精细化运营是针对人群、场景、流程做差异化细分运营的运营策略。
一般情况在产品进入稳定增长的阶段后,需要提升用户的覆盖,以更好的服务不同属性的用户,来提升运营效率和效果。
精细化运营中人群精细化尤为重要,精细化的前提是CRM(用户关系管理),而用户关系管理的核心即用户分类。
用户价值细分是了解用户分类的重要途径,针对不同价值度的用户进行差异化运营策略,以提升用户留存与活跃,实现精细化管理用户。
RFM模型:根据客户活跃度和交易金额,进行客户价值细分的一种方法。通过以下三个指标衡量客户价值和客户创利能力:
R - Recency 最近一次消费
F - Frequency 消费频率
M - Monetary 消费金额
某零售平台从2015年到2018年的用户订单抽样数据,数据在excel中包含5个sheet,前4个sheet是每年的交易订单数据,最后一个是用户的会员等级表
以下是数据集的5个特征变量,包括:
代码如下
import pandas as pd import numpy as np from sklearn.ensemble import RandomForestClassifier
4.2.1. 数据审查
基本思路
代码如下

# 读取数据 sheet_names = [‘2015‘, ‘2016‘, ‘2017‘, ‘2018‘, ‘会员等级‘] sheet_datas = [pd.read_excel(‘C:\\Users\HUAWEI\Desktop\python_book\chapter5\sales.xlsx‘, sheet_name=i) for i in sheet_names] # 数据审查: for each_name, each_data in zip(sheet_names, sheet_datas): print(‘data summary for {:=^50}‘.format(each_name)) print(‘Overview:‘, ‘\n‘, each_data.head()) print(‘DESC:‘, ‘\n‘, each_data.describe()) print(‘NA records:‘, each_data.isnull().any(axis=1).sum()) print(‘Dtypes:‘, ‘\n‘, each_data.dtypes)
运行结果(只截取2015年和会员等级的结果)
data summary for =======================2015======================= Overview: 会员ID 订单号 提交日期 订单金额 0 15278002468 3000304681 2015-01-01 499.0 1 39236378972 3000305791 2015-01-01 2588.0 2 38722039578 3000641787 2015-01-01 498.0 3 11049640063 3000798913 2015-01-01 1572.0 DESC: 会员ID 订单号 订单金额 count 3.077400e+04 3.077400e+04 30774.000000 mean 2.918779e+10 4.020414e+09 960.991161 std 1.385333e+10 2.630510e+08 2068.107231 min 2.670000e+02 3.000305e+09 0.500000 25% 1.944122e+10 3.885510e+09 59.000000 50% 3.746545e+10 4.117491e+09 139.000000 75% 3.923593e+10 4.234882e+09 899.000000 max 3.954613e+10 4.282025e+09 111750.000000 NA records: 0 Dtypes: 会员ID int64 订单号 int64 提交日期 datetime64[ns] 订单金额 float64 dtype: object data summary for =======================会员等级======================= Overview: 会员ID 会员等级 0 100090 3 1 10012905801 1 2 10012935109 1 3 10013498043 1 DESC: 会员ID 会员等级 count 1.543850e+05 154385.000000 mean 2.980055e+10 2.259701 std 1.365654e+10 1.346408 min 8.100000e+01 1.000000 25% 2.213894e+10 1.000000 50% 3.833022e+10 2.000000 75% 3.927932e+10 3.000000 max 3.954614e+10 5.000000 NA records: 0 Dtypes: 会员ID int64 会员等级 int64 dtype: object
4.2.2 初步分析
4.2.3 数据预处理
基本思路
代码如下
# 去除缺失值和异常值 for ind, each_data in enumerate(sheet_datas[:-1]): each_data = each_data.dropna() # 去除缺失值的记录 each_data = each_data[each_data[‘订单金额‘] > 1] # 去除订单金额<=1的记录 each_data[‘max_year_data‘] = each_data[‘提交日期‘].max() # 增加一列最大日期值 sheet_datas[ind] = each_data # 合并数据 data_merge = pd.concat(sheet_datas[:-1], axis=0) # 获取各自年份数据 data_merge[‘year‘] = data_merge[‘提交日期‘].dt.year # 新增一列每条记录发生的年份 data_merge[‘date_interval‘] = data_merge[‘max_year_data‘] - data_merge[‘提交日期‘] # 日期间隔 data_merge[‘date_interval‘] = data_merge[‘date_interval‘].apply(lambda x: x.days) # 时间间隔转换为数值型 # 按会员ID做汇总(分组,聚合) rfm_gb = data_merge.groupby([‘year‘, ‘会员ID‘], as_index=False).agg({‘date_interval‘: ‘min‘, ‘提交日期‘: ‘count‘, ‘订单金额‘: ‘sum‘}) # 重命名列名 rfm_gb.columns = [‘year‘, ‘会员ID‘, ‘r‘, ‘f‘, ‘m‘]
4.3.1 划分RFM区间
基本思路
代码如下
# 首先查看数据分布 desc_pd = rfm_gb.iloc[:, 2:].describe().T # 定义区间边界 r_bins = [-1, 79, 255, 365] f_bins = [0, 2, 5, 130] m_bins = [0, 69, 1199, 206252]
结果如下
count mean std min 25% 50% 75% max r 148591.0 165.524043 101.988472 0.0 79.0 156.0 255.0 365.0 f 148591.0 1.365002 2.626953 1.0 1.0 1.0 1.0 130.0 m 148591.0 1323.741329 3753.906883 1.5 69.0 189.0 1199.0 206251.8
4.3.2 结果分析
4.4.1 R、F、M分箱得分
基本思路
代码如下:
rfm_gb[‘r_score‘] = pd.cut(rfm_gb[‘r‘], r_bins, labels=[i for i in range(len(r_bins)-1, 0, -1)]) rfm_gb[‘f_score‘] = pd.cut(rfm_gb[‘f‘], f_bins, labels=[i+1 for i in range(len(f_bins)-1)]) rfm_gb[‘m_score‘] = pd.cut(rfm_gb[‘m‘], m_bins, labels=[i+1 for i in range(len(m_bins)-1)])
得分规则
4.4.2 RFM总分
基本思路
代码如下
# 方法一 # 匹配会员等级和rfm得分 rfm_merge = pd.merge(rfm_gb, sheet_datas[-1], on=‘会员ID‘, how=‘inner‘) # 使用merge方法合并两个数据框 # 通过RF(随机森林)获得rfm因子得分 clf = RandomForestClassifier() # 建立rf模型对象 clf = clf.fit(rfm_merge[[‘r‘, ‘f‘, ‘m‘]], rfm_merge[‘会员等级‘]) # 将rfm三列作为特征,会员等级作为目标,输入模型并进行训练 weights = clf.feature_importances_ # 返回值是列表形式 print(‘feature importance: ‘, weights) # 加权得分 rfm_gb = rfm_gb.apply(np.int32) # 类别型转换成数值 rfm_gb[‘rfm_score‘] = rfm_gb[‘r_score‘] * weights[0] + rfm_gb[‘f_score‘] * weights[1] + rfm_gb[‘m_score‘] * weights[2]
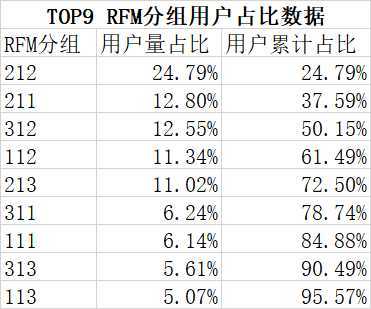
# 方法二 # RFM组合 rfm_gb[‘r_score‘] = rfm_gb[‘r_score‘].astype(np.str) rfm_gb[‘f_score‘] = rfm_gb[‘f_score‘].astype(np.str) rfm_gb[‘m_score‘] = rfm_gb[‘m_score‘].astype(np.str) rfm_gb[‘rfm_group‘] = rfm_gb[‘r_score‘].str.cat(rfm_gb[‘f_score‘]).str.cat(rfm_gb[‘m_score‘])
4.4.3 RFM因子权重
基本思路
结果分析
4.5 保存结果到Excel
代码如下:
rfm_gb.to_excel(‘sales_rfm_score.xlsx‘)
参考书籍:
《Python数据分析与数据化运营》(第二版)
原文:https://www.cnblogs.com/yanmai/p/12725792.html
