = li.pop[3:]
print(li1)
#通过对li列表的切片形成新的列表l2,l2 = ["a",4,"b"]
#通过对li列表的切片形成新的列表l3,l3 = [1,2,4,5]
#通过对li列表的切片形成新的列表l4,l4 = [3,"a","b"]
#通过对li列表的切片形成新的列表l5,l5 = ["c"]
#通过对li列表的切片形成新的列表l6,l6 = ["b","a",3]
lis =[2,3,"k",["sun",20,["k1",["tt",3,"1"]],89],"ab","adv"]
# lis[3][2][1][1] =‘100‘
# lis[1]=‘100‘
# print(lis)
lis[3][2][1][1] = str(lis[3][2][1][1] + 97)
print(lis)
# lis[3][2][1][0] = ‘TT‘
# print(lis)
li = ["alex","eric","rain"]
s = ‘‘
for i in li:
s = s + i + ‘_‘
print(s[:-1])
li = ["alex","wusir","tiabai","barry"]
for i in range(len(li)):
print(i)
li = []
for i in range(101):
if i %2 ==0:
li.append(i)
print(li)
#把字符串中的大写字母全部换成小写
li = [1,3,4,"alex",[3,7,8,"SUNyun"],5,"KONGGE"]
for i in li:
if type(i) == list:
for el in i:
if type(el) == str:
print(el.lower())
else:
print(el)
else:
if type(i) == str:
print(i.lower())
else:
print(i)
#小写全部换成大写
for i in li:
if type(i) == list:
for el in i:
if type(el) == str:
print(el.upper())
else:
print(el)
else:
if type(i) == str:
print(i.upper())
else:
print(i)
#求成绩平均值
li = []
sum_num = 0
while True:
str_input = input("请输入你的姓名和分数(格式如:张三_44),输入Q退出:")
if str_input.lower() ==‘q‘:
break
else:
ret = str_input.split(‘_‘)
li.append(ret[1])
for i in li:
sum_num = sum_num + int(i)
print(sum_num / len(li))
dic = {‘name‘:‘sunyun‘,‘age‘:20}
print(dic)
dic = {1:‘a‘,2:‘b‘,3:‘c‘}
print(dic)
dic = {True:‘1‘,False:‘2‘}
print(dic)
dic = {(1,2,3):‘abc‘}
print(dic)
dict:用{}来表示,键值对数据{key:value},具有唯一性;
键:都必须是哈希的,不可变的数据类型就可以当做字典中的键;
值:没有任何限制
dic = {‘name‘:‘sunyun‘,‘age‘:20,‘hobbies‘:‘nba‘}
dic[‘call‘] = ‘师傅‘
print(dic)
dic = {‘name‘:‘sunyun‘,‘age‘:20,‘hobbies‘:‘nba‘} #如果在字典中存在就不进行任何操作,不存在就进行添加
dic.setdefault(‘多伦多‘,‘猛龙‘)
print(dic)
dic = {‘name‘:‘sunyun‘,‘age‘:20,‘hobbies‘:‘nba‘}
dic.pop(‘name‘) ##后面直接跟键
print(dic)
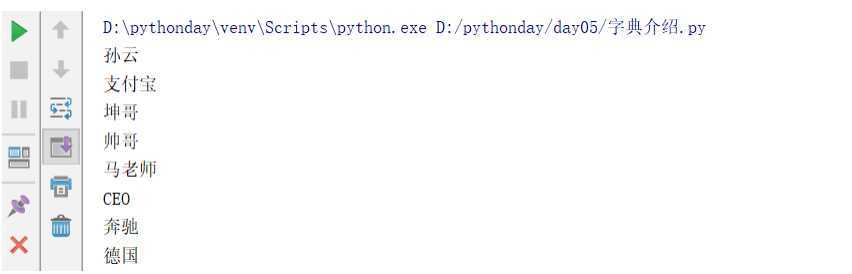
dic = {‘孙云‘:‘支付宝‘,‘坤哥‘:‘蚂蚁金服‘,‘马老师‘:‘CEO‘}
ret = dic.pop(‘孙云‘) #通过key删除,返回被删除的value
print(ret)
print(dic)
dic = {‘孙云‘:‘支付宝‘,‘坤哥‘:‘蚂蚁金服‘,‘马老师‘:‘CEO‘}
ret = dic.popitem() ##一般删除最后一个key
print(ret)
print(dic)
dic = {‘孙云‘:‘支付宝‘,‘坤哥‘:‘蚂蚁金服‘,‘马老师‘:‘CEO‘}
del dic[‘坤哥‘]
print(dic)
dic = {‘孙云‘:‘支付宝‘,‘坤哥‘:‘蚂蚁金服‘,‘马老师‘:‘CEO‘}
dic.clear()
print(dic)
dic = {‘孙云‘:‘支付宝‘,‘坤哥‘:‘蚂蚁金服‘,‘马老师‘:‘CEO‘}
dic1 = {‘孙云‘:‘支付宝‘,‘坤哥‘:‘帅哥‘,‘马老师‘:‘CEO‘,‘奔驰‘:‘德国‘}
dic1.update(dic)
print(dic1)
dic = {‘孙云‘:‘支付宝‘,‘坤哥‘:‘帅哥‘,‘马老师‘:‘CEO‘,‘奔驰‘:‘德国‘}
for i in dic: #for循环默认取出的是键
print(i)
print(dic[‘孙云‘]) #没有这个键的时候查询会报错
print(dic.get(‘孙云‘)) #没有返回None,可以指定返回值
print(dic.get(‘孙云大师‘,‘很酷‘))
print(dic.setdefault(‘孙云‘)) #没有返回None
dic = {‘孙云‘:‘支付宝‘,‘坤哥‘:‘帅哥‘,‘马老师‘:‘CEO‘,‘奔驰‘:‘德国‘}
# print(dic.keys()) #高仿列表
for i in dic.keys(): #拿到key
print(i)
for i in dic.values(): #拿到value
print(i)
print(dic.items())
for i in dic.items(): #会拿到每一个元组
print(i)
a,b = ‘12‘ #将后边解构打开按位置赋值给变量,支持字符串,列表,元组
print(a)
print(b)
dic = {‘孙云‘:‘支付宝‘,‘坤哥‘:‘帅哥‘,‘马老师‘:‘CEO‘,‘奔驰‘:‘德国‘}
for i in dic.items():
a,b = i
print(a)
print(b)
for a,b in dic.items(): #上下结果一致
print(a)
print(b)
dic = {
‘name‘:‘sunyun‘,
‘age‘:20,
‘hobbies‘:{
‘name‘:‘lanqiu‘,
‘age‘:10,
‘salary‘:1000,
‘baby‘:[
{‘name‘:‘zhangsan‘,‘age‘:12},
{‘name‘:‘lisi‘,‘age‘:23}]
}
}
sit = dic[‘hobbies‘][‘baby‘][0][‘age‘]
print(sit)
#有字符串"k:1|k1:2|k2:3|k3:4",处理成字典{‘k‘:1,‘k1‘:2,‘k2‘:3,‘k4‘:4}
s = "k:1|k1:2|k2:3|k3:4"
dic = {}
new_li = s.split("|")
for i in new_li:
k,v = i.split(":")
dic[k] = int(v)
print(dic)
#列表[11,22,33,44,55,66,77,88,99,100],将大于66的值放在k1下,小于66的放在k2下
li = [11,22,33,44,55,66,77,88,99,100]
dic = {‘k1‘:[],‘k2‘:[]}
for i in li:
if i == 66:
continue
elif i > 66:
dic.setdefault(‘k1‘).append(i)
else:
dic.setdefault(‘k2‘).append(i)
print(dic)

goods = [{"name":"电脑","price":1999},
{"name":"鼠标","price":10},
{"name":"游艇","price":20},
{"name":"美女","price":998}]
while True:
for i in goods:
good = i
print(goods.index(i)+1,i[‘name‘],i[‘price‘])
str_input = input("请输入你要选的商品序号,输入Q退出:")
if str_input.upper() == ‘Q‘:
break
elif str_input.isdigit() and 0 < int(str_input) < len(goods):
i_index = int(str_input) - 1
print(goods[i_index][‘name‘],goods[i_index][‘price‘])
else:
print("输入有误,请重新输入!")
|
== |
比较 |
比较的是两边的值 |
|
is |
比较 |
比较的是内存地址,id() |
s = ‘alex‘
print(s.encode(‘utf-8‘))
n = ‘你好‘
print(n.encode(‘utf-8‘) )
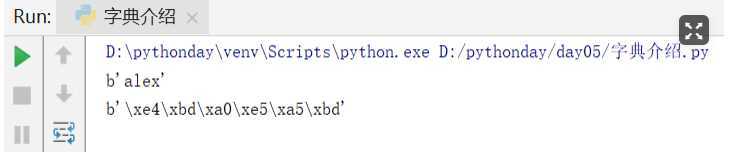
encode("编码方式") ----拿到明文编码后,对应的字节
decode("编码方式")-----将编码后的字节解码成对应的明文
#合并到一个列表当中,格式如:
[{‘name‘: [‘apple‘], ‘price‘: [‘10‘], ‘amount‘: [‘3‘], ‘year‘: [‘2012‘]}, {‘name‘: [‘tesla‘], ‘price‘: [‘1000‘], ‘amount‘: [‘1‘], ‘year‘: [‘2013‘]}]
a1.txt文件内容:
name:apple price:10 amount:3 year:2012
name:tesla price:1000 amount:1 year:2013
f = open("a1.txt",mode="r",encoding="utf-8") ##打开a1.txt文件
result = []
for line in f:
dic = {}
lst = line.split()
for el in lst:
l2 = el.split(":")
dic[l2[0]] = [l2[1]]
result.append(dic)
print(result)
概念:
函数是对功能的封装
语法:
def 函数名():
函数体
调用:
函数名()
def part():
print("nba")
print("cba")
print("ncaa")
part()
print("china")
part()
def sum():
a = int(input("请输入一个数a:"))
b = int(input("请输入一个数b:"))
c = a + b
return c
ret = sum()
print(ret)
返回值:
(1)如果函数什么都不写;不写return,没有返回值,得到的是none
(2)在函数中间或者末尾写return,返回的是none
(3)在函数中写return值,返回一个值
(4)在函数中可以返回多个返回值,return 值1,值2,值3,....,接受的是元组
参数:
形参
(1)位置参数
(2)默认值参数,先位置后默认值
(3)动态参数
实参
(1)位置参数,按照形参的参数位置,给形参传值
(2)关键字参数,按照形参的名字给形参传值
(3)混合参数,也就是即用位置参数,也用关键参数
传参
把实参的值交给形参的过程
位置参数:
默认值参数:
动态传参:
(1)*args ---》位置参数动态传参
(2)**kwargs ---》关键字参数动态传参
顺序:位置---->*args---->默认值---->**kwargs
写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者
##方法一
def func(lst):
result = []
for i in range(len(lst)):
if i%2 == 1:
result.append(lst[i])
return result
ret = func(["蚂蚁","坤哥","孙云","老郭","金服","支付宝"])
print(ret)
##方法二
def func(lst):
return lst[1::2]
# for i in range(len(lst)):
# if i%2 == 1:
# result.append(lst[i])
ret = func(["蚂蚁","坤哥","孙云","老郭","金服","支付宝"])
print(ret)
写函数,判断用户传入的对象(字符串,列表,元组)长度是否大于5,若大于5显示true,小于5则显示false
def func(b):
return len(b) > 5
print(func("safsdfsafaf"))
写函数,检查传入列表的长度,如果大于2,将列表的前两项内容返回给调用者
def func(a):
if len(a) > 2:
return a[0:2]
print(func("dsfdf"))
写函数,计算传入函数的字符串中,数字,字母,空格以及其他内容的个数,并返回结果
def func(s):
shuzi = 0
zimu = 0
kongge = 0
qita = 0
for i in s:
if i.isdigit():
shuzi = shuzi + 1
elif i.isalpha():
zimu = zimu + 1
elif i == ‘ ‘:
kongge = kongge + 1
else:
qita = qita + 1
return shuzi,zimu,kongge,qita
print(func("sdfadf12344@@@##$ "))
写函数,接受两个数字参数,返回最大的
def func(a,b):
if a > b:
return a
else:
return b
print(func(10,80))
写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新的内容返回给调用者
dic = {"k1":"v1v1","k2":[11,22,33,55]}
字典中的value只能是字符串或列表
将下面两段字符串变成一个列表形式,格式如
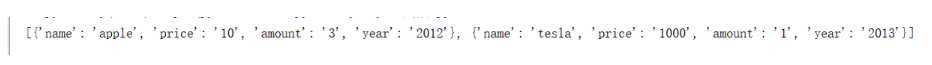
name:apple price:10 amount:3 year:2012
name:tesla price:1000 amount:1 year:2013
result = []
f = open("a1.txt",mode = "r",encoding="utf-8")
for i in f:
dic = {}
lst = i.split()
for e in lst:
ll = e.split(":")
dic[ll[0]] = ll[1]
result.append(dic)
print(result)
输入一个数a,再输入一个数b,求a+b的和
def sum():
a = int(input(" 请输入一个a:"))
b = int(input("请输入一个b:"))
c = a + b
return c
res = sum()
print(res)
位置调用:出来的是元组
def chi(*food):
print(food)
chi("盖浇饭","火锅","炒面")
chi("米饭","馒头")
chi("牛肉面")

关键字调用:出来的是字典
def chi(**food):
print(food)
chi(food1="麻辣烫",food2="肉夹馍",food3="包子")

def func(a,b):
"""
:param a:
:param b:
:return:
"""
return a + b
print(func.__doc__)
def func(*args,**kwargs):
print(args,kwargs)
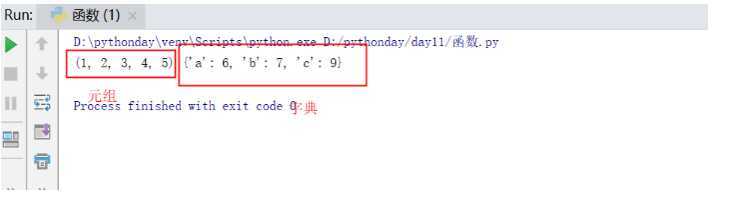
func(1,2,3,4,5,a=6,b=7,c=9)
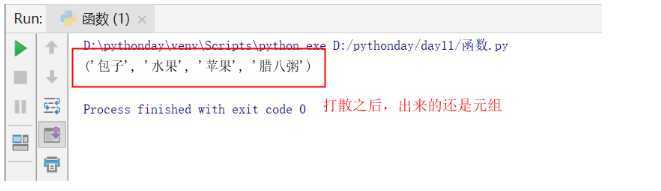
def func(*food): ##聚合,位置参数
print(food)
lst = ["包子","水果","苹果","腊八粥"]
func(*lst) ##打散,把list,tuple,set,str进行迭代打散
a = 10 ##全局名称空间
def fn():
b = 20 ##局部名称空间
print(a)
def gn():
print(a)
fn()
gn()
内置命名空间----->全局命名空间----->局部命名空间(在函数调用时产生)
作用域就是作用范围,按照生效范围来看分为全局作用域和局部作用域
全局作用域:包含内置命名空间和全局命名空间,在整个文件的任何位置都可以使用(遵循从上到下逐行执行)
局部作用域:只在函数调用时使用
a = 10
def fn():
b = 20
def gn():
pass
def en():
pass
print(globals()) ##globals可以查看全局作用域中的内容
print(locals()) ##查看当前作用域中的内容

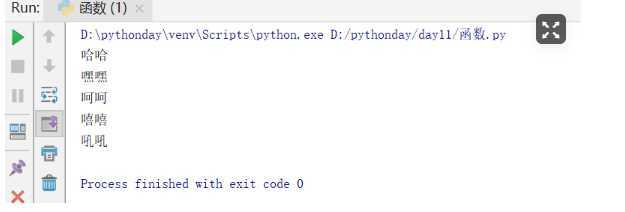
def outer():
print("哈哈")
def inner_1():
print("呵呵")
def inner_1_1():
print("嘻嘻")
inner_1_1()
print("吼吼")
def inner_2():
print("嘿嘿")
inner_2()
inner_1()
outer()
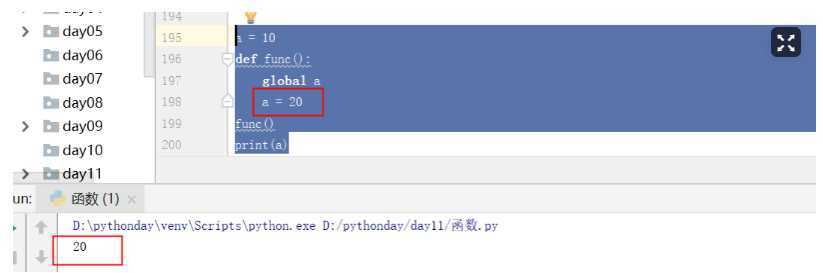
将全局中的内容引入到函数内部--->global
a = 10
def func():
global a
a = 20
#在调用func后,将全局中的10换成20
func()
print(a)
##global的作用:1.可以把全局中的内容引入到函数内部;2.在全局中创建一个变量
寻找外层函数(一层一层剥),直到找见为止,注意只能找内部函数,不能找全局函数
def outer():
a = 10
def inner():
global a
a = 20
inner()
print(a)
outer()
def outer():
a = 10
def inner():
nonlocal a ##寻找外层函数中离它最近的那个变量
a = 20
inner()
print(a)
outer()
综合练习:
a = 1
def fun_1():
a = 2
def fun_2():
nonlocal a
a = 3
def fun_3():
a = 4
print(a)
print(a)
fun_3()
print(a)
print(a)
fun_2()
print(a)
print(a)
fun_1()
print(a)
形参:
位置参数,默认值参数,动态传参
实参:
位置参数----》记住位置
关键字参数----》记住名字
混合参数----》先位置后关键字
*args----->位置参数动态传参
**kwargs----->关键字参数动态传参
位置参数---->*args----->默认值----->**kwargs
函数名可以当做变量名来使用
def func1():
print("辣条")
def func2():
print("麻辣烫")
def func3():
print("米饭")
lst = [func1,func2,func3]
for i in lst:
i()
把函数名当做参数传递给另一个函数
def my():
print("nba")
def proxy(fn):
print("cba")
fn()
print("ncaa")
proxy(my)
def func1():
print("我是func1")
def func2():
print("我是func2")
def func(fn):
print("我是func")
fn()
func(func1)
def func1():
print("我是func1")
def func2():
print("我是func2")
def func(fn,gn):
print("我是func")
fn()
gn()
print("哈哈")
func(func1,func2)
在内层函数中方为外层函数的变量
def outer():
a = 10
def inner():
print(a)
inner()
outer()
闭包的使用----->简易爬虫
from urllib.request import urlopen
def outer():
#常驻内存使用
s = urlopen("http://www.jszg.edu.cn/portal/home/index").read()
def getContent():
return s
return getContent
print("爬取内容:")
pa = outer()
ret = pa()
print(ret)
用来遍历列表,字符串,元组.......可迭代对象
可跌倒对象Iterable,里面有__iter__(),没有__next__()
迭代器Iterator,里面有__iter__(),还有__next__()
迭代器特点:
1.只能向前
2.惰性机制
3.省内存(生成器)
s = "蚂蚁金服"
it = s.__iter__()
print(it.__next__())
print(it.__next__())
print(it.__next__())
print(it.__next__())
lst = ["李宁","姚明","詹姆斯","卡哇伊"]
it = lst.__iter__()
while 1:
try: #尝试执行
el = it.__next__() #获取下一个元素
print(el)
except StopIteration: #处理错误
break
for循环的内部机制:
1.首先获取到迭代器
2.使用while循环获取数据
3.it.__next__()来获取数据
4.处理异常:try: expect StopIteration
yield:相当于return,可以返回数据,单yield不会彻底中断函数,分段执行函数
gen.__next__()执行函数,执行到下一个yield
def func():
print("娃哈哈")
yield 1
print("嘿嘿")
gen = func()
rt = gen.__next__()
print(rt)
内存节省举例:
def order():
for i in range(100):
yield "球号" + str(i)
gn = order() #获取生成器
kunge = gn.__next__()
print(kunge)
fengge = gn.__next__()
print(fengge)
send函数和__next__()功能是一样的,可以执行到下一个yield,也可以给上一个yield位置传值
def func():
print("我是一号位")
a = yield 123
print(a)
print("我是二号位")
b = yield 456
print(b)
print("我是三号位")
c = yield 789
print(c)
print("我是四号位")
d = yield 80
gn = func()
print(gn.__next__())
print(gn.send("蚂蚁金服"))
print(gn.__next__())
def eat():
print("我吃什么呀")
a = yield "馒头"
print("a=",a)
b = yield "鸡蛋灌饼"
print("b=",b)
c = yield "韭菜盒子"
print("c=",c)
yield "GAME OVER"
gen = eat() #获取生成器
ret1 = gen.__next__()
print(ret1)
ret2 = gen.send("胡辣汤")
print(ret2)
ret3 = gen.send("狗粮")
print(ret3)
ret4 = gen.send("火腿")
print(ret4)
def func():
yield 10
yield 20
yield 30
yield 50
for i in func(): #利用for循环进入生成器
print(i)
print(list(func()))
老方法:
lst = []
for i in range(1,5):
lst.append("python" + str(i))
print(lst)
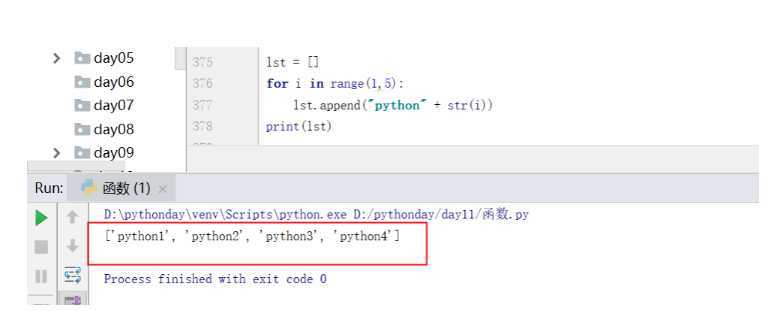
推导式:
lst = ["python" + str(i) for i in range(1,5)]
print(lst)
#语法:[结果 for循环]lst = ["python" + str(i) for i in range(1,5)]
print(lst)
#语法:[结果 for循环 判断]
lst = [i for i in range(10) if i%2 == 1]
print(lst)
names = [[‘tom‘,‘billy‘,‘jefferson‘,‘andrew‘,‘wesley‘,‘steven‘,‘joe‘],[‘alice‘,‘jill‘,‘ana‘,‘wendy‘,‘jennifer‘]] lst = [] for line in names: for name in line: if name.count("e") == 2: lst.append(name) print(lst)
列表推导式
lst = [11,22,33,44,55]
dic = {i:lst[i] for i in range(len(lst))}
print(dic)
字典推导式
dic = {"nb":"姚明","jay":"詹姆斯","kunge":"坤哥"}
d = {v:k for k,v in dic.items()}
print(d)
集合推导式
lst = [1,1,1,2,3,4,5,5]
d = set(lst)
print(d)
s = {el for el in lst}
print(s)
gen = (i for i in range(5)) ##获取到的是生成器(惰性机制),一个一个拿,所以几乎不占内存
print(gen.__next__())
print(gen.__next__())
print(gen.__next__())
def func():
print(111)
yield 222
g = func() ##获取生成器
g1 = (i for i in g)
g2 = (i for i in g1)
print(list(g)) #从源头已经拿走数据
print(list(g1))
print(list(g2))
def func():
print(111)
yield 222
yield 333
g = func()
g1 = (i for i in g)
g3 = func() #g3生成器与g生成器完全是两个不同的生成器,他们两个之间没有任何关系
g2 = (i for i in g3)
print(list(g))
print(list(g1))
print(list(g2))
def add(a,b):
return a + b
def test():
for r_i in range(4):
yield r_i #0,1,2,3,4
g = test() #获取生成器
for n in [2,10]: #惰性机制导致了,生成器只关注最后一个值,可以把n=2,n=10拆开来看
g = (add(n,i) for i in g)
print(list(g))
def add(a,b):
return a + b
def test():
for r_i in range(4):
yield r_i
g = test()
for n in [1,10,5]:
g = (add(n,i) for i in g)
print(list(g))
数学运算
print(round(4.56)) #四舍五入
print(round(4.49))
print(pow(2,3)) #次幂
print(pow(2,3,3)) #计算余数
print(sum([2,5,6]))
print(sum([2,5,6],5)) #求和
print(min([5,67,66,78,89])) #最小值
print(max([34,56,66,77,88])) #最大值
lst = ["ABD","DCN","VBC","NBA"]
ll = reversed(lst) #反向排列
print(list(ll))
lst = ["姚明","科比","卡哇伊","登哥"]
# for el in lst:
# print(el)
#
# for i in range(len(lst)):
# print(i)
for i,el in enumerate(lst):
print(i,el)

s = "5 + 8"
ret = eval(s)
print(ret)

贪婪匹配表示从前往后匹配,只要是满足条件的是,它就一锅端,全部拿下;而非贪婪匹配是,只要匹配到满足条件的,它就停止向后匹配,适可而止,见好就收!
匹配整数或者小数(包括正数和负数)
-?\d+(\.\d+)?
匹配年月日:格式2019-11-06
^[1-9]\d{0,3}-(1[0-2]|0?[1-9])-(3[01]|[1-2]|0?[1-9])$
匹配QQ号
[1-9]\d{4,11}
匹配电话号码
1[3-9]\d{9}
匹配长度为8-10位的用户密码,包含数字,子母,下划线
\w{8,10}
匹配4位数字,子母
[0-9a-zA-Z]{4}
匹配邮箱规则
^[a-zA-Z0-9_.-]+@[a-zA-Z0-9-]+(\.[a-zA-Z0-9-]+)*\.[a-zA-Z0-9]{2,6}$
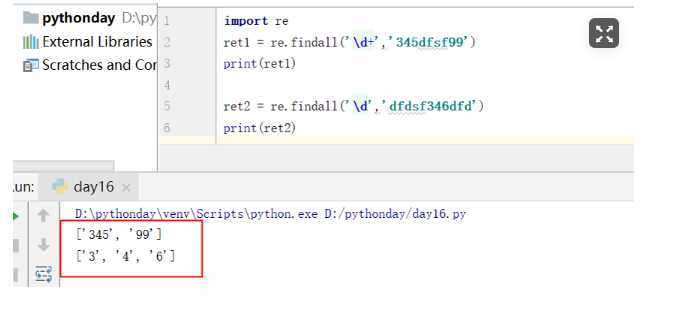
findall
import re
ret1 = re.findall(‘\d+‘,‘345dfsf99‘)
print(ret1)
ret2 = re.findall(‘\d‘,‘dfdsf346dfd‘)
print(ret2)
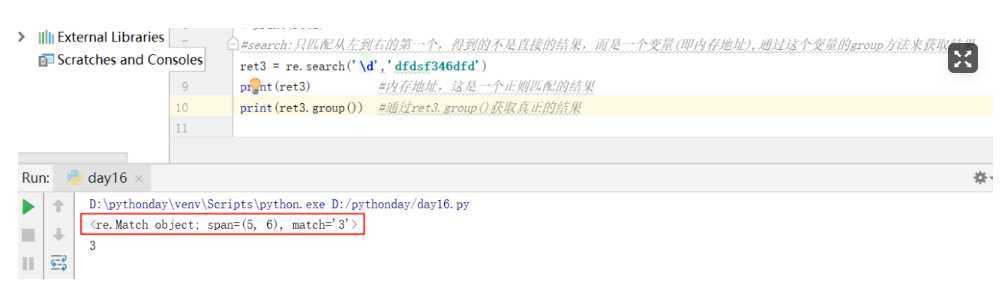
search
#search:只匹配从左到右的第一个,得到的不是直接的结果,而是一个变量(即内存地址),通过这个变量的group方法来获取结果
#如果没有匹配到,返回结果为none,使用group会报错
ret3 = re.search(‘\d‘,‘dfdsf346dfd‘)
print(ret3) #内存地址,这是一个正则匹配的结果
print(ret3.group()) #通过ret3.group()获取真正的结果
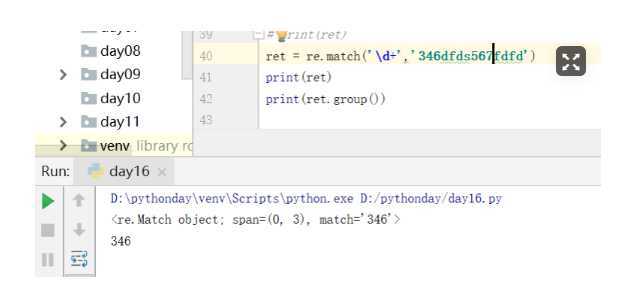
match
#match从头开始匹配,相当于search中的正则表达式加上一个^
ret = re.match(‘\d+‘,‘346dfds567fdfd‘)
print(ret)
print(ret.group())
split
s = ‘kunge20fengge18haoge15‘
ret = re.split(‘\d+‘,s)
print(ret)

s = ‘kunge20fengge18haoge15‘
ret = re.split(‘\d‘,s)
print(ret)

sub
ret = re.sub(‘\d+‘,‘Q‘,‘346dfds23fdf12d‘)
print(ret)
ret1 = re.sub(‘\d+‘,‘Q‘,‘346dfds23fdf12d‘,2)
print(ret1)

subn
返回一个元组,第二个元素是替换的次数
ret = re.subn(‘\d+‘,‘Q‘,‘346dfds23fdf12d‘)
print(ret)

s = ‘<a>kunge</a>‘
ret = re.search(‘>(\w+)<‘,s)
print(ret.group(1))
s2 = ‘<a>kunge</a>‘
ret1 = re.search(‘<(\w+)>(\w+)</(\w+)>‘,s2)
print(ret1.group(1))
print(ret1.group(2))
print(ret1.group(3))

#取消分组优先(?:)
ret = re.findall(‘\d+(?:\.\d+)?‘,‘3.2323*4.8‘)
print(ret)

分组命名
s = ‘<b>kunge</b>‘
ret = re.search(‘>(?P<con>\w+)<‘,s)
print(ret.group(1))
print(ret.group(‘con‘))

s = ‘<b>kunge</b>‘
pattern = ‘<(?P<tab>\w+)>(\w+)</(?P=tab)>‘
ret = re.search(pattern,s)
print(ret)

判断手机号码是否合法
while True:
phone_number = input(‘please input your phone number: ‘)
if len(phone_number) == 11 and phone_number.isdigit() and (phone_number.startswith(‘13‘) or phone_number.startswith(‘14‘) or phone_number.startswith(‘15‘) or phone_number.startswith(‘18‘)):
print(‘是合法的手机号码‘)
else:
print(‘不合法的手机号码‘)

import re
phone_number = input(‘please input your phone number : ‘)
if re.match(‘^(13|14|15|18)[0-9]{9}$‘,phone_number):
print(‘是合法的手机号码‘)
else:
print(‘不是合法的手机号码‘)

finditer返回一个存放匹配结果的迭代器
import re
ret = re.finditer(‘\d‘,‘dfdf345dfdf897a‘)
print(ret)
print(next(ret).group())
print(next(ret).group())
print([i.group() for i in ret])

findall的优先级查询
import re
ret = re.findall(‘www.(baidu|jingdong).com‘,‘www.baidu.com‘)
print(ret)
ret = re.findall(‘www.(?:baidu|jingdong).com‘,‘www.baidu.com‘)
print(ret)

split的优先级查询
import re
ret = re.split(‘\d+‘,‘ena5gon8yuan‘)
print(ret)
ret = re.split(‘(\d+)‘,‘ena5gon8yuan‘)
print(ret)

取随机整数
取随机小数
从一个列表中随机抽取值
打乱一个列表的顺序
import random
print (random.random()) #取0-1之间的小数
print(random.uniform(1,2)) #取1-2之间的小数

import random
print(random.randint(1,2)) #顾头也顾尾
print(random.randrange(1,2)) #顾头不顾尾
print(random.randrange(1,100,2)) #取奇数

import random
lst = [‘a‘,‘b‘,(1,2),456,{‘nb‘:‘dengge‘,‘kf‘:‘李小龙‘}]
print(random.choice(lst))

import random
lst = [‘a‘,‘b‘,(1,2),456,{‘nb‘:‘dengge‘,‘kf‘:‘李小龙‘}]
print(random.choice(lst))
print(random.sample(lst,2))

import random
lst = [‘a‘,‘b‘,(1,2),456,{‘nb‘:‘dengge‘,‘kf‘:‘李小龙‘}]
random.shuffle(lst) #打乱一个列表的顺序,是在原列表的基础上直接进行修改,节省空间
print(lst)

生成一个四位或六位的随机数
import random
def code(n):
s = ‘‘
for i in range(n):
num = random.randint(0,n)
s = s + str(num)
return s
print(code(4))
print(code(6))

生成一个六位 数字+字母的验证
import random
s = ‘‘
for i in range(6):
num = str(random.randint(0,9))
zimu = chr(random.randint(65,90))
res = random.choice([num,zimu])
s = s + res
print(s)

import time
print(time.strftime(‘%Y-%m-%d %H:%M:%S‘))
print(time.strftime(‘%c‘))

时间戳转换成字符串时间
import time
print(time.time())
struct_time = time.localtime(1573718106.3909602)
ret = time.strftime(‘%Y-%m-%d %H:%M:%S‘,struct_time)
print(ret)

字符串时间转成时间戳
import time
struct_time = time.strptime(‘2019-11-14‘,‘%Y-%m-%d‘)
print(struct_time)

查看一下1800000000时间戳表示的年月日
import time
struct_time = time.localtime(1800000000)
print(struct_time)
ret = time.strftime(‘%Y-%m-%d‘,struct_time)
print(ret)

将2019-11-14转换成时间戳
import time
struct_time = time.strptime(‘2019-11-14‘,‘%Y-%m-%d‘)
print(struct_time)
ret = time.mktime(struct_time)
print(ret)

计算时间差
2019-11-18 18:30:45
2019-11-19 10:10:36
这两个时间戳之间 经过了多长时分秒
import time
str_time1 = ‘2019-11-18 18:30:45‘
str_time2 = ‘2019-11-19 10:10:36‘
struct_t1 = time.strptime(str_time1,‘%Y-%m-%d %H:%M:%S‘)
struct_t2 = time.strptime(str_time2,‘%Y-%m-%d %H:%M:%S‘)
timestamp1 = time.mktime(struct_t1)
timestamp2 = time.mktime(struct_t2)
set = timestamp2 - timestamp1
print(set)
是和操作系统交互的模块
import os
# print(os.listdir(‘D:\pythonday‘))
file_list = os.listdir(‘D:\pythonday‘)
for path in file_list:
print(os.path.join(‘D:\pythonday‘,path))

exec/eval 执行的是字符串数据类型的python代码
os.system 和os.popen是执行字符串数据类型的命令行代码
os.system(‘dir‘) #执行操作系统的命令,没有返回值,就像实际的操作:我删除一个文件,创建一个文件夹
import os
ret = os.popen(‘dir‘) #popen适合做查看类型的操作
print(ret.read())

import os
#把路径中不符合规范的/,改成操作系统默认的格式
path = os.path.abspath(‘D:\pythonday\day17‘)
print(path)
#给能找到的相对路径改成绝对路径
path = os.path.abspath(‘day17‘)
print(path)

import os
path = os.path.split(‘D:\pythonday\day17‘)
print(path)

import os
ret1 = os.path.dirname(‘D:/pythonday/day17/os模块.py‘) #和os.path.split类似,只是split包含了路径及路径下的文件
ret2 = os.path.basename(‘D:/pythonday/day17/os模块.py‘)
print(ret1)
print(ret2)

判断文件或者文件夹是否存在
import os
res = os.path.exists(‘D:/pythonday/day17/os模块.py‘)
print(res)

判断一个文件是否在绝对路径下
import os
ret1 = os.path.isabs(‘D:/pythonday/day17/os模块.py‘)
ret2 = os.path.isabs(‘os模块.py‘)
print(ret1)
print(ret2)

判断是否存在这个文件或文件夹
import os
ret1 = os.path.isdir(‘D:/pythonday/day17/‘)
ret2 = os.path.isfile(‘D:/pythonday/day17/os66模块.py‘)
print(ret1)
print(ret2)

拼接某一个路径(不管是存在还是不存在的)
import os
path = os.path.join(r‘D:/pythonday/day17/‘,‘abc‘)
print(path)

获取某个文件或文件夹的大小
import os
size_file = os.path.getsize(‘D:\pythonday\day17\os模块.py‘)
print(size_file)
size_dir = os.path.getsize(‘D:\pythonday‘)
print(size_dir)

判断某一个文件夹下面文件的总大小(包括文件夹和文件大小)
import os
def func(path):
size_sum = 0
name_lst = os.listdir(path) #获取文件路径即:D:\pythonday
for name in name_lst: #进行D:\pythonday文件夹下,进行遍历,[day01],[day02],[day03],[day04]......
path_abs = os.path.join(path,name) #进行拼接,最后拼接成如:D:\pythonday\day01,D:\pythonday\day02......
if os.path.isdir(path_abs): #判断D:\pythonday下有没有这个文件,
size = func(path_abs) #判断若为true,此时path_abs = D:\pythonday\day01,又开始调用函数进行循环
size_sum = size_sum + size #返回所有文件夹的大小
else:
size_sum = size_sum + os.path.getsize(path_abs) #返回文件夹和文件夹下面所有文件的大小
return size_sum #谁调用返回谁的?
ret = func(r‘D:\pythonday‘) #调用函数,关键字参数传参
print(ret)
原文:https://www.cnblogs.com/Sy-blogs/p/12707132.html