正则表达式:
正则表达式是regular expression(规则表达式),定义字符串规则的表达式,语法基于一种古老的perl语言,它描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
一个理念:任何程序都可以不用正则表达式写出来。但根据懒人原则,怎么做不言而喻。
语法:
text是正则的API,验证是否满足
第一种写法:new
var reg = new RegExp(‘’)
例:

第二种写法:字面量,在两条斜线中间创建正则,中间不加引号,而且两条斜线之间的任意字符都是有含义的
var reg = /a/
特殊字符:
[ ]中括号:匹配其中的某一个字符
例:[abcde] 匹配abcde其中任意一个
[a-z] 匹配所有小写字母
[0-9] 匹配任意一个数字
( ) 小括号:分组:小括号里面的内容作为整体进行匹配
小括号用于分组,竖线作为间隔代表“或者”的含义
/(ab) | (cd)/ 匹配’ab’ 或者 ‘cd’
/(a|b)cd/ 匹配 ‘acd’ 或者 ‘bcd’
注意:小括号、竖线不要放在 [ ] 内(无意义)
| :或,跟js中的(||)一样
^ :排除(除了)类似js中的(!)
^ (不在中括号里)匹配字符串开头
$ 匹配结尾
/^ $/ 这样的正则代表完整匹配
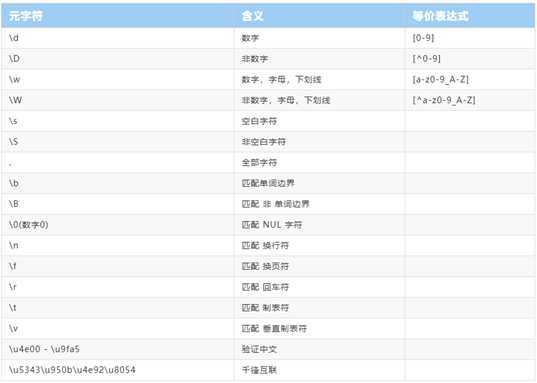
转义字符:元字符
所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
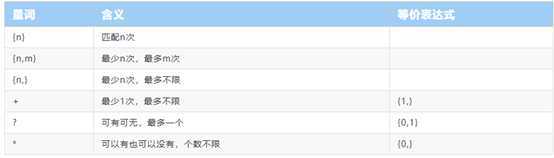
量词
正则表达式的一个符号块只能匹配文本中的一个符号,如果要多次匹配那么我们就需要量词。
修饰符:
修饰符 i :代表让正则不区分大小写
例:var re = new RegExp(‘a‘, ‘i‘)
var re= /a/i
修饰符g:代表全局查找
例:var reg = new RegExp(‘\d+‘, ‘g‘)
var reg = /\d+/ g
修饰符m:代表多行查找
直接量字符:
正则中有一些字符本身是具有含义的,那么如果我们要匹配这个字符就需要用到 \ 转义。
例:\/ 匹配/ \? 匹配?
\. 匹配.
正则对象的API
1.text方法:
作用:用来测试某个字符串是否与正则匹配,匹配返回true,否则返回false。
2.compile(不常用)
作用:能够对正则表达式进行编译,被编译过的正则在使用时效率更高,适合于对一个正则多次调用的情况。
3.exec(不常用)
作用:返回的是一个数组,数组元素为匹配的子字符串
支持正则的字符串API
1.search,支持正则的indexOf
查找第一次匹配的子字符串的位置,如果找到就返回一个number类型的index值,否则返回-1
2.split
将一个字符串拆分成一个数组,它接受一个正则或者子字符(串)作为参数,返回一个数组
3.match
接收一个正则作为参数,用来匹配一个字符串,返回一个满足正则的所有字符串的数组
4.replace(最常用)
该方法用来将字符串中的某些子串替换为需要的内容,接受两个参数,第一个参数可以为正则或者子字符串,表示匹配需要被替换的内容,第二个参数为被替换的新的子字符串。
正则案例:
固话规则 0421-6600656开头为0的2或者三位数字加上- 开头为非零的八位数字结尾是1到4位的分机号
/^0\d{2,3}-[1-9]\d{7}\d{1,4}?$/
邮箱验证
/^[0-9a-z]\w+@[0-9a-z]+\.[0-9a-z]+$/i
匹配网址URL的正则表达式
/^http(s)?:\/\/[a-z]{3,5}\.\w+\.\w+(\/.+)*$/
配首尾空格的正则表达式
/^\s+.*\s+$/
只能输入汉字
[\u4e00-\u9fa5]
删除多余空格
str.replace(/\s+/g,‘‘)
删除首尾空格
str.replace(/^\s+/,‘‘)
str.replace(/\s+$/,‘‘)
原文:https://www.cnblogs.com/52580587zl/p/12750721.html