采用lightGBM模型
准备数据与训练
该数据数聚包含物品的售卖时间与物品类型
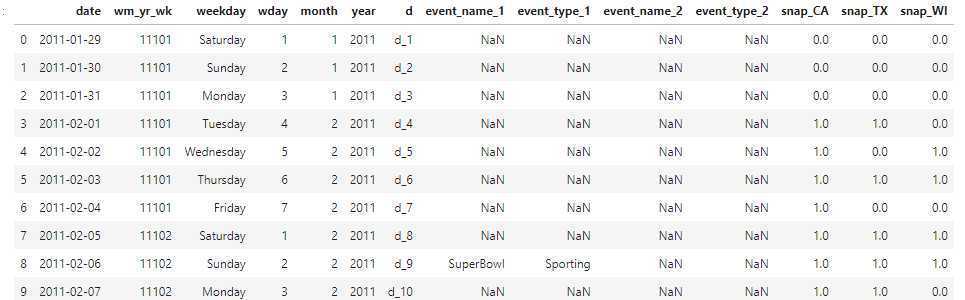
# Correct data types for "calendar.csv" calendarDTypes = {"event_name_1": "category", "event_name_2": "category", "event_type_1": "category", "event_type_2": "category", "weekday": "category", ‘wm_yr_wk‘: ‘int16‘, "wday": "int16", "month": "int16", "year": "int16", "snap_CA": "float32", ‘snap_TX‘: ‘float32‘, ‘snap_WI‘: ‘float32‘ } # Read csv file calendar = pd.read_csv("./calendar.csv", dtype = calendarDTypes) calendar["date"] = pd.to_datetime(calendar["date"]) calendar.head(10)
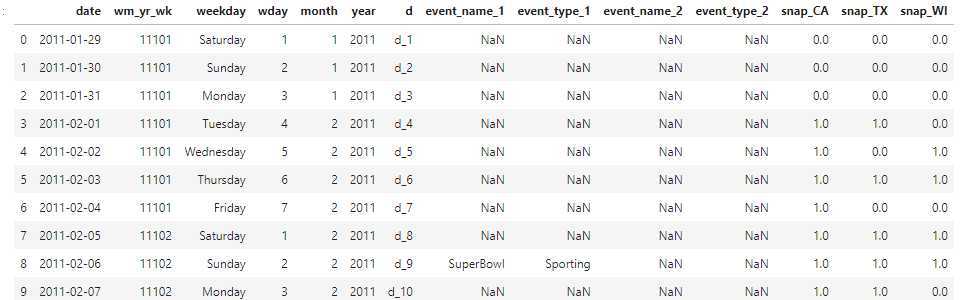
# Transform categorical features into integers for col, colDType in calendarDTypes.items(): if colDType == "category": calendar[col] = calendar[col].cat.codes.astype("int16") calendar[col] -= calendar[col].min() calendar.head(10)
File 2: “sell_prices.csv”
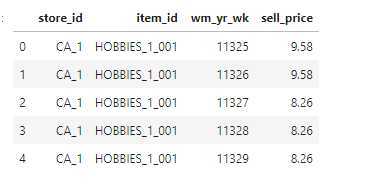
该数据数聚包含物品的每天每单位的售卖价格
# Correct data types for "sell_prices.csv" priceDTypes = {"store_id": "category", "item_id": "category", "wm_yr_wk": "int16", "sell_price":"float32"} # Read csv file prices = pd.read_csv("./sell_prices.csv", dtype = priceDTypes) prices.head()
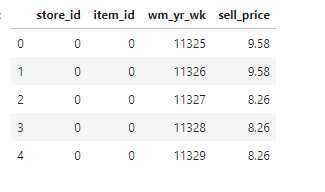
# Transform categorical features into integers for col, colDType in priceDTypes.items(): if colDType == "category": prices[col] = prices[col].cat.codes.astype("int16") prices[col] -= prices[col].min() prices.head()
File 3: “sales_train.csv”
Contains the historical daily unit sales data per product and store.
firstDay = 250 lastDay = 1913 # Use x sales days (columns) for training numCols = [f"d_{day}" for day in range(firstDay, lastDay+1)] # Define all categorical columns catCols = [‘id‘, ‘item_id‘, ‘dept_id‘,‘store_id‘, ‘cat_id‘, ‘state_id‘] # Define the correct data types for "sales_train_validation.csv" dtype = {numCol: "float32" for numCol in numCols} dtype.update({catCol: "category" for catCol in catCols if catCol != "id"}) [(k,v) for k,v in dtype.items()][:10]

# Read csv file ds = pd.read_csv("./sales_train_validation.csv", usecols = catCols + numCols, dtype = dtype) ds.head()

# Transform categorical features into integers for col in catCols: if col != "id": ds[col] = ds[col].cat.codes.astype("int16") ds[col] -= ds[col].min() ds = pd.melt(ds, id_vars = catCols, value_vars = [col for col in ds.columns if col.startswith("d_")], var_name = "d", value_name = "sales") # Merge "ds" with "calendar" and "prices" dataframe ds = ds.merge(calendar, on = "d", copy = False) ds = ds.merge(prices, on = ["store_id", "item_id", "wm_yr_wk"], copy = False) ds.head()
1·1
原文:https://www.cnblogs.com/wqbin/p/12785680.html