一、设计方案
1.主题式网络爬虫名称:爬取B站全站日榜前20数据进行数据分析与可视化
2.爬取内容与数据特征分析:爬取B站日榜排名前20数据包括排名、事件、热度,数据未呈一定规律排序。
3.设计方案概述:思路:首先打开目标网站,运用工具查看源代码,寻找数据标签,通过写爬虫代码爬取所要的数据,将数据保存为csv文件,读取csv文件对数据进行整理、可视化操作。
难点:网站数据的实时更新;寻找数据标签;对数据整理、可视化等代码的掌握程度较低。
二、主题页面的结构特征分析
1.主题页面的结构与特征:爬取数据分布于a标签中,热度标签为td。
2.Htmls页面解析
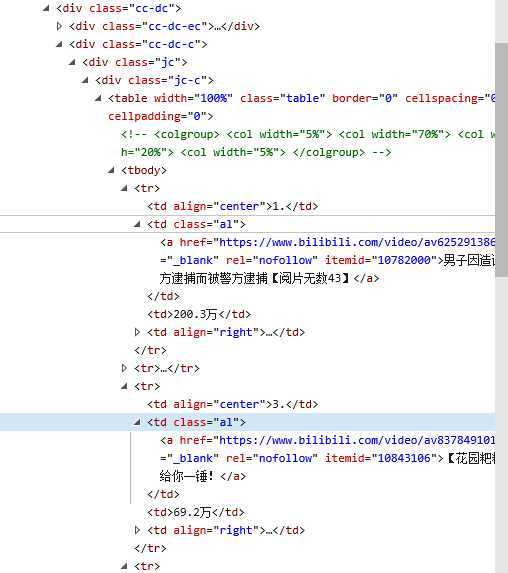
3.节点(标签)查找方法与遍历方法:通过re模块的findall方法进行查找。
三、程序设计
1.数据爬取与采集
import re import requests import pandas as pd url = ‘https://tophub.today/n/74KvxwokxM‘ #网站数据 headers = {‘user-Agent‘:""} #伪装爬虫 response=requests.get(url,headers=headers,timeout=30) #设置延迟 response = requests.get(url,headers = headers) #请求页面 #爬取内容 html = response.text titles = re.findall(‘<a href=".*?">.*?(.*?)</a>‘,html)[4:24] heat = re.findall(‘<td>(.*?)</td>‘,html)[0:20] x = {‘标题‘:titles,‘热度‘:heat} y = pd.DataFrame(x) data=[] #创建空列表 for i in range(20): data.append([i+1,titles[i],heat[i][:]]) #拷贝数据 file=pd.DataFrame(data,columns=[‘排名‘,‘bilibili热榜‘,‘热度‘]) print(file) file.to_csv(‘D:\\bbc\\bilibili热榜.csv‘) #保存文件

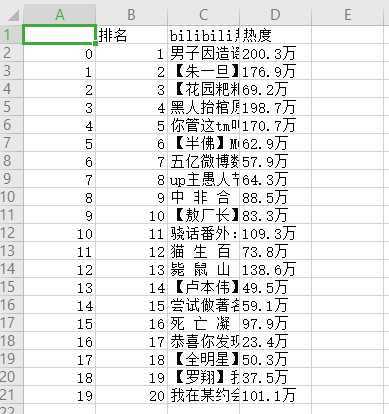
2.对数据进行清洗和处理
#读取csv文件 df = pd.DataFrame(pd.read_csv(‘bilibili热榜.csv‘)) df.head()

#删除无效行列 df.drop(‘bilibili热榜‘,axis=1,inplace=True) df.head

#缺失值处理 df.isnull().head() #True为缺失值,False为存在值

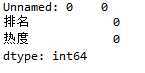
#空值处理 df.isnull().sum() #0表示无空值
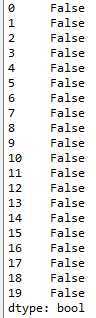
#查找重复值 df.duplicated() #显示表示已经删除重复值
原文:https://www.cnblogs.com/fxc0210/p/12726282.html