ElasticSearch 是面向文档的。
RDBMS 和 ElasticSearch 客观对比:
| RDBMS | ElasticSearch |
|---|---|
| 数据库(Database) | 索引(Index) |
| 表(Table) | Type(即将弃用) |
| 行(Row) | Document |
| 字段(Column) | Field |
ElasticSearch 中可以包含多个索引,每个索引中可以包含多个类型,每个类型下面又包含多个文档,每个文档中又包含多个字段。
物理设计
ElasticSearch(集群) 在后台把每个索引划分成多个分片,每个分片可以在集群中的不同服务器之间迁移。
逻辑设计
一个索引类型中,包含多个文档。比如说文档1、文档2、.... 。当我们索引一篇文档时,可以通过这样的顺序找到它:索引?类型?文档ID(这里的ID不是整数,而是一个字符串),通过这个组合我们就能索引到某个具体的文档。
索引是映射类型的容器,ElasticSearch 中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置,然后它们被存储到了各个分片上。
物理设计:节点和分片如何工作
一个集群至少有一个主节点,而一个节点就是一个 ElasticSearch 进程。节点可以有多个索引,如果你创建索引,那么索引将会有 5 个分片(Primary Shard,又称主分片)构成的,每一个分片会有一个副本(Replica Shard,又称复制分片)。
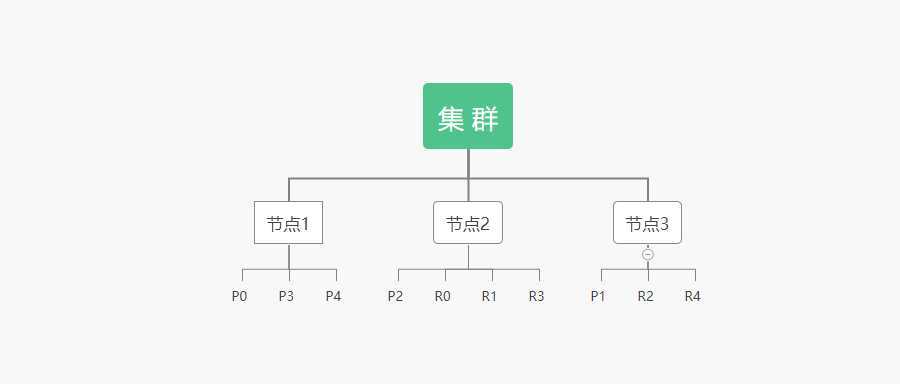
上图是一个有 3 个节点的 ElasticSearch 集群,可以看见主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上,一个分片是一个 Lucene 索引,一个包含倒排索引的文件目录,倒排索引的结构使得 ElasticSearch 在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。
倒排索引(重要)
ElasticSearch 使用的是一种称之为 倒排索引 的结构,采用 Lucene 倒排索引作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有包含它的文档列表。
例如:现在有两个文档,每个文档包含如下内容:
be careful, come back, get to # 文档1的内容
come from, be free, have a talk # 文档2的内容
为了创建倒排索引, 首先要将每个文档拆分成独立的词(或称为词条或 tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
| term | doc_1 | doc_2 |
|---|---|---|
| be | √ | √ |
| careful | √ | × |
| com | √ | √ |
| back | √ | × |
| get | √ | × |
| to | √ | × |
| from | × | √ |
| free | × | √ |
| have | × | √ |
| a | × | √ |
| talk | × | √ |
现在我们需要搜索 be free,只需要查看包含每个词条的文档
| term | doc_1 | doc_2 |
|---|---|---|
| be | √ | √ |
| free | × | √ |
| total | 1 | 2 |
两个文档都匹配,但是第二个文档比第一个文档匹配程度更高。如果没有其它条件,这两个包含关键字的文档都将返回。
再比如博客可以通过标签来搜索博客文章,那么倒排索引列表就是这样一个结构:
| 博客文章(原始数据) | |
|---|---|
| 博客文章ID | 标签 |
| 1 | Java |
| 2 | Python |
| 3 | TypeScript |
| 4 | Go |
| 5 | Java, Python |
| 6 | JavaScript, TypeScript |
| 索引列表(倒排索引) | |
|---|---|
| 标签 | 博客文章ID |
| Java | 1, 5 |
| Python | 2, 5 |
| Go | 4 |
| JavaScrpt | 6 |
| TypeScript | 6 |
如果要搜索含有 Java 标签的文章,那相对与查找所有原始数据而言,查找倒排索引后的数据将会快得多,只需要查看标片这一栏,然后获取相关的文章ID即可,过滤掉无关的文章,提高效率
ElasticSearch 的索引和 Lucene 的索引对比:
在 ElasticSearch 中,索引这个词被频繁使用,这就是术语的使用。在 ElasticSearch 中,索引被分为多个分片,每个分片是一个 Lucene 的索引,所以一个 ElasticSearch 索引是由多个 Lucene 索引组成的。
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义成为映射,比如 name 映射为字符串类型。文档无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段。那么 ElasticSearch 是怎么做到的呢?ElasticSearch 会自动的将新字段加入映射,但是这个字段不确定它是什么类型,ElasticSearch 就开始猜测,如果这个值是18,那么 ElasticSearch 会任何它是整形。但是 ElasticSearch 也可能猜不对,所以最安全的方式就是提前定义好所需要的映射。
文档是可以被索引的基本数据单位。存储在 ElasticSearch 中的主要实体叫文档 document,可以理解为关系型数据库中表的一行记录。在 ElasticSearch 中,文档有几个重要的属性:
尽管我们可以随意的新增或忽略某个字段,但是每个字段的类型非常重要。比如一个年龄字段类型可以是整数也可以是字符串,因为 ElasticSearch 会保存字段和类型之间的映射和其他的设置。
分词:即把一段中文或其他语言拆分成一个个的关键字,我们在搜索的时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词器是将每个字看作一个词。比如 "引导未来" 会被拆分成 ”引“,”导“,”未“,”来“,这显然是不符合要求的,所以我们需要安装中文分词器 IK 来解决这个问题。
? 如果使用中文,推荐使用 IK 分词器!
IK 提供了两种分词算法:
在 docker-compose.yml 同级目录下新建一个文件夹 plugins
touyel@server:/usr/local/docker/elasticsearch$ ls
docker-compose.yml
touyel@server:/usr/local/docker/elasticsearch$ pwd
/usr/local/docker/elasticsearch
touyel@server:/usr/local/docker/elasticsearch$ sudo mkdir plugins
touyel@server:/usr/local/docker/elasticsearch$ ls
docker-compose.yml plugins
修改 docker-compose.yml 文件:
version: ‘3.1‘
services:
elasticsearch:
image: elasticsearch:7.6.2
container_name: elasticsearch
restart: always
environment:
discovery.type: single-node
# 增加数据卷
volumes:
- ./plugins:/usr/share/elasticsearch/plugins
ports:
- 9200:9200
- 9300:9300
kibana:
image: kibana:7.6.2
container_name: kibana
environment:
ELASTICSEARCH_URL: "127.0.0.1:9200"
I18N_LOCALE: "zh-CN"
ports:
- 5601:5601
到 GitHub 上下载 elasticsearch-analysis-ik,注意与 ElasticSearch 版本对应
解压后上传到 plugins 目录下
为了防止权限不足导致上传失败,先获取 plugins 目录的所有权限:
sudo chmod 777 plugins/
然后再进行上传
重启 ElasticSearch,观察:
docker-compose down
docker-compose up -d
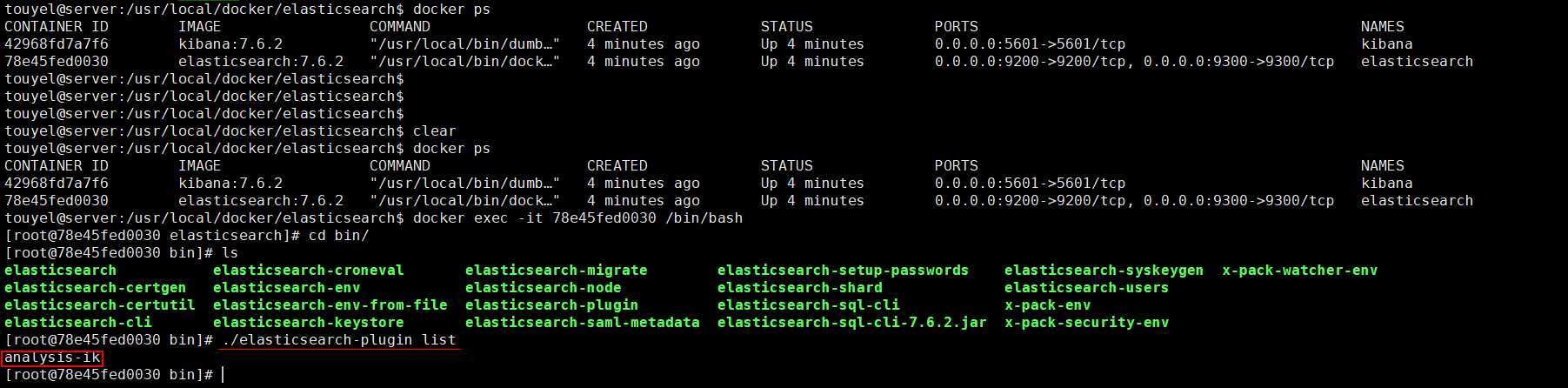
docker-compose logs | grep "loaded plugin"
# 可以看见,加载了 IK 分词器插件
elasticsearch | {"type": "server", "timestamp": "2020-04-22T12:35:19,584Z", "level": "INFO", "component": "o.e.p.PluginsService", "cluster.name": "docker-cluster", "node.name": "78e45fed0030", "message": "loaded plugin [analysis-ik]" }
进入 ElasticSearch 容器使用 elasticsearch-plugins 命令查看下:
最少切分
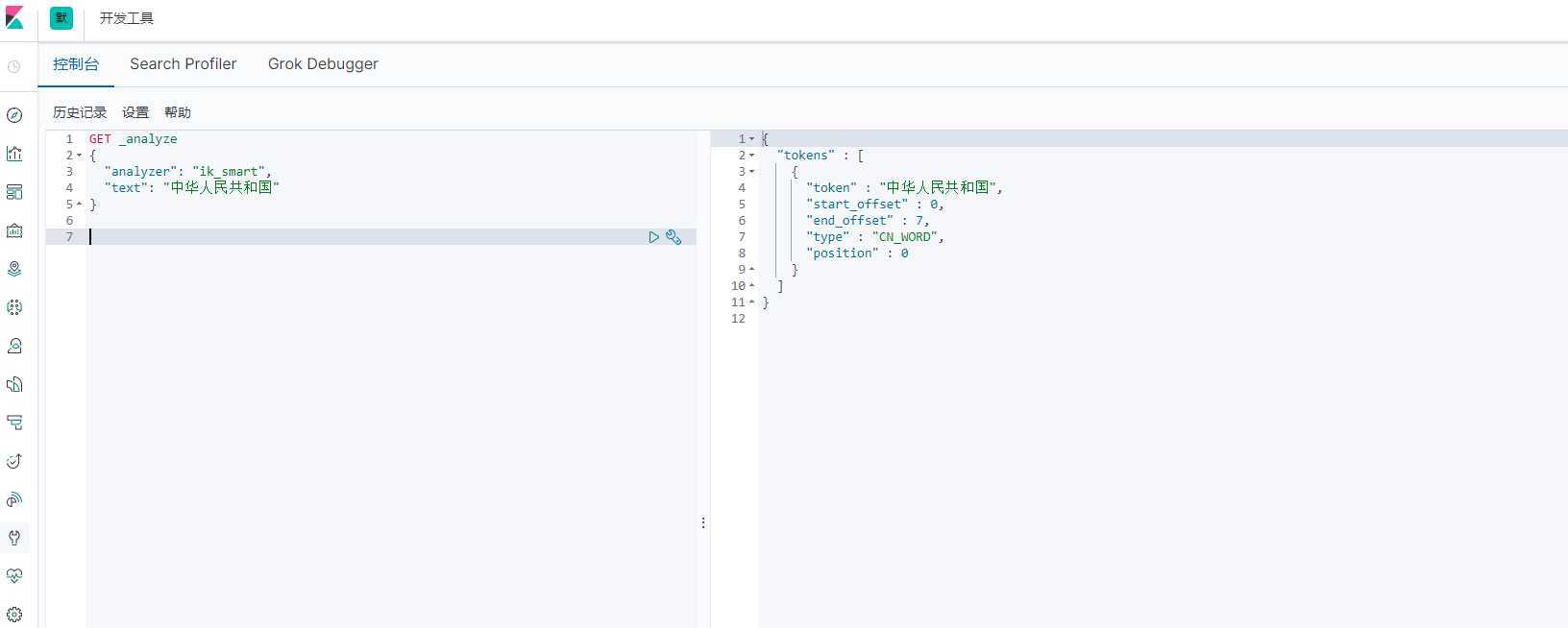
最细粒度划分
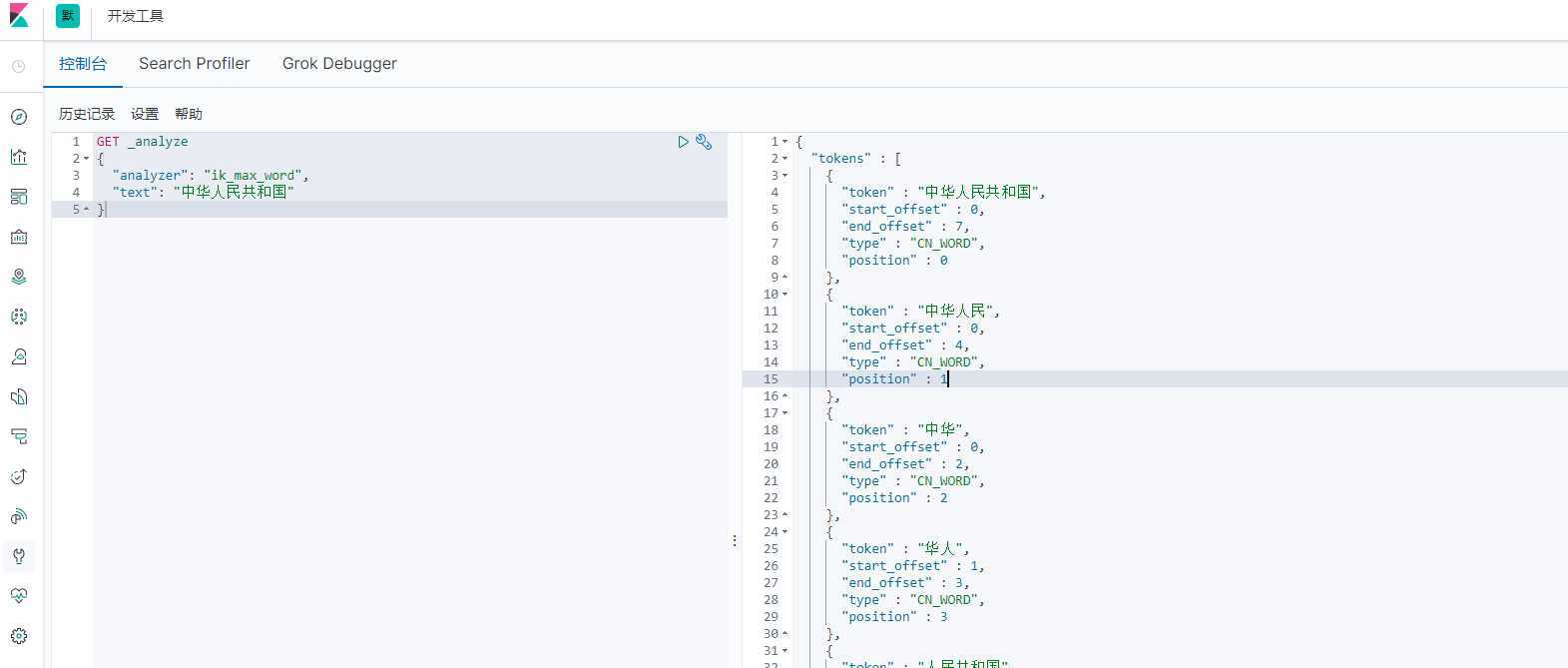
搜索:我是混子叶
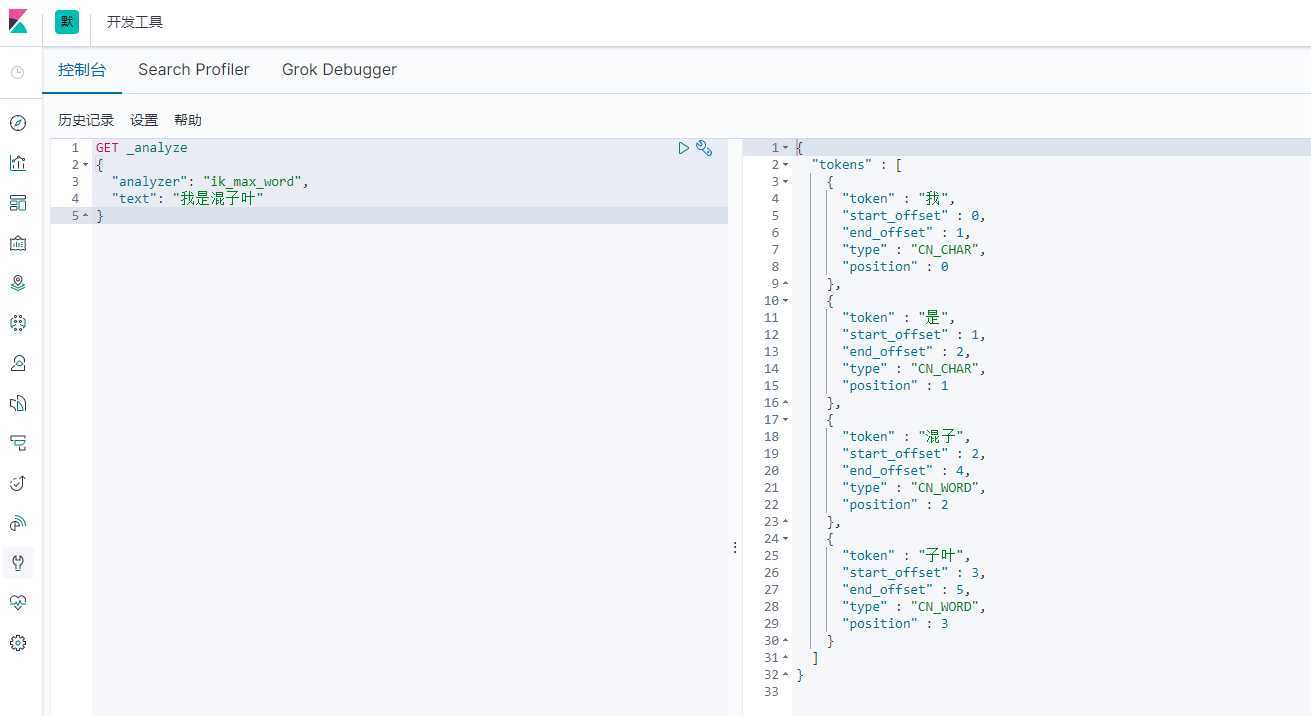
发现问题:我想 ”混子叶“ 成为一个词,怎么办?
这种自己需要的词,需要自己加到分词器的字典中!
IK 分词器增加自己的配置
1、进入 IK 分词器的配置目录
touyel@server:/usr/local/docker/elasticsearch$ ls
docker-compose.yml plugins
touyel@server:/usr/local/docker/elasticsearch$ cd plugins/analysis-ik/config/
touyel@server:/usr/local/docker/elasticsearch/plugins/analysis-ik/config$ ls
extra_main.dic extra_single_word_full.dic extra_stopword.dic main.dic quantifier.dic suffix.dic
extra_single_word.dic extra_single_word_low_freq.dic IKAnalyzer.cfg.xml preposition.dic stopword.dic surname.dic
touyel@server:/usr/local/docker/elasticsearch/plugins/analysis-ik/config$ ll
total 8268
drwxrwxr-x 2 touyel touyel 4096 Apr 22 20:32 ./
drwxrwxr-x 3 touyel touyel 4096 Apr 22 20:32 ../
-rw-rw-r-- 1 touyel touyel 5225922 Apr 22 20:32 extra_main.dic
-rw-rw-r-- 1 touyel touyel 63188 Apr 22 20:32 extra_single_word.dic
-rw-rw-r-- 1 touyel touyel 63188 Apr 22 20:32 extra_single_word_full.dic
-rw-rw-r-- 1 touyel touyel 10855 Apr 22 20:32 extra_single_word_low_freq.dic
-rw-rw-r-- 1 touyel touyel 156 Apr 22 20:32 extra_stopword.dic
-rw-rw-r-- 1 touyel touyel 625 Apr 22 20:32 IKAnalyzer.cfg.xml
-rw-rw-r-- 1 touyel touyel 3058510 Apr 22 20:32 main.dic
-rw-rw-r-- 1 touyel touyel 123 Apr 22 20:32 preposition.dic
-rw-rw-r-- 1 touyel touyel 1824 Apr 22 20:32 quantifier.dic
-rw-rw-r-- 1 touyel touyel 164 Apr 22 20:32 stopword.dic
-rw-rw-r-- 1 touyel touyel 192 Apr 22 20:32 suffix.dic
-rw-rw-r-- 1 touyel touyel 752 Apr 22 20:32 surname.dic
2、新建一个 touyel.dic 文件,文件名自己随便写一个就行,最好有意义。
sudo vim touyel.dic
输入自己的词,比如我想 ”混子叶“ 成为一个词。
# touyel.dic
混子叶
3、编辑 IKAnalyzer.cfg.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<!--添加我们自己的字典 -->
<entry key="ext_dict">touyel.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
4、重启 ElasticSearch
docker-compose down
docker-compose up -d
查看日志,发现加载了我们自己的字典!

启动成功后,进入 kinaba 测试:
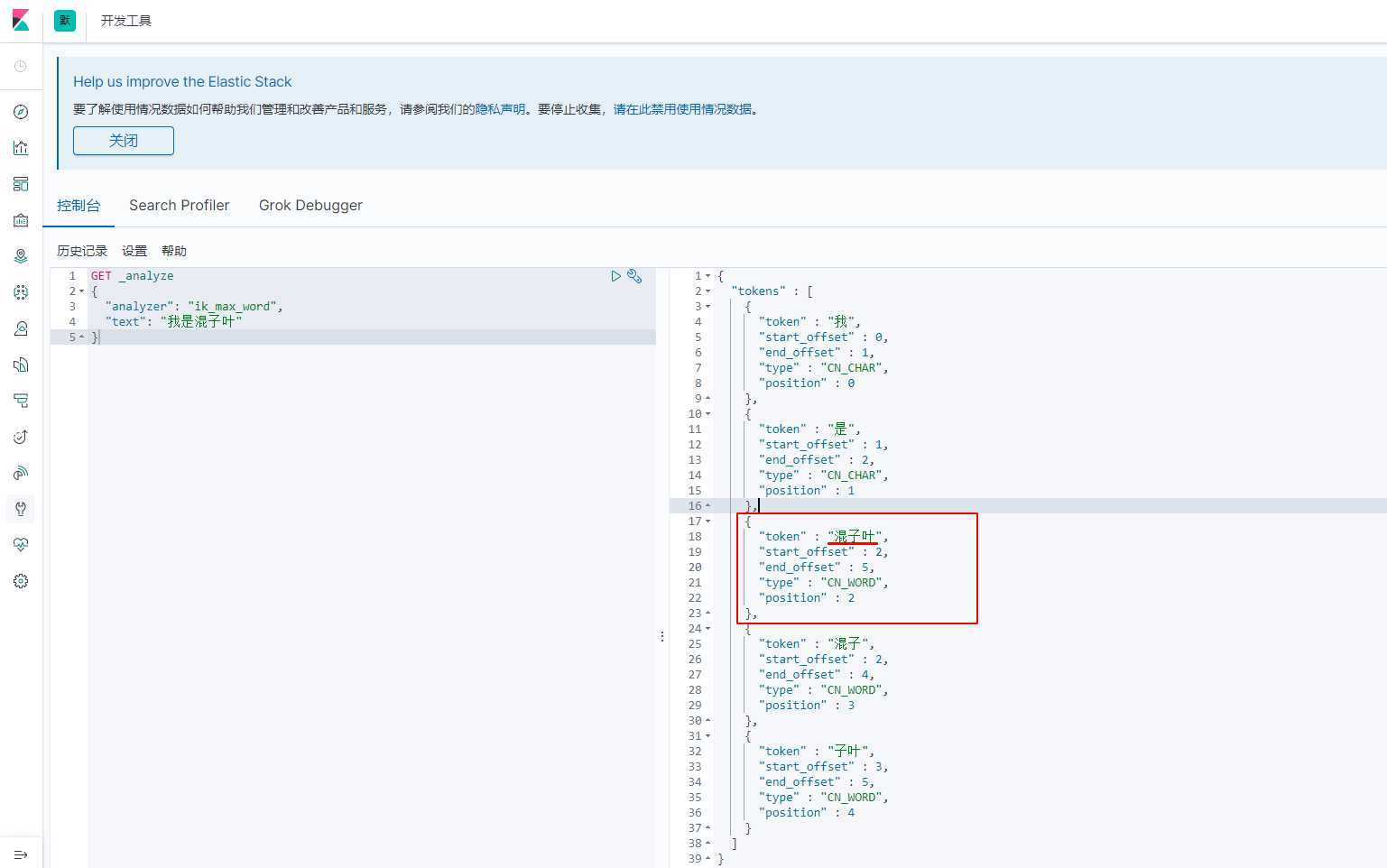
Nice!??
ElasticSearch 副本-02【ES 核心概念及 IK 分词器】
原文:https://www.cnblogs.com/touyel/p/12756385.html