论文地址 :https://www.aclweb.org/anthology/P19-1563/
作者 : Jie Cao, Michael Tanana, Zac Imel, Eric Poitras, David Atkins, Vivek Srikumar
机构 : 犹他大学,华盛顿大学
研究的问题:
关注的是对话分析在心理治疗领域的应用。具体包括两个任务:
(1)分类:预测医生和患者对话的MISC(Motivational Interviewing Skill Codes)标签来监控正在进行的对话。
(2)预测:给定一个对话历史,预测下一句的MISC标签。
也就是本系统作为一个助手,以MISC标签的形式来给医生提供帮助。
下面是MISC的一个例子。
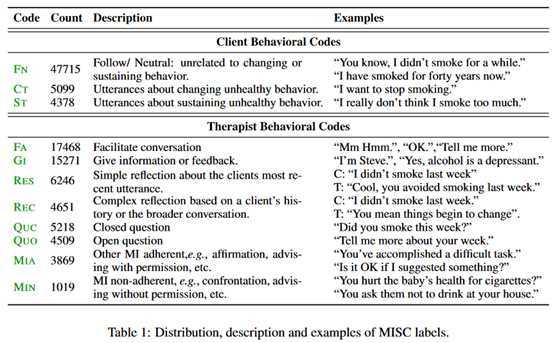
研究方法:
任务定义:输入包括对话语句u_1,…,u_n,对话历史H_n。每个语句所对应的讲话人(C-client,T-therapist)和对应的MISC标签。任务包括两个部分:
(1)分类。给定对话历史,对最后一句分类MISC标签。
(2)预测。给定对话历史,下一个说话者的身份,预测下一个话语的MISC标签。
模型:
(1)编码器:层次双向GRU。(hierarchical GRU)
(2)词级别注意力机制
用v_ij定义对话历史的第i个句子的第n个词(queries),则v_nk表示最后一句的第k个词(keys),则keys到queries的attention定义如下:;
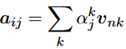
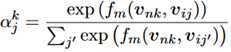
这里的f_m是匹配函数。得到了这个attention向量之后,和原来的词向量组合起来作为最终的向量表示,
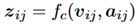
这里的f_c是组合函数,f_m和f_c都可以有不同的实现方式,具体如下:

(3)句子级别注意力机制
用的是Transformer中的multi-head attention。
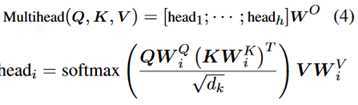
这里讨论了两种方式,一种就是原始的multi-head attention,记为SELF42。另一种是Q=[v_n],也就是最后一句话,K=V=[v_1,…,v_n],记为ANCHOR42.
(4)标签不平衡的问题
在患者和医生的各自的对话中,存在标签不平衡的现象。方法是引入focal loss,并扩展到多类别的情况。对于一个模型p_t,定义如下:
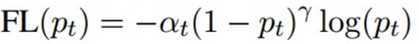
这里的α、γ都是超参数。
实验部分:
数据:包括242个训练对话和11个测试对话,每个对话约包含500个句子。
评估指标:F1
实验设置:经过实验,最终最好的实验设置是,在分类任务上,对于患者数据,不适用单词attention也不用句子attention。对于医生数据,用GMGRU表示词attention,用ANCHOR42表示句子attention。在预测任务上,不使用词注意力,使用SELF42的句子注意力。
实验结果:
患者数据上的分类结果:
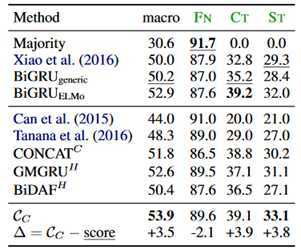
这里绿色的标签是具体的MISC标签。
医生数据上的分类结果:
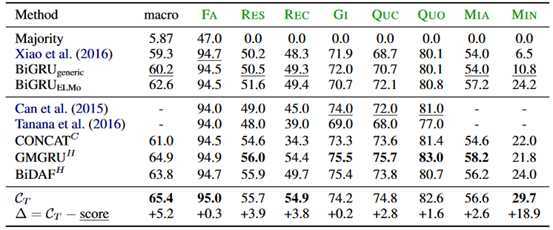
预测任务上的结果:
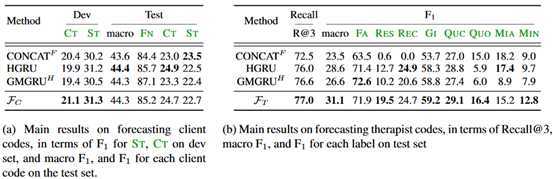
这部分任务是新的,所以不存在跟baseline的对比。
评价:
本文所作的预测任务是个开创性的工作。模型上主要是使用了词语粒度和句子粒度的两种attention方式,不过最终的结果发现帮助并不大。比如在患者的分类数据上,最好的结果是不使用词语注意力也不使用句子注意力。这部分作者没有给出具体的数据来说明每种attention具体对结果有什么影响。
论文阅读 | Observing Dialogue in Therapy: Categorizing and Forecasting Behavioral Codes
原文:https://www.cnblogs.com/bernieloveslife/p/12749010.html