1.Dropout
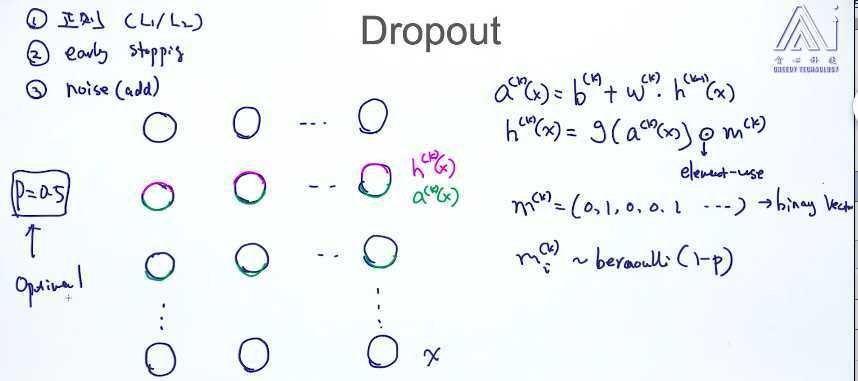
m(k)是dropout的过程。
2.attention机制

(1)seq2seq
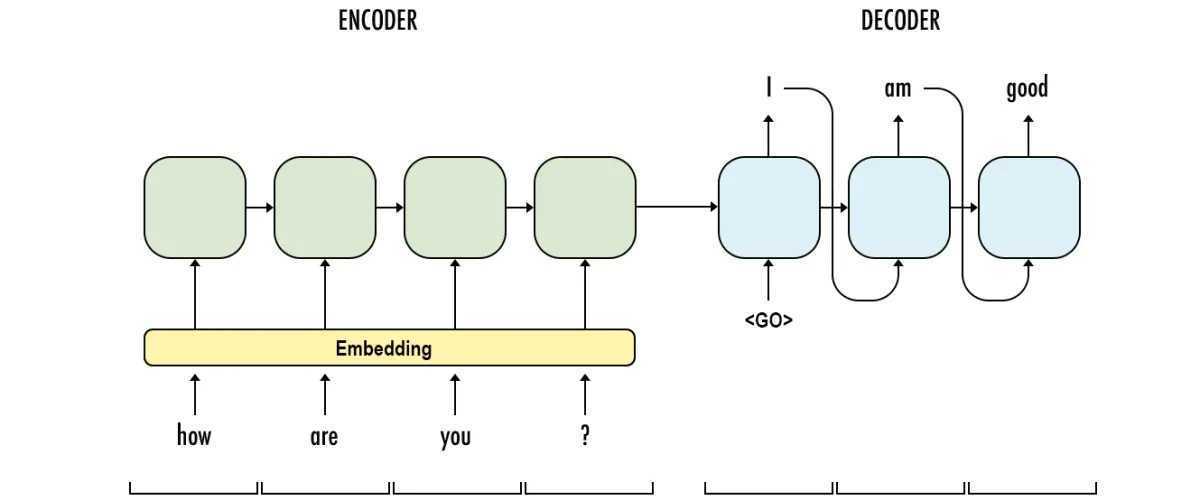
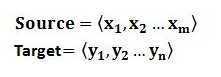
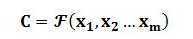
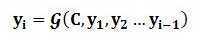
在翻译“杰瑞”这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是分心模型是无法体现这一点的,这就是为何说它没有引入注意力的原因。
没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因。
上面的例子中,如果引入Attention模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值
每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。
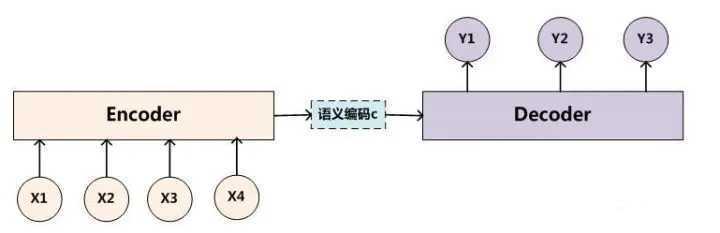
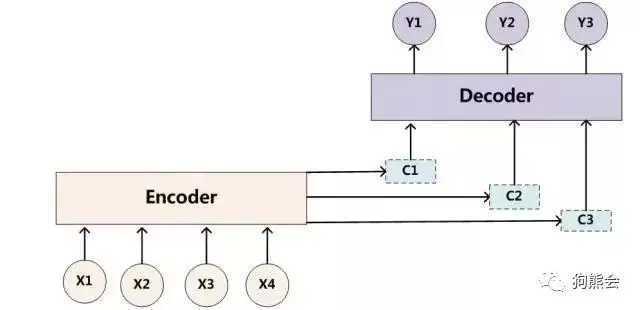
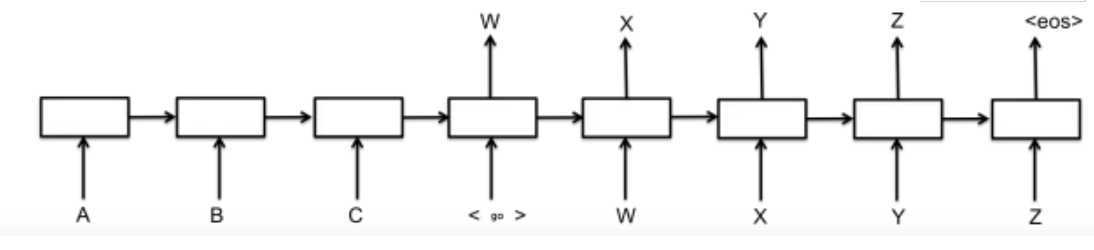
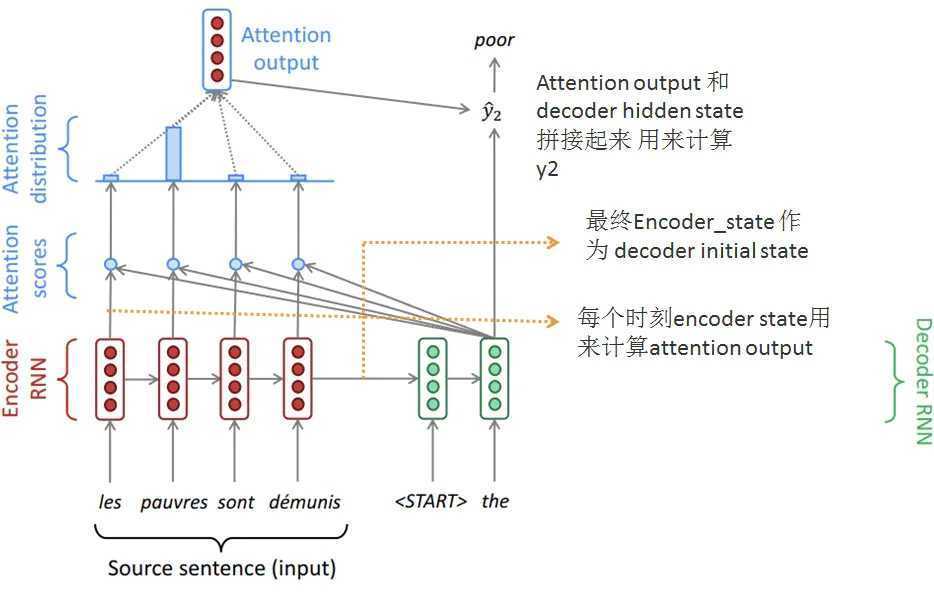
同理,目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词yi的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的Ci。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。增加了注意力模型的Encoder-Decoder框架理解起来如图5所示。
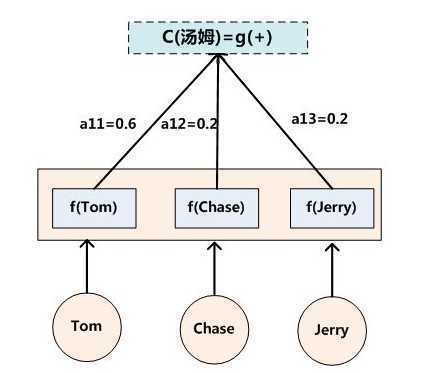
每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:

(2)attention
seq2seq 模型虽然强大,但如果仅仅是单一使用的话,效果会大打折扣。注意力模型就是基于 Encoder-Decoder 框架下的一种模拟 Human 注意力直觉的一种模型。
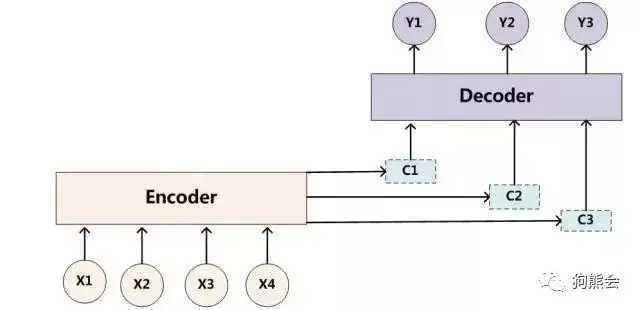
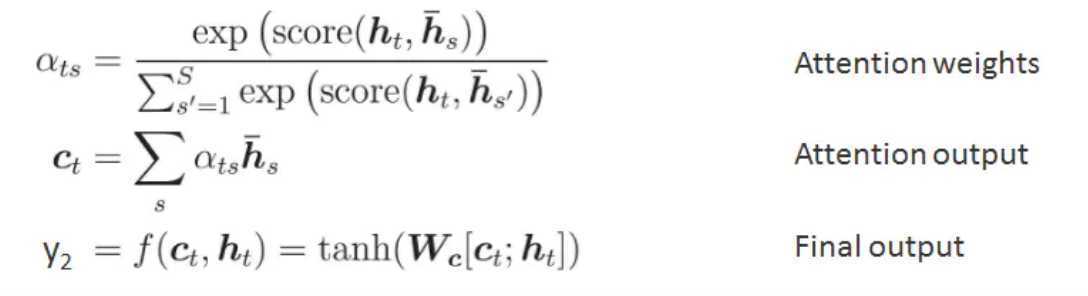
Attention 注意力机制提供了一个可以和远距离单词保持联系的方式, 解决了一个 vector 保存信息不足的问题。
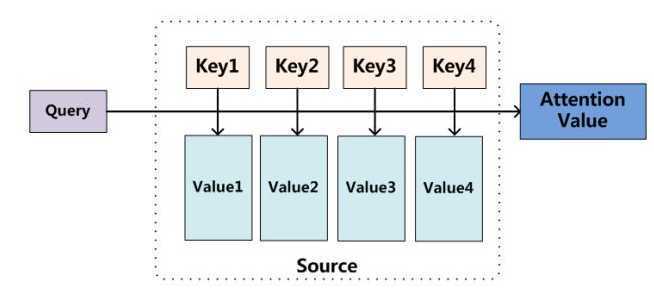
Attention实质上是一种 content-based addressing 的机制,即从网络中某些状态集合中选取与给定状态较为相似的状态,进而做后续的信息抽取;
说人话就是: 首先根据 Encoder 和 Decoder 的特征计算权值,然后对Encoder的特征进行加权求和,作为Decoder的输入,其作用是将Encoder的特征以更好的方式呈献给Decoder,即:并不是所有 context 都对下一个状态的生成产生影响,Attention 就是选择恰当的context用它生成下一个状态。
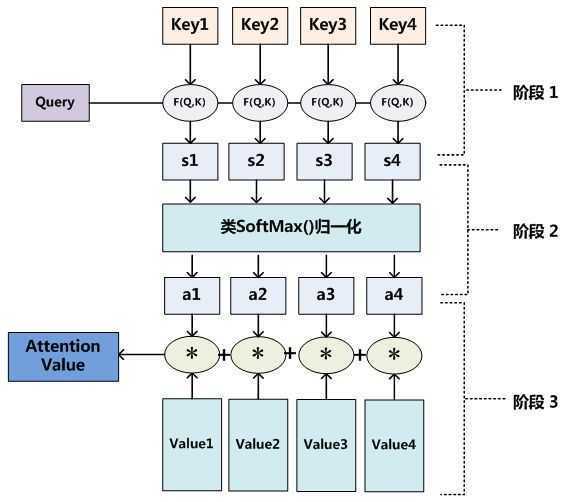
通过上述对Attention本质思想的梳理,我们可以更容易理解本节介绍的Self Attention模型。Self Attention也经常被称为intra Attention(内部Attention),最近一年也获得了比较广泛的使用,比如Google最新的机器翻译模型内部大量采用了Self Attention模型。
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素Query和Source中的所有元素之间。而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而已,所以此处不再赘述其计算过程细节。
原文:https://www.cnblogs.com/luckyplj/p/12812916.html