Kubernetes集群管理
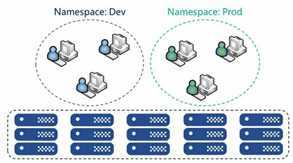
接下来,需要为这两个工作组分别定义一个 Context,即运行环 境。这个运行环境将属于某个特定的命名空间
通过kubectl config set-context命令定义Context,并将Context置于之 前创建的命名空间中

使用kubectl config use-context <context_name>命令设置当前运行环 境。
下面的命令将把当前运行环境设置为ctx-dev
kubectl config use-context ctx-dev
为了避免系统挂掉,该Node会选择“清理”某些Pod来释放资源,此 时每个Pod都可能成为牺牲品。但有些Pod担负着更重要的职责,比其他 Pod更重要,比如与数据存储相关的、与登录相关的、与查询余额相关 的,即使系统资源严重不足,也需要保障这些Pod的存活,Kubernetes中 该保障机制的核心如下
◎ 通过资源限额来确保不同的Pod只能占用指定的资源
◎ 允许集群的资源被超额分配,以提高集群的资源利用率。
◎ 为Pod划分等级,确保不同等级的Pod有不同的服务质量 (QoS),资源不足时,低等级的Pod会被清理,以确保高等级的Pod稳 定运行。
1.详解Requests和Limits参数.以CPU为例,图10.3显示了未设置Limits和设置了Requests、Limits 的CPU使用率的区别
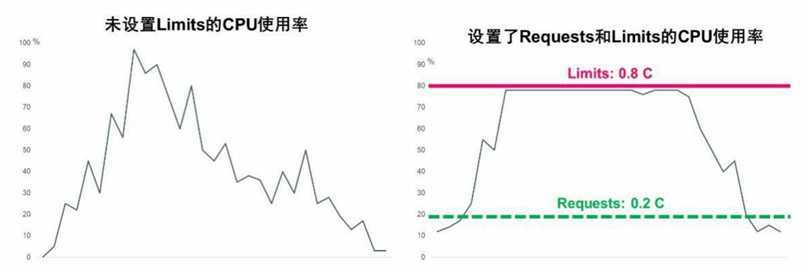
尽管Requests和Limits只能被设置到容器上,但是设置Pod级别的 Requests和Limits能大大提高管理Pod的便利性和灵活性,因此在 Kubernetes中提供了对Pod级别的Requests和Limits的配置对于CPU和 内存而言,Pod的Requests或Limits是指该Pod中所有容器的Requests或 Limits的总和(对于Pod中没有设置Requests或Limits的容器,该项的值 被当作0或者按照集群配置的默认值来计算)。下面对CPU和内存这两 种计算资源的特点进行说明
基于Requests和Limits的Pod调度机制
当一个Pod创建成功时,Kubernetes调度器(Scheduler)会为该Pod 选择一个节点来执行。对于每种计算资源(CPU和Memory)而言,每 个节点都有一个能用于运行Pod的最大容量值。调度器在调度时,首先 要确保调度后该节点上所有Pod的CPU和内存的Requests总和,不超过该 节点能提供给Pod使用的CPU和Memory的最大容量值
这里需要注意:可能某节点上的实际资源使用量非常低,但是已运 行Pod配置的Requests值的总和非常高,再加上需要调度的Pod的 Requests值,会超过该节点提供给Pod的资源容量上限,这时Kubernetes 仍然不会将Pod调度到该节点上。如果Kubernetes将Pod调度到该节点 上,之后该节点上运行的Pod又面临服务峰值等情况,就可能导致Pod资 源短缺。
kubelet在启动Pod的某个容器时,会将容器的Requests和Limits值转化为相应的容器启动参数传递给容器执行器(Docker或者rkt)
如果容器的执行环境是Docker,那么容器的如下4个参数是这样传 递给Docker的
1)spec.container[].resources.requests.cpu
这个参数会转化为core数(比如配置的100m会转化为0.1),然后 乘以1024,再将这个结果作为--cpu-shares参数的值传递给docker run命 令。在docker run命令中,--cpu-share参数是一个相对权重值(Relative Weight),这个相对权重值会决定Docker在资源竞争时分配给容器的资 源比例
这里需要区分清楚的是:这个参数对于Kubernetes而言是绝对值, 主要用于Kubernetes调度和管理;同时Kubernetes会将这个参数的值传递 给docker run的--cpu-shares参数。--cpu-shares参数对于Docker而言是相对 值,主要用于资源分配比例
2)spec.container[].resources.limits.cpu
这个参数会转化为millicore数(比如配置的1被转化为1000,而配置 的100m被转化为100),将此值乘以100000,再除以1000,然后将结果 值作为--cpu-quota参数的值传递给docker run命令。docker run命令中另 外一个参数--cpu-period默认被设置为100000,表示Docker重新计量和分 配CPU的使用时间间隔为100000μs(100ms)
Docker的--cpu-quota参数和--cpu-period参数一起配合完成对容器 CPU的使用限制:比如Kubernetes中配置容器的CPU Limits为0.1,那么 计算后--cpu-quota为10000,而--cpu-period为100000,这意味着Docker在100ms内最多给该容器分配10ms×core的计算资源用量,10/100=0.1 core 的结果与Kubernetes配置的意义是一致的
注意:如果kubelet的启动参数--cpu-cfs-quota被设置为true,那么 kubelet会强制要求所有Pod都必须配置CPU Limits(如果Pod没有配置, 则集群提供了默认配置也可以)。从Kubernetes 1.2版本开始,这个-- cpu-cfs-quota启动参数的默认值就是true
计算资源相关常见问题分析
(1)Pod状态为Pending,错误信息为FailedScheduling。如果Kubernetes调度器在集群中找不到合适的节点来运行Pod,那么这个Pod 会一直处于未调度状态,直到调度器找到合适的节点为止。每次调度器 尝试调度失败时,Kubernetes都会产生一个事件
对大内存页(Huge Page)资源的支持
在现代操作系统中,内存是以Page(页,有时也可以称之为 Block)为单位进行管理的,而不以字节为单位,包括内存的分配和回 收都基于Page。典型的Page大小为4KB,因此用户进程申请1MB内存就需要操作系统分配256个Page,而1GB内存对应26万多个Page!
为了实现快速内存寻址,CPU内部以硬件方式实现了一个高性能的 内存地址映射的缓存表——TLB(Translation Lookaside Buffer),用来 保存逻辑内存地址与物理内存的对应关系。若目标地址的内存页物理地 址不在TLB的缓存中或者TLB中的缓存记录失效,CPU就需要切换到低 速的、以软件方式实现的内存地址映射表进行内存寻址,这将大大降低 CPU的运算速度。针对缓存条目有限的TLB缓存表,提高TLB效率的最 佳办法就是将内存页增大,这样一来,一个进程所需的内存页数量会相 应减少很多。如果把内存页从默认的4KB改为2MB,那么1GB内存就只 对应512个内存页了,TLB的缓存命中率会大大增加。这是不是意味着 我们可以任意指定内存页的大小,比如1314MB的内存页?答案是否定 的,因为这是由CPU来决定的,比如常见的Intel X86处理器可以支持的 大内存页通常是2MB,个别型号的高端处理器则支持1GB的大内存页
在Linux平台下,对于那些需要大量内存(1GB以上内存)的程序 来说,大内存页的优势是很明显的,因为Huge Page大大提升了TLB的 缓存命中率,又因为Linux对Huge Page提供了更为简单、便捷的操作接 口,所以可以把它当作文件来进行读写操作。Linux使用Huge Page文件 系统hugetlbfs支持巨页,这种方式更为灵活,我们可以设置Huge Page的 大小,比如1GB、2GB甚至2.5GB,然后设置有多少物理内存用于分配 Huge Page,这样就设置了一些预先分配好的Huge Page。可以将 hugetlbfs文件系统挂载在/mnt/huge目录下,通过执行下面的指令完成设 置
mkdir /mnt/huge mount -t hugetlbfs nodev /mnt/huge
在设置完成后,用户进程就可以使用mmap映射Huge Page目标文件 来使用大内存页了,Intel DPDK便采用了这种做法,测试表明应用使用 大内存页比使用4KB的内存页性能提高了10%~15%
Kubernetes 1.14版本对Linux Huge Page的支持正式更新为GA稳定 版。我们可以将Huge Page理解为一种特殊的计算资源:拥有大内存页 的资源。而拥有Huge Page资源的Node也与拥有GPU资源的Node一样, 属于一种新的可调度资源节点(Schedulable Resource Node)
Huge Page也支持ResourceQuota来实现配额限制,类似CPU或者 Memory,但不同于CPU或者内存,Huge Page资源属于不可超限使用的 资源,拥有Huge Page能力的Node会将自身支持的Huge Page的能力信息 自动上报给Kubernetes Master
为此,Kubernetes引入了一个新的资源类型hugepages-<size>,来表 示大内存页这种特殊的资源,比如hugepages-2Mi表示2MiB规格的大内 存页资源。一个能提供2MiB规格Huge Page的Node,会上报自己拥有 Hugepages-2Mi的大内存页资源属性,供需要这种规格的大内存页资源 的Pod使用,而需要Huge Page资源的Pod只要给出相关的Huge Page的声 明,就可以被正确调度到匹配的目标Node上了。相关例子如下

apiVersion: v1
kind: Pod
metadata:
generateName: hugepages-volume-
spec:
containers:
- image: fedora:latest
command:
- sleep:
- inf
name: example
volumeMounts:
- mountPath: /hugepages
name: hugepage
resource:
limits:
hugepages-2Mi: 100Mi
memory: 100Mi
request:
memory:100Mi
volumes:
- name: hugepage
emptyDir:
medium: HugePages
Kubernetes提供了LimitRange机制对Pod和容器的 Requests和Limits配置进一步做出限制。在下面的示例中,将说明如何 将LimitsRange应用到一个Kubernetes的命名空间中,然后说明 LimitRange的几种限制方式,比如最大及最小范围、Requests和Limits的 默认值、Limits与Requests的最大比例上限等
apiVersion: v1 kind: LimitRange metadata: name: mylimits spec: limits: - max: cpu: "4" memory: 2Gi min: cpu: 200m memory: 6Mi maxLimitRequestRatio: cpu: 3 memory: 2 type: Pod - default: cpu: 300m memory: 200Mi defaultRequest: cpu: 200m memory: 100Mi max: cpu: "2" memory: 1Gi min: cpu: 100m memory: 3Mi maxLimitRequestRatio: cpu: 5 memory: 4 type: Container
不论是CPU还是内存,在LimitRange中,Pod和Container都可 以设置Min、Max和Max Limit/Requests Ratio参数。Container还可以设置 Default Request和Default Limit参数,而Pod不能设置Default Request和 Default Limit参数
对Pod和Container的参数解释如下
◎ Container的Min(上面的100m和3Mi)是Pod中所有容器的 Requests值下限;Container的Max(上面的2和1Gi)是Pod中所有容器的 Limits值上限;Container的Default Request(上面的200m和100Mi)是 Pod中所有未指定Requests值的容器的默认Requests值;Container的 Default Limit(上面的300m和200Mi)是Pod中所有未指定Limits值的容 器的默认Limits值。对于同一资源类型,这4个参数必须满足以下关系: Min ≤ Default Request ≤ Default Limit ≤ Max
◎ Pod的Min(上面的200m和6Mi)是Pod中所有容器的Requests 值的总和下限;Pod的Max(上面的4和2Gi)是Pod中所有容器的Limits 值的总和上限。当容器未指定Requests值或者Limits值时,将使用
◎ Container的Max Limit/Requests Ratio(上面的5和4)限制了Pod 中所有容器的Limits值与Requests值的比例上限;而Pod的Max Limit/Requests Ratio(上面的3和2)限制了Pod中所有容器的Limits值总 和与Requests值总和的比例上限
如果设置了Container的Max,那么对于该类资源而言,整个 集群中的所有容器都必须设置Limits,否则无法成功创建。Pod内的容器 未配置Limits时,将使用Default Limit的值(本例中的300m CPU和 200MiB内存),如果也未配置Default,则无法成功创建。
如果设置了Container的Min,那么对于该类资源而言,整个集 群中的所有容器都必须设置Requests。如果创建Pod的容器时未配置该类 资源的Requests,那么在创建过程中会报验证错误。Pod里容器的 Requests在未配置时,可以使用默认值defaultRequest(本例中的200m CPU和100MiB内存);如果未配置而又没有使用默认值 defaultRequest,那么会默认等于该容器的Limits;如果此时Limits也未 定义,就会报错。
对于任意一个Pod而言,该Pod中所有容器的Requests总和必 须大于或等于6MiB,而且所有容器的Limits总和必须小于或等于1GiB; 同样,所有容器的CPU Requests总和必须大于或等于200m,而且所有容 器的CPU Limits总和必须小于或等于2
Pod里任何容器的Limits与Requests的比例都不能超过 Container的Max Limit/Requests Ratio;Pod里所有容器的Limits总和与 Requests的总和的比例不能超过Pod的Max Limit/Requests Ratio
apiVersion: v1 kind: Pod metadata: name: invalid-pod namespace: test spec: containers: - name: kubernetes-serve-hostbame image: nginx resources: limits: cpu: "3" memory: 100Mi

apiVersion: v1 kind: Pod metadata: name: limit-test-nginx namespace: test labels: name: limit-test-nginx spec: containers: - name: limit-test-nginx image: nginx resources: limits: cpu: "1" memory: 512Mi requests: cpu: "0.8" memory: 250Mi

原文:https://www.cnblogs.com/qinghe123/p/12739237.html