一.主题式网络主题式网络爬虫设计方案
1.爬虫名称:爬取百度热搜榜Top50
2.爬取内容:热点排名,热门标题,搜索热度
3.网络爬虫设计方案概述:
思路:通过分析网页源代码,找出数据所在的标签,通过爬虫读取数据保存到excel文件中,读取文件,对数据进行清洗和处理,数据分析与可视化处理。
技术难点:掌握知识不够,操作过于生疏,对网页爬取还有很多疑问
二.主题页面的结构特征分析
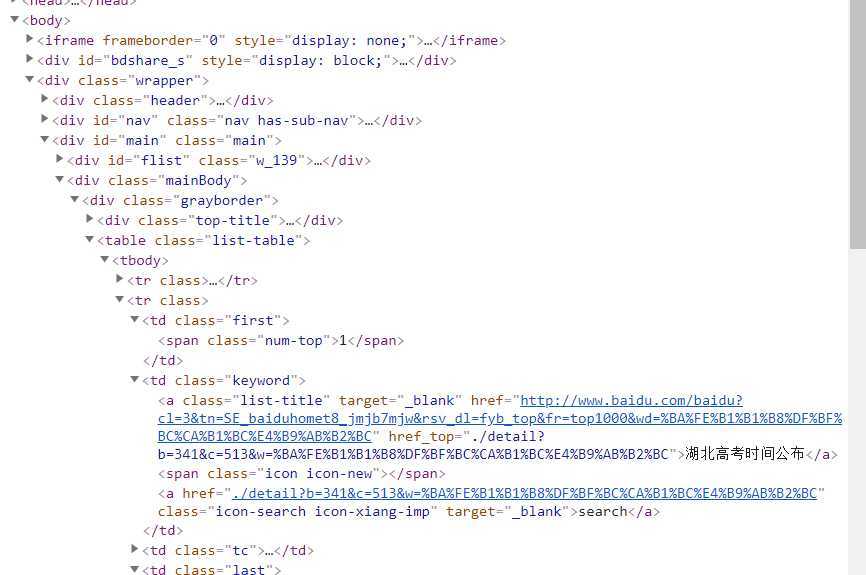
1.主题页面的结构与特征分析:爬取数据都分布在标签‘<div class="wrapper">…</div>‘里面,排名标签为num-top,标题标签为‘list-title‘,热度标签为‘icon-rise‘
2.Htmls页面解析:
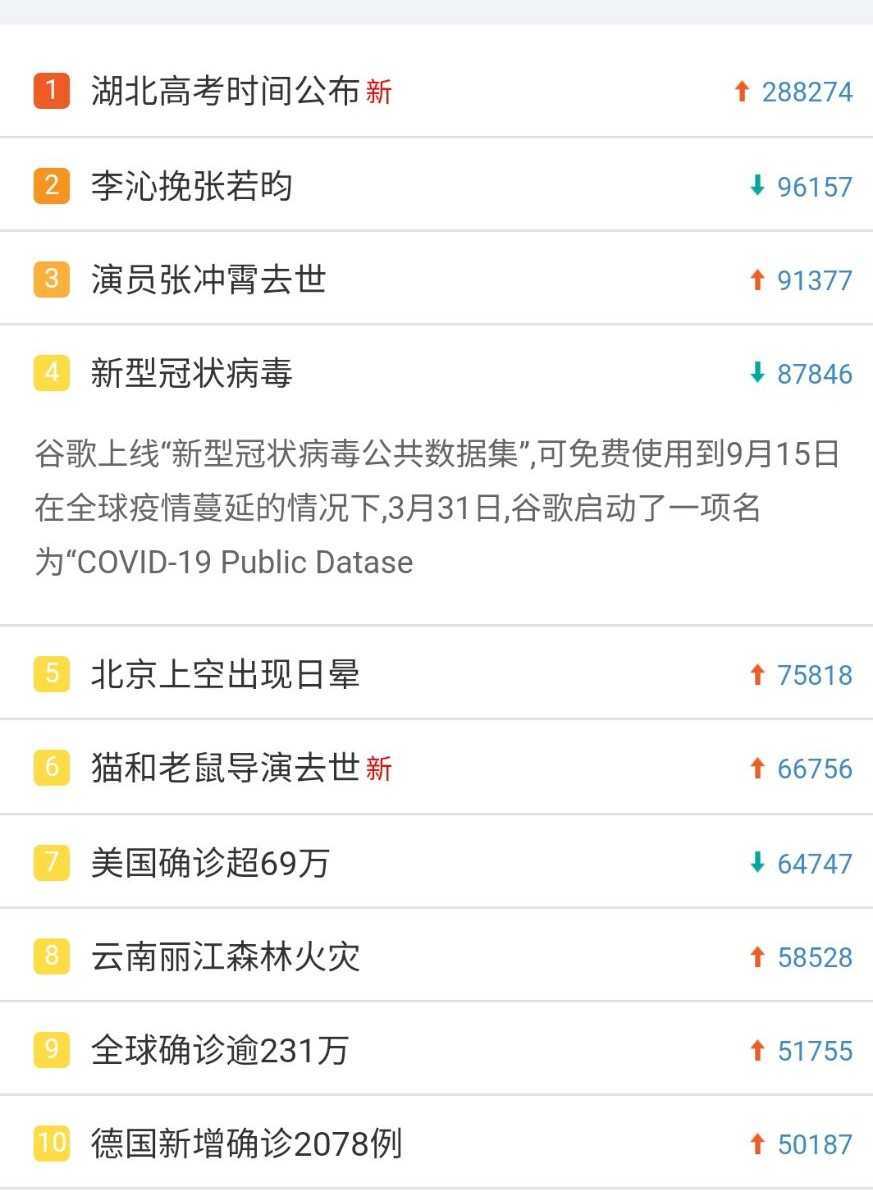
三、网络爬虫程序设计
1.数据爬取与采集:
import requests from bs4 import BeautifulSoup import bs4 import pandas as pd titles=[] hots=[] top=[] url=‘http://top.baidu.com/buzz?b=341&c=513&fr=topbuzz_b1_c513‘ #选择要爬取的网站 headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/69.0.3497.100 Safari/537.36‘}#伪装爬虫 r=requests.get(url) #获得url信息 r.raise_for_status() #失败请求(非200响应)抛出异常 r.encoding = r.apparent_encoding #根据内容分析出的编码方式,备选编码; html = r.text #获得的HTML文本 table = BeautifulSoup(html,"html.parser").find("table") #对获得的文本进行html解析,查找<table>内的信息 soup=BeautifulSoup(html,‘lxml‘) for m in soup.find_all(class_="keyword"): titles.append(m.get_text().strip()) for n in soup.find_all(class_="icon-rise"): hots.append(n.get_text().strip()) for k in soup.find_all(class_="first"): top.append(k.get_text().strip()) final=[top,titles,hots] print(final) df=pd.DataFrame(final,index=["排名","标题","热度数据"]) #使用工具使其可视化 print(df.T) S="D:/ 百度排行榜.xlsx" df.T.to_excel(S)

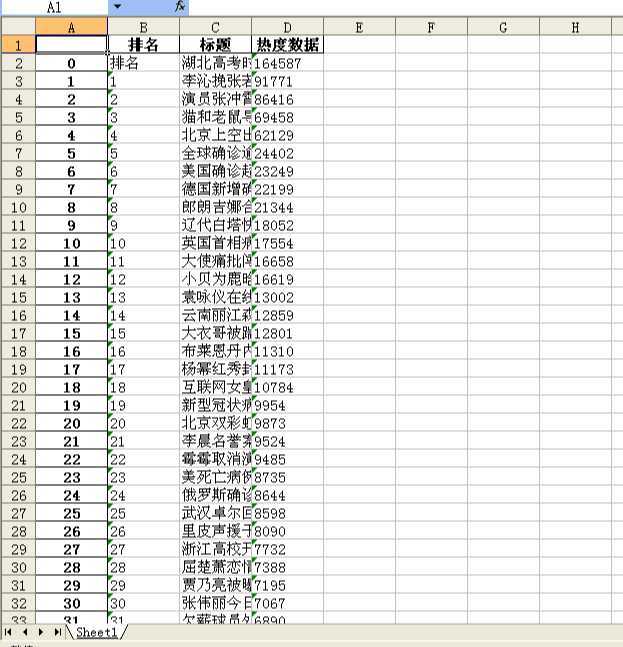
2.对数据进行清洗和处理:
#数据清洗 print(‘\n====各列是否有缺失值情况如下:====‘) print(df.isnull()) #统计空值情况 print(df.duplicated()) #查找重复值 print(df.isna().head()) print(df.describe()) #描述数据

3.数据分析与可视化:
1
import matplotlib.pyplot as plt import matplotlib matplotlib.rcParams[‘font.sans-serif‘]=[‘SimHei‘] x =[‘湖北高考时间公布‘,‘李沁挽张若昀‘,‘演员张冲霄去世‘,‘新型冠状病毒‘,‘北京上空出现日晕‘,‘猫和老鼠导演去世‘,‘美国确诊超69万‘] y = [1,2,3,4,5,6,7] plt.plot(x,y) plt.xlabel("标题") plt.ylabel("排名") plt.title(‘Top7热点‘) plt.show()
2;柱状图
plt.rcParams[‘font.family‘]=[‘sans-serif‘] plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘] plt.bar([‘湖北高考时间公布‘,‘李沁挽张若昀‘,‘演员张冲霄去世‘,‘新型冠状病毒‘,‘北京上空出现日晕‘,‘猫和老鼠导演去世‘,‘美国确诊超69万‘], [288274,96157,91377,87846,75818,66756,64747]) plt.legend() plt.xlabel("热搜事件") plt.ylabel("热度指数") plt.title(‘Top7热点‘) plt.show()
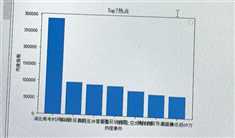
3:折线图
#折线图 def line_diagram(): x = [‘湖北高考时间公布‘,‘李沁挽张若昀‘,‘演员张冲霄去世‘,‘新型冠状病毒‘,‘北京上空出现日晕‘,‘猫和老鼠导演去世‘,‘美国确诊超69万‘] y = [288274,96157,91377,87846,75818,66756,64747] plt.xlabel(‘事件‘) plt.ylabel(‘热度‘) plt.plot(x,y) plt.scatter(x,y) plt.title("热搜事件与热度折线图") plt.show() line_diagram()

4:散点图
#散点图 def Scatter_point(): x = [‘湖北高考时间公布‘,‘李沁挽张若昀‘,‘演员张冲霄去世‘,‘新型冠状病毒‘,‘北京上空出现日晕‘,‘猫和老鼠导演去世‘,‘美国确诊超69万‘] y = [1,2,3,4,5,6,7] plt.scatter(x,y,color=‘pink‘, s=25, marker="o") plt.xlabel("事件") plt.ylabel("热度") plt.title("热搜事件与热度散点图") plt.show() Scatter_point()
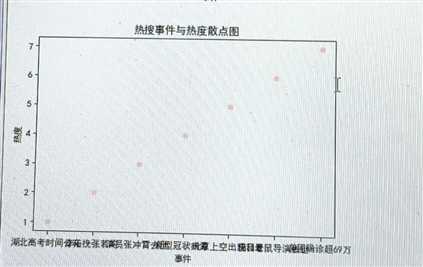
5:一元二次方程
#一元二次方程 import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib from scipy.optimize import leastsq chinese=matplotlib.font_manager.FontProperties(fname=‘C:/Windows/Fonts/simsun.ttc‘) #调用中文 filename="D:/ 百度排行榜.xlsx" colnames=["rank","rate_value","hot"] df=pd.read_excel(filename,skiprows=1,names=colnames) print(df) X=df.rank Y=df.rate_value def fit_func(p, x): a, b, c= p return a*x*x+b*x+c def error_func(p, x, y): return func(p, x) - y def main(): p0=[1978,300,1] Para=leastsq(error_func,p0,args=(X,Y)) a,b,c=Para[0] print("a=", a,"b=", b,"c=", c) plt.figure(figsize=(10,6)) plt.scatter(X, Y, color="green", label="样本数据",linewidth=2) x=np.linspace(1978,2020,300) y=a*x*x+b*x+c plt.plot(X,Y,color="red",label=u"拟合直线",linewidth=2) plt.title(" 百度排行榜 ") plt.grid() plt.legend() plt.show()
main()
6:将以上各部分的代码汇总,附上完整程序代码:
import requests from bs4 import BeautifulSoup import bs4 import pandas as pd titles=[] hots=[] top=[] url=‘http://top.baidu.com/buzz?b=341&c=513&fr=topbuzz_b1_c513‘ #选择要爬取的网站 headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/69.0.3497.100 Safari/537.36‘}#伪装爬虫 r=requests.get(url) #获得url信息 r.raise_for_status() #失败请求(非200响应)抛出异常 r.encoding = r.apparent_encoding #根据内容分析出的编码方式,备选编码; html = r.text #获得的HTML文本 table = BeautifulSoup(html,"html.parser").find("table") #对获得的文本进行html解析,查找<table>内的信息 soup=BeautifulSoup(html,‘lxml‘) for m in soup.find_all(class_="keyword"): titles.append(m.get_text().strip()) for n in soup.find_all(class_="icon-rise"): hots.append(n.get_text().strip()) for k in soup.find_all(class_="first"): top.append(k.get_text().strip()) final=[top,titles,hots] print(final) df=pd.DataFrame(final,index=["排名","标题","热度数据"]) #使用工具使其可视化 print(df.T) S="D:/ 百度排行榜.xlsx" df.T.to_excel(S) #数据清洗 print(‘\n====各列是否有缺失值情况如下:====‘) print(df.isnull()) #统计空值情况 print(df.duplicated()) #查找重复值 print(df.isna().head()) print(df.describe()) #描述数据 import matplotlib.pyplot as plt import matplotlib matplotlib.rcParams[‘font.sans-serif‘]=[‘SimHei‘] x =[‘湖北高考时间公布‘,‘李沁挽张若昀‘,‘演员张冲霄去世‘,‘新型冠状病毒‘,‘北京上空出现日晕‘,‘猫和老鼠导演去世‘,‘美国确诊超69万‘] y = [1,2,3,4,5,6,7] plt.plot(x,y) plt.xlabel("标题") plt.ylabel("排名") plt.title(‘Top7热点‘) plt.show() plt.rcParams[‘font.family‘]=[‘sans-serif‘] plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘] plt.bar([‘湖北高考时间公布‘,‘李沁挽张若昀‘,‘演员张冲霄去世‘,‘新型冠状病毒‘,‘北京上空出现日晕‘,‘猫和老鼠导演去世‘,‘美国确诊超69万‘], [288274,96157,91377,87846,75818,66756,64747]) plt.legend() plt.xlabel("热搜事件") plt.ylabel("热度指数") plt.title(‘Top7热点‘) plt.show() #折线图 def line_diagram(): x = [‘湖北高考时间公布‘,‘李沁挽张若昀‘,‘演员张冲霄去世‘,‘新型冠状病毒‘,‘北京上空出现日晕‘,‘猫和老鼠导演去世‘,‘美国确诊超69万‘] y = [288274,96157,91377,87846,75818,66756,64747] plt.xlabel(‘事件‘) plt.ylabel(‘热度‘) plt.plot(x,y) plt.scatter(x,y) plt.title("热搜事件与热度折线图") plt.show() line_diagram() #散点图 def Scatter_point(): x = [‘湖北高考时间公布‘,‘李沁挽张若昀‘,‘演员张冲霄去世‘,‘新型冠状病毒‘,‘北京上空出现日晕‘,‘猫和老鼠导演去世‘,‘美国确诊超69万‘] y = [1,2,3,4,5,6,7] plt.scatter(x,y,color=‘pink‘, s=25, marker="o") plt.xlabel("事件") plt.ylabel("热度") plt.title("热搜事件与热度散点图") plt.show() Scatter_point() #一元二次方程 import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib from scipy.optimize import leastsq chinese=matplotlib.font_manager.FontProperties(fname=‘C:/Windows/Fonts/simsun.ttc‘) #调用中文 filename="D:/ 百度排行榜.xlsx" colnames=["rank","rate_value","hot"] df=pd.read_excel(filename,skiprows=1,names=colnames) print(df) X=df.rank Y=df.rate_value def fit_func(p, x): a, b, c= p return a*x*x+b*x+c def error_func(p, x, y): return func(p, x) - y def main(): p0=[1978,300,1] Para=leastsq(error_func,p0,args=(X,Y)) a,b,c=Para[0] print("a=", a,"b=", b,"c=", c) plt.figure(figsize=(10,6)) plt.scatter(X, Y, color="green", label="样本数据",linewidth=2) x=np.linspace(1978,2020,300) y=a*x*x+b*x+c plt.plot(X,Y,color="red",label=u"拟合直线",linewidth=2) plt.title(" 百度排行榜 ") plt.grid() plt.legend() plt.show() main() plt.savefig(fname="D:/百度热搜榜排名和热度关系图.jpg",figsize=[1,1]) #保存图像
四、结论
1.经过对主题数据的分析与可视化,可以得到哪些结论?
结论:python这门语言博大精深,虽然初学但是还是能感受到其中的奥秘以及难度,比起其他语言容易上手但但精通,我在数据处理这块还是有很多问题需要解决。
2.小结:通过这次作业,了解到了自己的众多不足,类似于回归方程的拟合以及一元多次方程的画法还掌握不当,这次任务加大了自己对python的兴趣,希望自己以后可以努力学习,更上一层楼。
原文:https://www.cnblogs.com/huangguowei/p/12763589.html