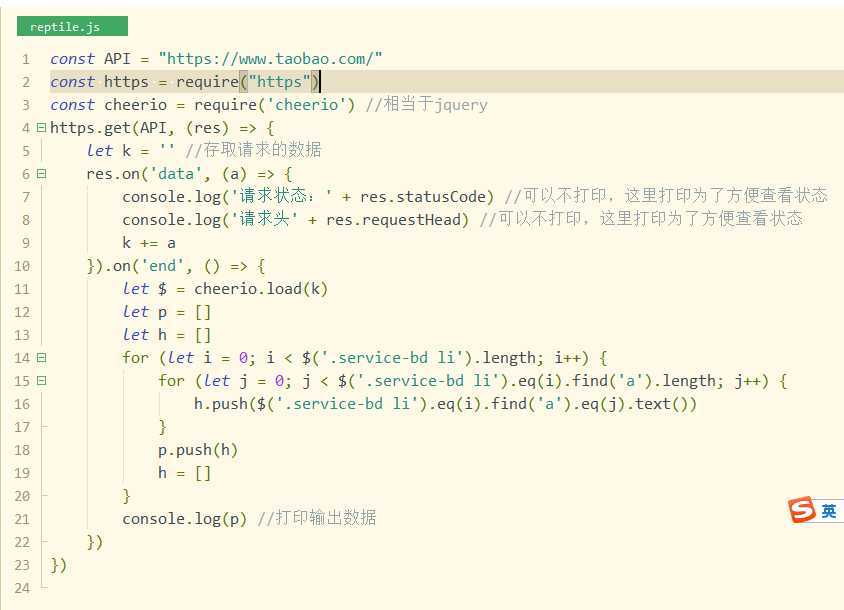
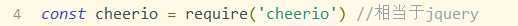这里我以 https://www.taobao.com/ 为例演示,爬取网页上的数据
首先把我们要爬取的网站用一个变量存取起来,方便使用
由于我们要请求的地址是https请求,所以我们要引入https模块,这是node自带模块,无需安装
接着使用https请求网页数据
这里我获取的是淘宝导航的数据,以数组方式输出
响应结束后我们要拿到我们想要的数据,这里需要用到 cheerio 模块,控制台输入 npm i cheerio -S 进行安装并引入模块
里面的逻辑我就不过多解释了,不懂得可以私聊我,我们看看总代码
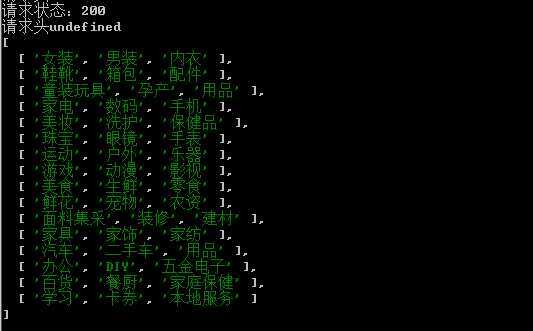
最后控制台运行查看结果
这样就大功告成了
原文:https://www.cnblogs.com/zlf1914/p/12825838.html