Spark只支持两种RDD操作,transformation和action操作,transformation针对已有的RDD创建一个新的RDD文件,action主要是对RDD进行最后操作,比如遍历和reduce、保存到文件等,并可以返回结果到Driver程序
transformation,都具有lazy特性,只定义transformation操作是不会执行,只有接着执行一个action操作后才会执行。通过lazy特性避免产生过多中间结果。
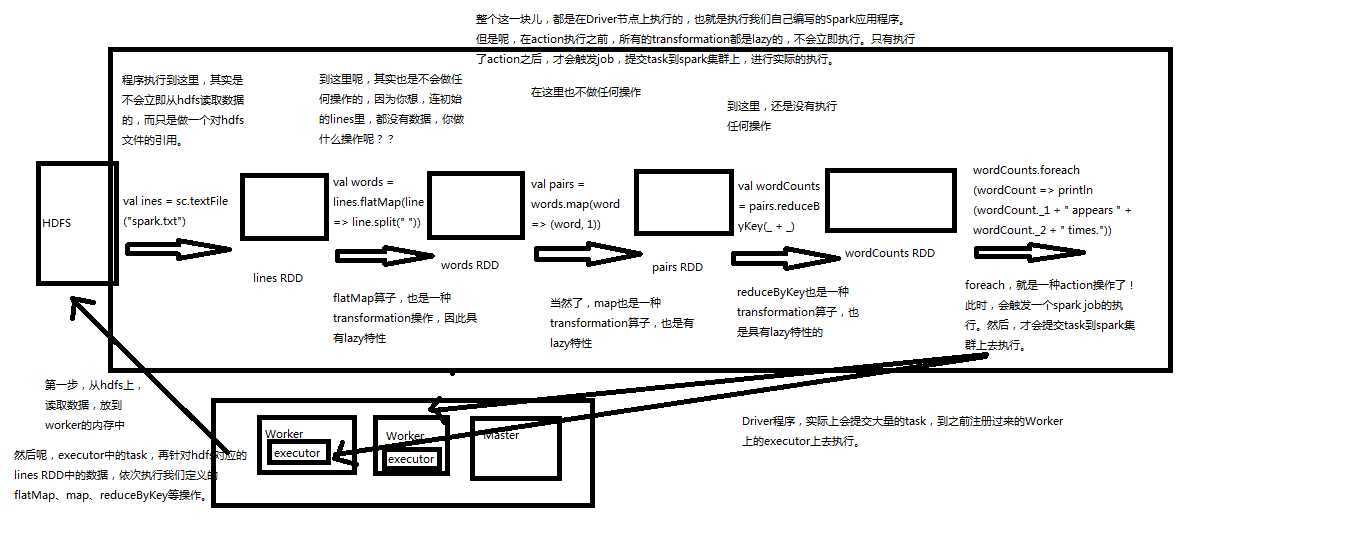
wordcount程序就是如下执行流程,如下这块都在driver节点执行。所有transformation都是lazy,不会立即执行,只有执行了action后,才会触发job,提交task到spark集群上,进行实际的执行
文件行统计
package cn.spark.study.core; import org.apache.spark.SparkConf; import org.apache.spark.SparkContext; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import org.codehaus.janino.Java; import scala.Tuple2; /** * @author: yangchun * @description: * @date: Created in 2020-05-04 21:55 */ public class LineCount { public static void main(String[] args) { SparkConf sparkConf = new SparkConf().setAppName("lineCount").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); JavaRDD<String> lines = sc.textFile("E:\\spark\\hello.txt"); JavaPairRDD<String,Integer> pairs = lines.mapToPair(new PairFunction<String, String, Integer>() { @Override public Tuple2<String, Integer> call(String s) throws Exception { return new Tuple2<>(s,1); } }); JavaPairRDD<String,Integer> lineCounts = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }); lineCounts.foreach(new VoidFunction<Tuple2<String, Integer>>() { @Override public void call(Tuple2<String, Integer> lineCount) throws Exception { System.out.println(lineCount._1+" appeared "+lineCount._2+" times"); } }); } }
package cn.spark.study.core; import org.apache.spark.SparkConf; import org.apache.spark.SparkContext; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import org.codehaus.janino.Java; import scala.Tuple2; /** * @author: yangchun * @description: * @date: Created in 2020-05-04 21:55 */ public class LineCount { public static void main(String[] args) { SparkConf sparkConf = new SparkConf().setAppName("lineCount").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); JavaRDD<String> lines = sc.textFile("E:\\spark\\hello.txt"); JavaPairRDD<String,Integer> pairs = lines.mapToPair(new PairFunction<String, String, Integer>() { @Override public Tuple2<String, Integer> call(String s) throws Exception { return new Tuple2<>(s,1); } }); JavaPairRDD<String,Integer> lineCounts = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }); lineCounts.foreach(new VoidFunction<Tuple2<String, Integer>>() { @Override public void call(Tuple2<String, Integer> lineCount) throws Exception { System.out.println(lineCount._1+" appeared "+lineCount._2+" times"); } }); } }
| 操作 | 介绍 |
| map | 将RDD中的每个元素传入自定义函数,获取一个新的元素,然后用新的元素组成新的RDD |
| filter | 对RDD中的元素进行判断,如果返回true则保留,返回false则剔除 |
| flatMap | 与map类似,但是对每个元素都可以返回一个或多个新元素 |
| groupByKey | 根据key进行分组,每个key对应一个Iterable<Value> |
| reduceByKey | 对每个key对应的value进行reduce操作 |
| sortByKey | 对每个key对应的value进行排序操作 |
| join |
对两个包含<key,value>对的RDD进行join操作,每个key join上的pair,都会传入自定义函数进行处理 |
| co‘group | 同join,但是每个可以对应的Interable<value>都会传入自定义函数进行处理 |
action介绍
| 操作 | 介绍 |
| reduce | 将RDD元素进行聚合操作,第一个和第二个聚合,然后值与第三个依次类推 |
| collect | 将RDD中所有元素获取到本地客户端 |
| count | 获取RDD元素总数 |
| take(n) | 获取RDD前N个元素 |
| saveAsTextFile | 将RDD元素保存到文件中,对每个元素调用toString方法 |
| countByKey | 对每个Key进行count计数 |
| foreach | 对RDD中元素进行遍历 |
原文:https://www.cnblogs.com/xiaofeiyang/p/12828596.html