在了解了线性回归的背景知识之后,现在我们可以动手实现它了。尽管强大的深度学习框架可以减少大量重复性工作,但若过于依赖它提供的便利,会导致我们很难深入理解深度学习是如何工作的。因此,本节将介绍如何只利用Tensor和autograd来实现一个线性回归的训练。
首先,导入本节中实验所需的包或模块,其中的matplotlib包可用于作图,且设置成嵌入显示。
%matplotlib inline
import torch
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import random
【这部分是相关包的导入】

1000行2列的
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs,
dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),
dtype=torch.float32)注意,features的每一行是一个长度为2的向量,而labels的每一行是一个
长度为1的向量(标量)。
【这里的size是1000个行 因为上面的label已经计算好了】
print(features[0], labels[0])
【这个是输出feature的第一个量和label的第一个结果】
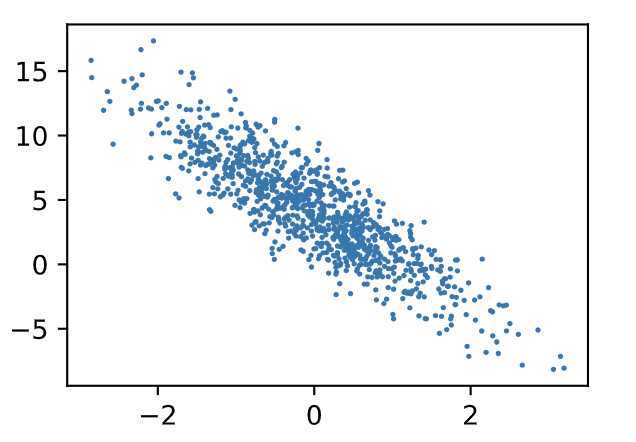
通过生成第二个特征features[:, 1]和标签 labels 的散点图,可以更直观地观察两者间的线性关系。
【这里只看第二个和label之间的关系图
其实正常来说是2个方向对label的关系图
应该是个3维图
但是现在这样看的话像是投影 只有2个方向
是个2维的
】
def use_svg_display():
# 用矢量图显示
display.set_matplotlib_formats(‘svg‘)
def set_figsize(figsize=(3.5, 2.5)):
use_svg_display()
# 设置图的尺寸
plt.rcParams[‘figure.figsize‘] = figsize
# # 在../d2lzh_pytorch里面添加上面两个函数后就可以这样导入
# import sys
# sys.path.append("..")
# from d2lzh_pytorch import *
set_figsize()
plt.scatter(features[:, 1].numpy(), labels.numpy(), 1);
【这里的 display.set_matplotlib_formats(‘svg‘)是 用矢量图表示的额意思然后放到 了函数里面进去了】
【pylot使用rc配置文件来自定义图形的各种默认属性,称之为rc配置或rc参数。通过rc参数可以修改默认的属性,包括窗体大小、每英寸的点数、线条宽度、颜色、样式、坐标轴、坐标和网络属性、文本、字体等。】
【所以 plt.rcParams[‘figure.figsize‘] = figsize这个是说这个矢量图的大小
】
【plt.scatter(features[:, 1].numpy(), labels.numpy(), 1);这个在把1去掉的时候 描出来的点很大 就很混乱
但是设置为1的话 就很清晰
】
我们将上面的plt作图函数以及use_svg_display函数和set_figsize函数定义在d2lzh_pytorch包里。以后在作图时,我们将直接调用d2lzh_pytorch.plt。由于plt在d2lzh_pytorch包中是一个全局变量,我们在作图前只需要调用d2lzh_pytorch.set_figsize()即可打印矢量图并设置图的尺寸。
原书中提到的
d2lzh里面使用了mxnet,改成pytorch实现后本项目统一将原书的d2lzh改为d2lzh_pytorch。
#Mxnet的数据格式为NDArray,当需要读取可观看的数据,就要调用:.asnumpy()
————————————————————————————---
在训练模型的时候,我们需要遍历数据集并不断读取小批量数据样本。这里我们定义一个函数:它每次返回batch_size(批量大小)个随机样本的特征和标签。
# 本函数已保存在d2lzh包中方便以后使用
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # 最后一次可能不足一个batch
yield features.index_select(0, j), labels.index_select(0, j)
【
indices = list(range(num_examples))这个应该是凑这个列表出来
这样好拿来索引
然后shuffle是打乱顺序
这个很好理解
接着是range(0, num_examples, batch_size):是指从0到最后 按照样本大小进行步进 也就是一次取多少个样本
然后是torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) 这个是说取成long型的
然后从i取起的batch个样本 然后最后一个参数是这个样本的总大小
这个i累次加batch最后可能会超过这最大值 所以这里min刚刚好
最后的yield在其他博客中有 是类似return的
然后这个features.index_select(0, j), labels.index_select(0, j)是说在features中按行取出j中对应的行
0指的是行这个维度
j指的要被取的行
】
++++++++++++++++++++++
让我们读取第一个小批量数据样本并打印。每个批量的特征形状为(10, 2),分别对应批量大小和输入个数;标签形状为批量大小。
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, y)
break
原文:https://www.cnblogs.com/c2d3dmm/p/12819287.html