前言:原方案是设计爬取起点中文网月票排行榜并处理数据

爬取后发现数据量不够,无法做可视化。

重新爬取发现网站对月票数据进行了加密处理,学识有限便放弃这一课程设计了。
爬取的数据图片

链家网上关于福州二手房每平米价格爬取及数据处理
一,设计方案
1.爬取的目标是链家网上福州二手房的价格信息(https.//fz.lianjia.com/xiaoqu/ )
2.网页信息有房屋每平米单价,简介等等
3.设计方案:通过Jupyter Notebook 运用requests,BeautifulSoup库爬取信息并保存,再进行find遍历查取所需信息,并进行数据可视化。

二.。主题页面源代码分析标签
进入网页打开源代码,发现所需的信息的标签为li,并与其他房产信息在ul下。继续 打开标签,确定这是我们所需的信息。
三。运行代码进行爬取实践
1,爬取

保存结果文件到Excle



2,数据清洗


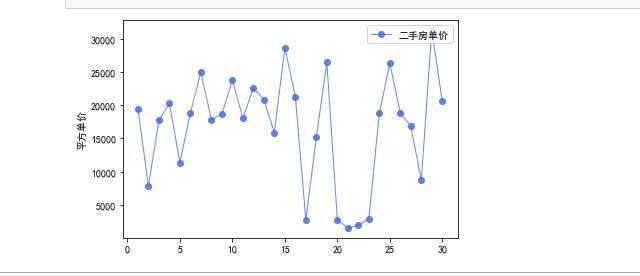
3.进行数据可视化,制作直方图,折线图等
直方图:


折线图:

建立一元二次方程并做图


源代码
import requests#导入库 from bs4 import BeautifulSoup import numpy as np import scipy as sp import matplotlib.pyplot as plt import matplotlib from scipy.optimize import leastsq from numpy import genfromtxt url=‘https://fz.lianjia.com/xiaoqu/‘ headers={ ‘User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363‘ }#伪装爬虫 resp=requests.get(url)#发送requests请求 #print(resp.text) html=resp.text soup=BeautifulSoup(html,‘lxml‘) #print(soup) infos=soup.find(‘ul‘,{‘class‘:‘listContent‘}).find_all(‘li‘)#find查询 #print(infos) for info in infos: name=info.find(‘div‘,{‘class‘:‘title‘}).find(‘a‘).get_text() #print(name) price=info.find(‘div‘,{‘class‘:‘xiaoquListItemPrice‘}).find(‘div‘,{‘class‘:‘totalPrice‘}).find(‘span‘).get_text() #print(price) data=(name,price) #print(data) D=pd.DataFrame(data,index=["简介","平方单价"]) #print(D.T) with open(r‘C:\Users\86150\Desktop\house/abc.scv‘,‘a‘,encoding=‘utf-8‘) as f: f.write(‘{},{}\n‘.format(nameprice))#保存到Excel #数据清洗 print(‘\n====各列是否有缺失值情况如下:====‘) print(D.isnull()) print(D.duplicated()) print(D.isna().head()) print(D.describe()) #条形图 import matplotlib.pyplot as plt plt.figure(figsize=(10, 10), dpi=80) # 柱子总数 N = 30 # 包含每个柱子对应值的序列 values = (19441,7853,17715,20261,11373,18850,24968,17773,18653,23799,18027,22596,20842, 15882,28645,21279,2726,15182,26430,2790,1542,1919,2939,18762,26299,18808,16852,8694,31261,20561) # 包含每个柱子下标的序列 index = np.arange(N) # 柱子的宽度 width = 0.45 p2 = plt.bar(index, values, width, label="num", color="#87CEFA") # 设置横轴标签 plt.xlabel(‘region‘) # 设置纵轴标签 plt.ylabel(‘unit price‘) # 添加标题 plt.title(‘Second-hand house square unit price ‘) # 添加纵横轴的刻度 plt.xticks(index, (‘1‘,‘2‘,‘3‘,‘4‘,‘5‘,‘6‘,‘7‘,‘8‘,‘9‘,‘10‘,‘11‘,‘12‘,‘13‘,‘14‘,‘15‘,‘16‘,‘17‘,‘18‘,‘19‘,‘20‘,‘21‘, ‘22‘,‘23‘,‘24‘,‘25‘,‘26‘,‘27‘,‘28‘,‘29‘,‘30‘)) # plt.yticks(np.arange(0, 10000, 10)) # 添加图例 plt.legend(loc="upper right") plt.show() #折线图 from pylab import * mpl.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 添加这条可以让图形显示中文 x_axis_data = [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30] y_axis_data = [19441,7853,17715,20261,11373,18850,24968,17773,18653,23799,18027,22596,20842,15882, 28645,21279,2726,15182,26430,2790,1542,1919,2939,18762,26299,18808,16852,8694,31261,20561] # plot中参数的含义分别是横轴值,纵轴值,线的形状,颜色,透明度,线的宽度和标签 plt.plot(x_axis_data, y_axis_data, ‘ro-‘, color=‘#4169E1‘, alpha=0.8, linewidth=1, label=‘二手房单价‘) # 显示标签,如果不加这句,即使在plot中加了label=‘一些数字‘的参数,最终还是不会显示标签 plt.legend(loc="upper right") plt.ylabel(‘平方单价‘) plt.show() # plt.savefig(‘demo.jpg‘) # 保存该图片 #一元二次 chinese=matplotlib.font_manager.FontProperties(fname=‘C:/Windows/Fonts/simsun.ttc‘) source_data=genfromtxt(‘C:/house.csv‘,dtype=float,delimiter=‘,‘) data=np.delete(source_data,0,axis=0) price=data[:,0] number=data[:,1] X=np.array(number) Y=np.array(price) def func(p,x): a,b,c=p return a*x*x+b*x+c def error(p,x,y): return func(p,x)-y p0=[1,0] def main(): plt.figure(figsize=(8,6)) p0=[1,30,30] Para=leastsq(error,p0,args=(X,Y)) a,b,c=Para[0] print("a=",a,"b=",b,"c=",c) plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) x=np.linspace(1,30,30) y=a*x*x+b*x+c plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) plt.legend(prop=chinese) plt.title("Second-hand house square unit price") plt.grid() plt.show() main()
四。结论。
通过前段时间python课程的学习,加上这段时间爬虫程序的设计与实践。发现运用python可以做许多事情,编写各种程序,而爬虫程序更是可以进行数据获取及整合,通过清洗后可视化能更好的进行数据分析。可惜自身学识有限,在爬虫过程中遇到许多问题并不能很好解决,在查找资料的过程中无不为他人厉害的爬虫程序所驻足,忍不住想要一试,例如爬取歌单等等。这便是爬虫的魅力,做许多本想不到的事。此次制作更是让我明白,纸上功夫是没用的,想要学好还得实践才行,实践了才明白如何运用库,函数。
原文:https://www.cnblogs.com/ZXC1020/p/12770645.html