本文是Mooc上 Python网络爬虫与信息提取 的笔记
没有框架,只用到了bs4库和request库
输入:大学排名的URL链接
输出:大学排名信息的屏幕输出(排名,大学名称,总分)
用到的技术: requests-bs4
定向爬虫:仅对输入的URL进行爬取,不扩展爬取
步骤①: 从网络上获取大学排名网页内容
getHMTLText()
步骤②:提取网页内容中信息到合适的数据结构
fillUnivList()
步骤③:利用数据结构展示并输出结果
printUnivList()
核心代码讲解:
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
# 从网络上获取大学排名网页内容
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(urlist,html):
# 提取url中关键的数据,并添加到列表之中
soup = BeautifulSoup(html,‘html.parser‘) # 使用BeautifuSopu来生成一个html内容的返回结果
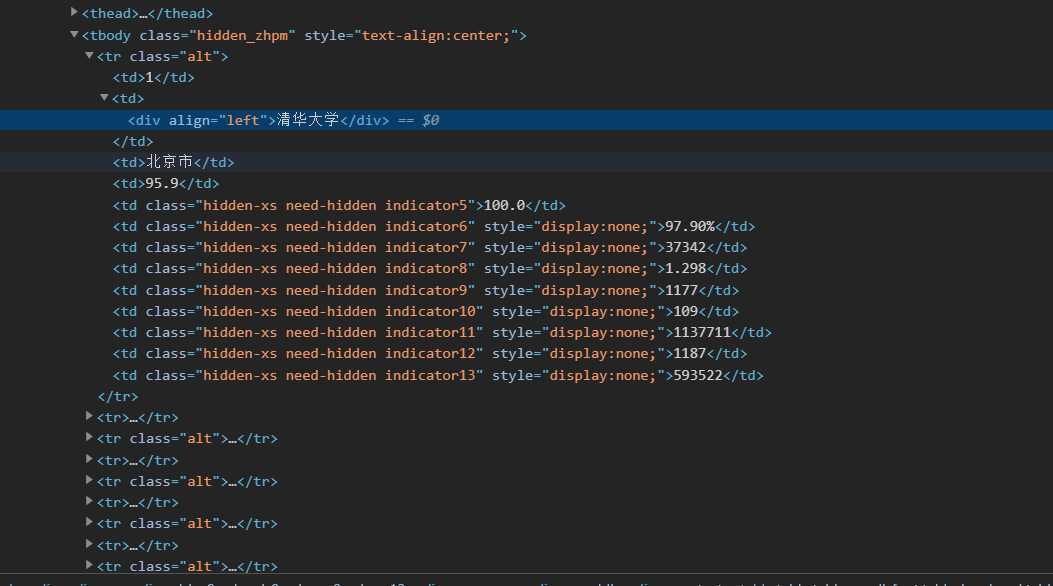
for tr in soup.find(‘tbody‘).children: # 找tbody里面的儿子标签
if isinstance(tr,bs4.element.Tag): # 如果儿子标签的属性是Tag的花
tds = tr(‘td‘) # tds会把Tag属性是td的列表返回
urlist.append([tds[0].string,tds[1].string,tds[3].string]) # 然后在向urlist里面把那些列表再次输入进去
# 为什么要跳过二呢,因为学校的地点,被我们跳过了
def printUnivList(ulist,num):
# 利用数据结构展示并输出结果
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0],u[1],u[2],chr((12288)))) #这个就是用u[0],u[1],u[2]带入
if __name__ == ‘__main__‘:
uinfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20) # 20 univs
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
这行代码是format的格式的应用,
{0:^10},表示第一个数据 中间对齐占位符 10格
{1:{3}^10} 表示第二个数据 占位符用{3} ,就是chr(12288)的内容
{2:^10} 表示第三个数据 中间对齐占位符 10格
原文:https://www.cnblogs.com/a-small-Trainee/p/12801700.html