Mysql用户变量的形式是:@var,其可以使用的场合很多,例如新增一列排序值、分组排序等。
下面让我们来探讨一下其部分应用场景。
1. 首先建表,插入数据:
create table t_variable ( name_people VARCHAR(255) NOT NULL comment ‘姓名‘, grade VARCHAR(255) NOT NULL comment ‘年级‘, course VARCHAR(255) NOT NULL comment ‘科目‘, score VARCHAR(255) NOT NULL comment ‘分数‘ )ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=‘test_变量‘; insert into t_variable(name_people, grade, course, score) values(‘花满楼‘,5,‘数学‘,86); insert into t_variable(name_people, grade, course, score) values(‘陆小凤‘,5,‘数学‘,94); insert into t_variable(name_people, grade, course, score) values(‘西门吹雪‘,5,‘数学‘,90); insert into t_variable(name_people, grade, course, score) values(‘花满楼‘,5,‘语文‘,97); insert into t_variable(name_people, grade, course, score) values(‘陆小凤‘,5,‘语文‘,95); insert into t_variable(name_people, grade, course, score) values(‘西门吹雪‘,5,‘语文‘,89); insert into t_variable(name_people, grade, course, score) values(‘花满楼‘,5,‘科学‘,93); insert into t_variable(name_people, grade, course, score) values(‘陆小凤‘,5,‘科学‘,96); insert into t_variable(name_people, grade, course, score) values(‘西门吹雪‘,5,‘科学‘,94);
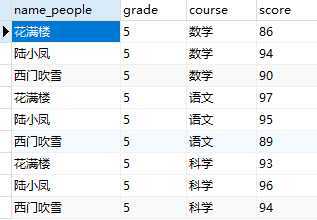
2. 变量定义和初始化
select @a:=1 as a, @b:=3 as b;
set @a=1, @b=3; set @a:=1, @b:=3; select @a as a, @b as b; #先set,再使用
select @a as a, @b as b; #重新打开连接,未赋值直接使用,会显示Null
3. 使用变量@:join
select * from t_variable as t1 cross join #直接笛卡尔积 ( select @a:=1 as a, @b:=3 as b ) as t2;
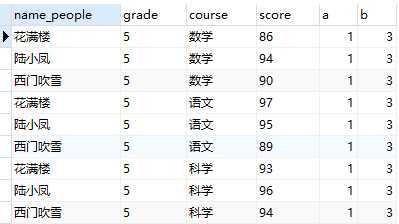
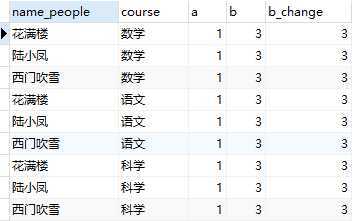
4. 使用变量@:用于判断和新增列
select name_people, course, @a as a, @b as b, if(@a=2, @b:=@b+2, @b) as b_change from ( select * from t_variable as t1 cross join #直接笛卡尔积 ( select @a:=1, @b:=3 ) as t2 ) as t3;
select name_people, course, @a as a, @b as b, if(@a=1, @b:=@b+2, @b) as b_change from ( select * from t_variable as t1 cross join #直接笛卡尔积 ( select @a:=1, #初始值 @b:=3 ) as t2 ) as t3;
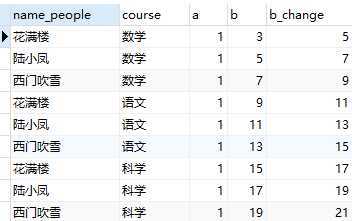
select name_people, course, @a as a, @b as b, if(@a=1, @b:=@b+2, @b) as b_change, #返回值是变量值 @a:=@a+1 as a_change #修改了@a的值,也就是从上往下,每一次返回记录时都会执行,可用于加入排序值的列 from ( select * from t_variable as t1 cross join #直接笛卡尔积 ( select @a:=1, #初始值 @b:=3 ) as t2 ) as t3;
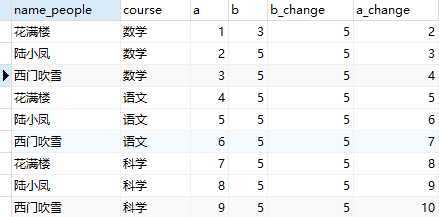
看到此时的变量a有什么特点:没错,就是按序排列的,所以可用于增加排序值。
5. 使用变量@:分组排序 —— 先按分组字段和排序字段进行整体排序,这样相同选择字段的记录就会前后排列;然后返回记录时,每次比较前后记录的分组字段,各组分别进行排名(因为此时排序字段已经有序了)。
select name_people, course, score, @ss, @tt, if(@ss=course, @tt:=@tt+1, @tt:=1) as rk, @ss:=course as a_course from ( select * from t_variable order by course, score desc # 先按分组字段course和排序字段score进行整体排序,这样相同选择字段的记录就会前后排列 ) as t1 cross join #直接笛卡尔积 ( select @ss:=‘‘, #初始值 @tt:=0 ) as t2;
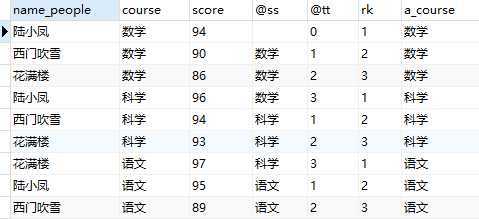
此时,如果要取其中rk=1的记录的话,直接在外面加一层select进行筛选即可。
注意!!!:同一次连接中,最好不要用同样的参数名,因为当参数的类型不同时,很可能会影响下一次的结果。
参考:
https://www.cnblogs.com/youngerger/p/8626571.html
原文:https://www.cnblogs.com/qi-yuan-008/p/12787922.html