1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
防止过拟合:
算法:正则化;
数据:加大样本量;通过特征选择减少特征量
业务:EDA-探索有区分性的特征;特征派生-不断派生更多强组合的特征。
正则化防止过拟合:要拟合训练数据,就要足够大的模型空间;而用了足够大的模型空间,挑选测试性能好的模型的概率就会下降,最后就会变成这样一种情况——出现训练数据拟合越好,测试性能越差的过拟合现象。而正则化就是控制模型空间的一种办法,所有可以防止过拟合。
2.用logiftic回归来进行实践操作,数据不限。
代码:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import pandas as pd
#1)加载数据
data=pd.read_csv(‘./LogisticRegression.csv‘)
x_data=data.iloc[:,1:] #所有行,1-3列
y_data=data.iloc[:,0]
#2)划分训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(x_data,y_data,test_size=0.2,random_state=5)
#3)构建并训练模型
model_LR=LogisticRegression(solver=‘liblinear‘)
model_LR.fit(x_train,y_train)
#4)模型预测
y_pre=model_LR.predict(x_test)
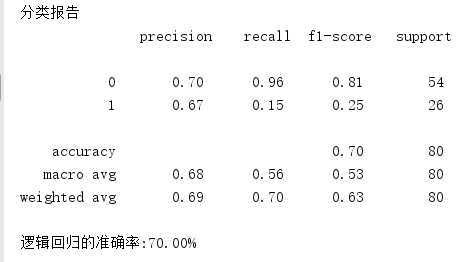
print(‘分类报告\n‘,classification_report(y_test,y_pre))
print(‘逻辑回归的准确率:{0:.2f}%‘.format(model_LR.score(x_test,y_test)*100))
原文:https://www.cnblogs.com/chenjd/p/12786523.html