首先打开网址,进入网站的首页。网站有游客游览模式和用户登录模式,建议先注册登录一个账号,也是十分简便的啦,因为这样可以使用更多的功能。
页面头部有三个选项,分别为VisualPytorch, 帮助和联系我们,VisualPytorch就是主页面,可以进行模型的搭建,帮助页面是本网站的简单教程以及相关知识的讲解,在联系我们界面,可以给我们反馈你在使用过程中的遇到的问题,帮助我们进步呀。

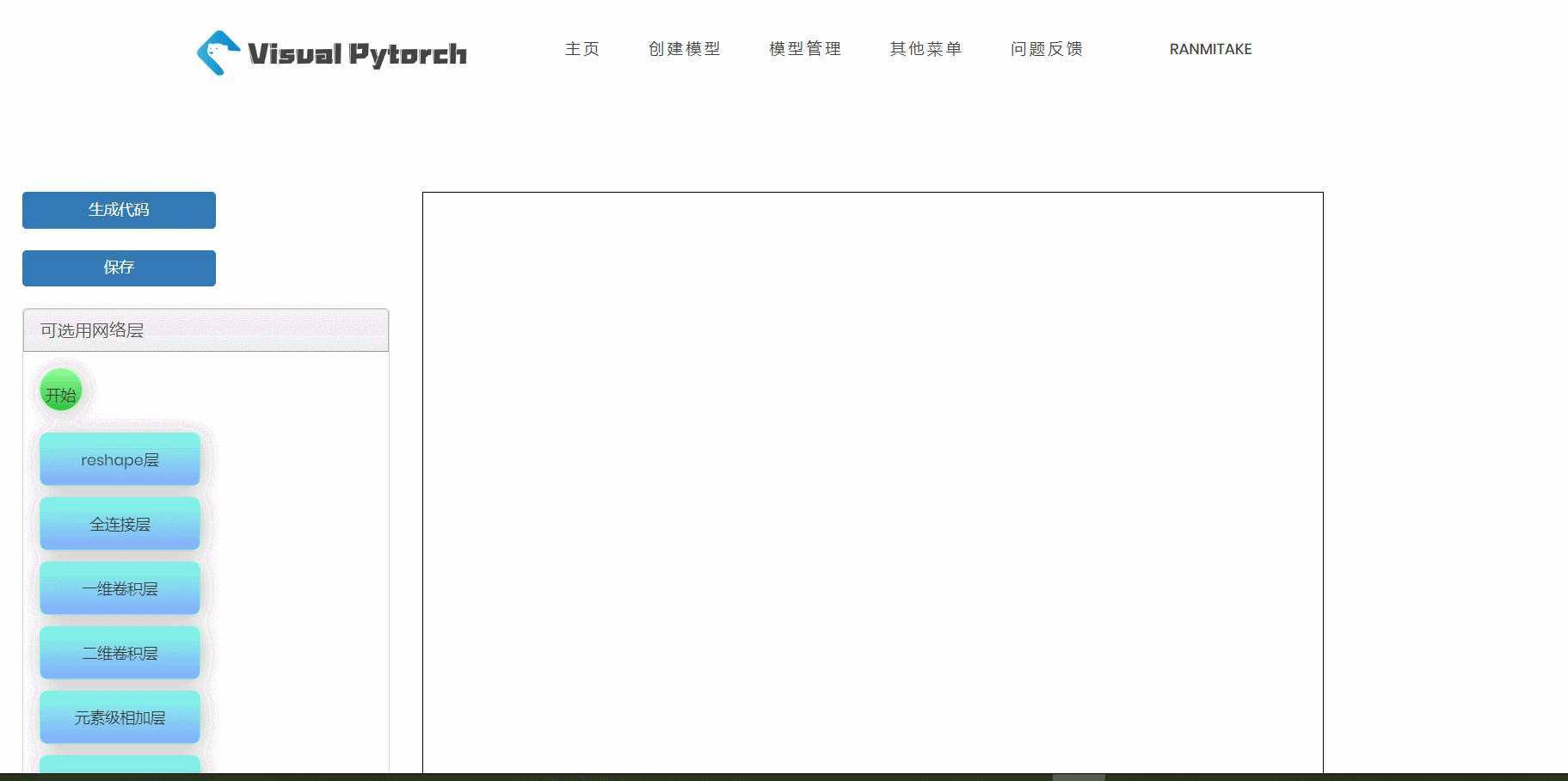
在VisualPytorch界面左侧有可选择的网络层,这些层就是用来搭建神经网络模型的基本组件,在网络层的下面还有训练参数配置,主要用于确定模型的全局训练参数。下面给大家简单展示一下如何拖拽和删除这些组件框,以及组件框参数的位置。

在VisualPytorch界面左上角有生成代码按钮,当你搭建好自己的神经网络模型之后,就可以点击这个按钮,然后会跳转到代码页面,你也就可以看到生成的代码啦,然后再点击下载代码,就可以把代码下载到本地,畅快的玩耍一番啦。

考虑到也许后续还要用自己搭建过的模型,所以我们实现了保存模型这一功能(贴心的团队,有木有),当你搭建好一个模型之后,可以直接选择保存,然后模型就会保存到你的账号啦,下次你登录还可以查看自己之前的模型。
我们的网站旨在利用清晰的可视化模型来帮助热爱deep learning的你快速搭建想搭建的模型。
目前支持的神经网络层有:reshape层,全连接层,一维卷积层,二维卷积层; 这些层及其涉及的参数的具体含义都与pytorch官方文档里一致。
模型的搭建通过将左侧的各类层模块拖入右侧画布并连线来完成。
main.py里的代码主要是涉及全局的参数以及训练部分,目前该部分还有待完善。
model.py里则主要是搭建的模型代码,整个模型我们封装成了一个类,类名是 NET。
注册用户拥有保存自己搭建的模型并管理的权限,用户可以通过点击页面上显示的用户名,弹出 模型查看 和 登出 选项,点击模型查看即可进入模型管理的页面,该页面会显示用户曾搭建并保存的所有模型,每个模型都有对应的 查看 和 删除 按钮。点击查看即可进入模型搭建的页面并恢复用户曾保存的模型,用户可以对该模型进行重新编辑。点击删除即可删除相应的模型。
VGG卷积神经网络是牛津大学在2014年提出来的模型,它在图像分类和目标检测任务中都表现出非常好的结果。同时,VGG16模型的权重由ImageNet训练而来。
AlexNet是2012年ImageNet项目的大规模视觉识别挑战中的胜出者,该项目一种巧妙的手法打破了旧观念,开创了计算机视觉的新局面。
一种新型的深度网络结构,它可以增强模型在感受野内对局部区域的辨别能力。
返回一个有相同数据但大小不同的tenser。返回的tenser必须有与原tenser相同的数据和相同数目的元素,但可以有不同的大小。一个tenser必须是连续的contiguous()才能被查看。
简单来看,view的参数就好比一个矩阵的行和列的值,当为一个数n的时候,则将数据大小变为1xn。
参数:
对输入数据做线性变换:y*=*Ax+b
参数:
形状:
变量:
该层不需要参数,作为几个层之间的衔接,需要注意的是,该函数的输入可以为多个向量。
在给定维度上对输入的张量序列seq 进行连接操作。
torch.cat()可以看做 torch.split() 和 torch.chunk()的反操作。 cat() 函数可以通过下面例子更好的理解。
参数:
函数表达式:
\(Softmax(x_i)=\frac{e^{x_i}}{\sum_j e^{x_j}}\)
返回:
参数:
type<下拉框,包括1d/2d/3d> 默认值为2d
p<0-1间实数>:置0概率 默认值为0.5
layer_type<下拉框二选一,conv/conv_transpose> - 分别表示卷积与反卷积 默认值为conv
conv和conv_transpose参数相同
形状:
变量:
tensor) - 卷积的权重,大小是(out_channels, in_channels, kernel_size)tensor) - 卷积的偏置系数,大小是(out_channel)在神经网络中,池化函数(Pooling Function)一般将上一层卷积函数的结果作为自己的输入。经过卷积层提取过特征之后,我们得到的通道数可能会增大很多,也就是说数据的维度会变得更高,这个时候就需要对数据进行池化操作,也就是降维操作。
池化操作是用每个矩阵的最大值或是平均值来代表这个矩阵,从而实现元素个数的减少,并且最大值和平均值操作可以使得特征提取具有“平移不变性”。
layer_type<下拉框三选一,选项包括max_pool, avg_pool, max_unpool > 默认值为max_pool
对由几个输入平面组成的输入信号进行最大池化。一般情况下我们只需要用到type, kernel_size, stride=None, padding=0这些参数。
参数:
对由几个输入平面组成的输入信号进行平均池化。一般情况下我们只需要用到type, kernel_size, stride=None, padding=0这些参数。
参数:
参数:
type(下拉框三选一,选项包括1d/2d/3d) : 卷积形式 默认值为2d
kernel_size <正整数> : 卷积核的尺寸 默认值为2
stride<正整数> : 卷积步长 默认值为2
padding<非负整数> : 补充0的层数 默认值为0
激活函数作用在人工神经网络上,负责将神经元的输入映射到输出端。增加了神经网络的非线性,使得神经网络可以任意逼近任意非线性函数,从而使神经网络应用到众多的非线性模型中。
layer_type<下拉框,包括relu/sigmoid/tanh/leaky relu/PRelu/RRelu> 默认值为relu
函数表达式:
\(relu(x)=max(0,x)\)
对应图像:

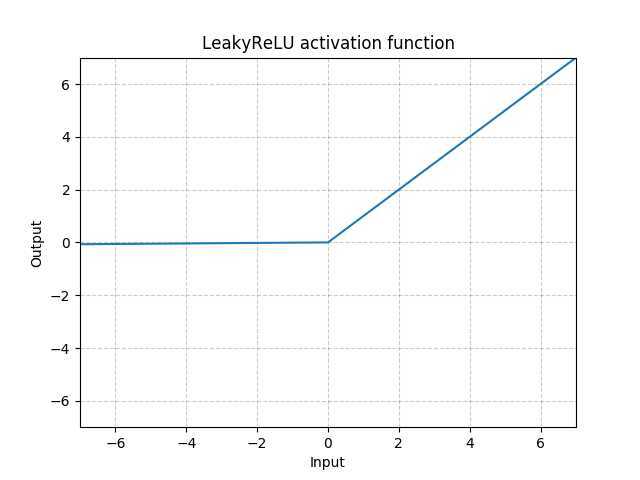
函数表达式:
\(LeakyRelu(x)=max(x,0) + negative\_slope*min(0,x)\)
参数:
对应图像:
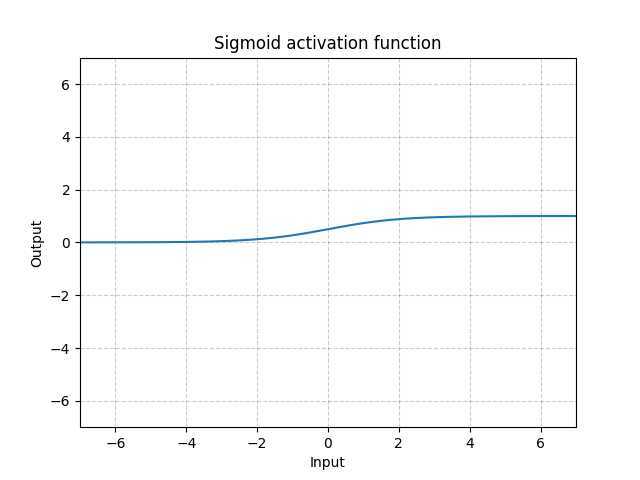
函数表达式:
\(sigmoid(x)=\frac{1}{1+e^{-x}}\)
函数图像:
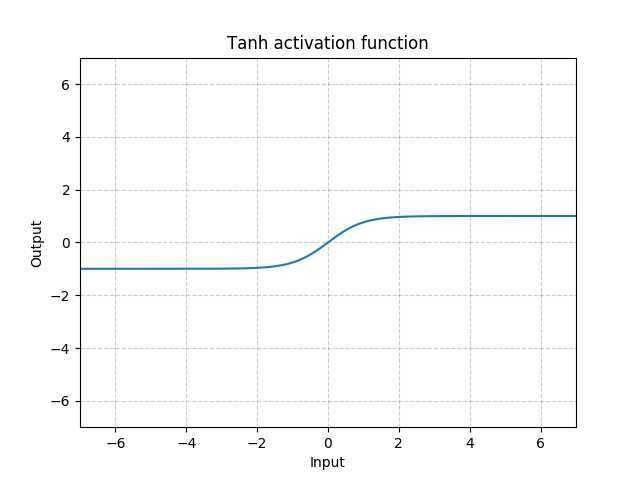
函数表达式:
\(tanh(x)=\frac{e^x-e^{-x}}{e^x+e^-x}\)
函数图像:
类似leaky relu, 但是负数部分斜率可学习
参数:
类似leaky relu, 但是负数部分斜率为随机均匀分布
参数:
lower<正数> - 均匀分布下限 默认值为0.125
upper<正数> - 均匀分布上限 默认值为0.333
参数:
input_size<正整数> - 输入特征数 无默认值
hidden_size<正整数> - 隐藏层个数 无默认值
num_layers<正整数> - 递归层层数 默认值为1
nonlinearity<二选一,tanh/relu> - 非线性激活 默认为tanh
参数:
input_size<正整数> - 输入特征数 无默认值
hidden_size<正整数> - 隐藏层个数 无默认值
num_layers<正整数> - 递归层层数 默认值为1
layer_type<下拉框,选项包括batch_norm/group_norm/instance_norm> 默认值为batch_norm
参数:
type<下拉框,包括1d/2d/3d> 默认值为2d
num_features<正整数>:输入特征数 无默认值
参数:
num_groups<正整数> - input_channel分组数 无默认值
num_channel<正整数> - input_channel个数无默认值
instance_norm参数:
type<下拉框,包括1d/2d/3d> 默认值为2d
num_features<正整数> - 输入特征数 无默认值
epoch<正整数> - 全数据集训练次数 默认值为10
learning_rate<0-1内实数> - 学习率 默认值为0.01
batch_size<正整数> - 每次训练个数 默认值为1
dataset<下拉框,共包含mnist,cifar10,stl10,svhn,jena,glove> - 训练数据集 默认值为mnist
ifshuffle<勾选框,默认为勾选,在json中为True,否则为False> - 是否打乱数据集 默认为true
platform<下拉框,共包含CPU,GPU> - 运行平台 默认CPU
下拉框,共包括StepLR, MultiStepLR, ExponentialLR, CosineAnnealingLR,ReduceLROnPleateau,None 默认值为None
step_size<正整数> - 衰减周期 默认值为50
gamma<0-1内实数> - 衰减幅度 默认值0.1
milestones<非负整数序列,同维度数字之间以英文的“,”分开,例如1,2,3,4,5> - 衰减时间点 默认值为50
gamma<0-1内实数> - 衰减幅度 默认值0.1
T_max<正整数> - 下降周期(变化的半周期)默认值为50
eta_min<正数> - 最小学习率 默认值为0
监控指标,当指标不再变化则调整
下拉框,共包含SGD,RMSprop,Adam,Adamax,ASGD 默认值为Adam
Stochastic Gradient Descent
Averaged Stochastic Gradient Descent
无穷范数的Adam的变体
下拉框,共包含MSELoss,CrossEntropyLoss,L1Loss,NLLLoss,BCELoss 默认值为MSELoss
均方误差
交叉熵损失
mean absolute error(MAE)
negative log likelihood loss
Binary Cross Entropy between the target and the output
本教程部分参考了PyTorch中文手册和PyTorch官方文档,如果想要更详细深入了解的请访问该手册和文档。
若觉得官方文档较难读懂,先看以下个人博客:
原文:https://www.cnblogs.com/NAG2020/p/12821489.html