from bs4 import BeautifulSoup
import requests
import csv
‘‘‘
:param url 爬取页面第一页,页数用{}代替
:param page 爬取页数
:return 返回一个存放每个职位详细信息的链接 列表
‘‘‘
def get_urls(url, page):
sub_urls = [] # 存放子链接列表
count = 1 # 数据计数
# 获取子链接
for i in range(1, page):
response = requests.get(url.format(i), header) # 获取子链接
response.encoding = ‘gbk‘ # gbk解码
soup = BeautifulSoup(response.text, "html.parser") # 用html.parser解析 将返回的文本转BeautifulSoup对象
p_info = soup.find_all(‘p‘, class_="t1") # 获取到p标签的信息
for info in p_info:
sub_urls.append(info.span.a[‘href‘]) # 获取a标签的 href链接 添加到sub_url
print("已获取{}个字网页链接".format(count))
count += 1
return sub_urls # 返回子链接列表
‘‘‘
:param sub_urls 子页面链接
:param filename 存放信息的csv文件名称
:return 无返回,会在当前目录创建该文件,获取的信息会存放在该文件中
‘‘‘
def get_info(sub_urls, filename):
# 数据计数
count = 1
# 写入要获取的信息
with open(storefile, ‘w‘, newline=‘‘, encoding=‘utf-8‘) as f:
csv_write = csv.writer(f)
csv_write.writerow([‘公司‘, ‘职位名称‘, ‘工资‘, ‘地点及要求‘, ‘福利‘, ‘职位信息‘])
# 访问子链接获取需要的信息
for url in sub_urls:
# 获取文本
try:
info_response = requests.get(url, headers=header)
info_response.encoding = ‘gbk‘
info_soup = BeautifulSoup(info_response.text, "html.parser")
# 职位、薪资、公司信息抓取
infomation_less = info_soup.find(‘div‘, class_=‘cn‘) # 简单信息
position = infomation_less.h1.text # 职位
salary = infomation_less.strong.text # 薪资
company = infomation_less.p.a.text # 公司
# 招工信息抓取 地点、工作经验、学历要求、招工人数、发布日期等
info_employ = info_soup.find(‘p‘, class_=‘msg‘).text
req = info_employ.split("\xa0\xa0|\xa0\xa0") # 字符串分割
# 福利信息抓取
try:
info_welare = info_soup.find(‘div‘, class_=‘t1‘)
welare_all = info_welare.findAll(‘span‘, class_=‘sp4‘)
welare = [] # 建立存储福利列表
for i in welare_all:
welare.append(i.text) # 将所有span标签中的福利信息存入
# print(welare)
except Exception as e: # 异常抛出
print(‘ware‘, end=" ")
print(e)
welare = "None"
# 职位信息抓取
try:
info_position = info_soup.find("div", class_="bmsg")
position_all = info_position.find_all("p")
pos = ""
positioninfo = [] # 建立存储职位信息列表
for i in position_all:
positioninfo.append(i.text)
pos = pos.join(positioninfo) # 列表信息合并为一个字符串
except Exception as e: # 异常抛出
print(‘pos‘, end=" ")
print(e, end=" ")
pos = "None"
# 信息整合
all = [company, position, salary, req, welare, pos]
# 信息写入
with open(filename, ‘a‘, encoding=‘utf-8‘) as file:
write = csv.writer(file)
write.writerow(all)
except Exception as e: # 如果有异常,打印 并且存放None
print(e, end=" ")
with open(filename, ‘a‘, encoding=‘utf-8‘) as file:
write = csv.writer(file)
write.writerow([‘None‘])
print("已爬取{}条数据".format(count))
count += 1
if __name__ == ‘__main__‘:
storefile = ‘JobInfo.csv‘
url = ‘https://search.51job.com/list/120200%252C010000%252C020000%252C030200%252C040000,000000,0000,00,9,99,python,2,{}.html‘
header = {
‘User-Agent‘: "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36",
}
subUrls = get_urls(url, 10)
get_info(subUrls, storefile)
运行效果:
一、遇到问题与解决:
1、request.get() 关于请求头的问题 ,必须写 headers =header
2、BeautifulSoup 默认将字符编码转为utf-8。在职位信息写入csv文档的时候总是报 gbk 解析不了 “/xa0”,最后只好把csv以utf-8的方式解码
3、有些信息时获取不到的,存放的时候总是报错,当时没有抛出异常,程序终止。
4、抛异常尽可能多加,如果只加最外面的异常抛出,有的时候获取的某一个小数据抓取不到,会将整条数据记为None(我这里最外面写的是这样,如果抓取不到信息整条记录为None),之后我在内部也加了几个异常抛出,记录抓取不到的某个小数据记为None
5、csv写入问题,以w的方式打开会从表头开始写,到最后打开文件一看就一行数据(尴尬),最后搜了一下如果想接着写入要以a的方式打开
6、列表信息整合成字符,当我在爬取职位详情的时候,获取的信息都以list的形式存放的,当时感觉存起来不太好看而且原本信息也不是这样,后来同学提示,join()方法可以合并list里的信息为一个字符串
二、学到知识
除了上面所记录的还了解到了:
1、Beautiful Soup解析库
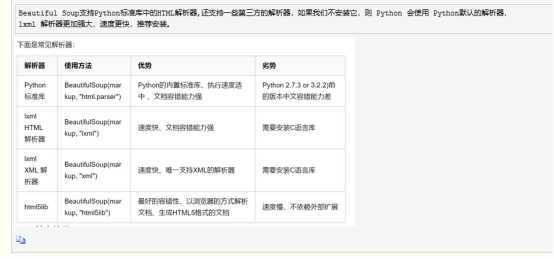
2、Beautiful Soup 属性获取

3、字符串分割

4、python 中 with as 的使用:

文件处理时自动关闭
三、还需完善:
Emmm,哈哈,这个代码写了半天了,也算是完成的差不多了,只是有些信息没有单独存放,为什么呢?因为信息存放在一个列表里了,列表信息不一,会有很多情况
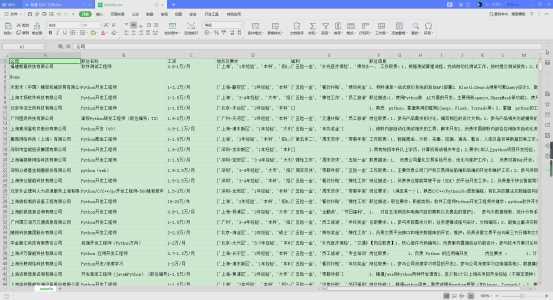
如图:

第一个值是城市,第二个值大部分都是要求的工作经验,但是有的也是没有的,如果通过索引的方法提取,提取到的信息可能并不是所需要的。我能想到的办法是通过字符匹配吧,类似于
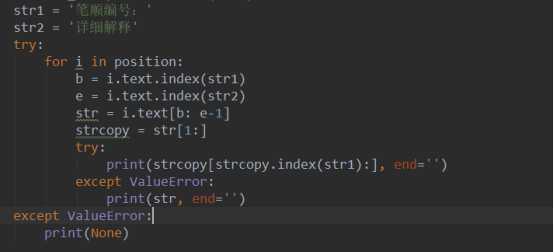
比如要去招多少人的信息,那么
1、合并整个列表为字符串,
2、str1=”招”, str2=”人”
3、然后定位两字符的位置b, e
4、之后对合并的字符进行切片处理,获取想要的信息
不过这样很麻烦,而且有的时候可能弄不准确,在线求解决方法~
原文:https://www.cnblogs.com/DullRabbit/p/12790747.html