官方文档是这样描述的:
Categoricals 是 pandas 的一种数据类型,对应着被统计的变量。
1.Categoricals 是由固定的且有限数量的变量组成的。比如:性别、社会阶层、血型、国籍、观察时段、赞美程度等等。
2.与其它被统计的变量相比,categorical 类型的数据可以具有特定的顺序——比如:按程度来设定,“强烈同意”与“同意”,“首次观察”与“二次观察”,但是不能做按数值来进行排序操作
(比如:sort_by 之类的,换句话说,categorical 的顺序是创建时手工设定的,是静态的)
3.类型数据的每一个元素的值要么是预设好的类型中的某一个,要么是空值(np.nan)。
用一段代码从不同角度来展现一下 categorical 类型的数据。
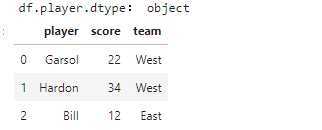
# 用一组数据记录各自的得分情况 import pandas as pd, numpy as np players=[‘Garsol‘,‘Hardon‘,‘Bill‘] scores=[22,34,12,] teams=[‘West‘,‘West‘,‘East‘] df=pd.DataFrame({‘player‘:players,‘score‘:scores,‘team‘:teams}) print("df.player.dtype:",df.player.dtype) df
把team字段转为category数据类型
df["team"].astype(‘category‘)

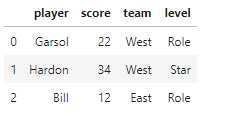
d=pd.Series(scores).describe() score_ranges=[d[‘min‘]-1,d[‘mean‘],d[‘max‘]+1] score_labels=[‘Role‘,‘Star‘] # 用pd.cut(ori_data, bins, labels) 方法 # 以 bins 设定的画界点来将 ori_data 归类,然后用 labels 中对应的 label 来作为分类名 df[‘level‘]=pd.cut(df[‘score‘],score_ranges,labels=score_labels) df
df[‘team‘]

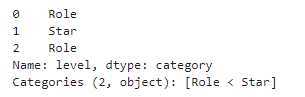
df[‘level‘]
roles=pd.Categorical([‘Role‘,‘xxx‘,‘Star‘],categories=[‘Role‘, ‘Star‘])
roles

构造方法中第二个参数是指定了实例中可以包含的元素,在第一个参数中的元素如果不在 categories 中,就会被转成NaN。
df=pd.DataFrame({‘players‘:[‘Garsol‘,‘Hardon‘,‘Bill‘]})
df[‘level‘]=roles
df[‘level‘]

pandas 数据类型研究(三)数据类型object与category
原文:https://www.cnblogs.com/wqbin/p/12786217.html