1)Local:运行在一台机器上
2)Standalone:构建一个基于 Master+Slaves 的资源调度集群,Spark 任务提交给 Master 运行。是 Spark 自身的一个调度系统。
3)Yarn: Spark 客户端直接连接 Yarn,不需要额外构建 Spark 集群。有 yarn-client 和 yarn-cluster 两种模式,主要区别在于:Driver 程序的运行节点。
4)Mesos:比较少用。
1)提交任务时的重要参数
executor-cores —— 每个 executor 使用的内核数,默认为 1,官方建议 2-5 个,企业是 4 个
num-executors —— 启动 executors 的数量,默认为 2
executor-memory —— executor 内存大小,默认 1G
driver-cores —— driver 使用内核数,默认为 1
driver-memory —— driver 内存大小,默认 512M
2) 提交任务的样式
spark-submit \
--master local[5] \
--driver-cores 2 \
--driver-memory 8g \
--executor-cores 4 \
--num-executors 10 \
--executor-memory 8g \
--class PackageName.ClassName XXXX.jar \
--name "Spark Job Name" \
InputPath \
OutputPath
YarnCluster模式
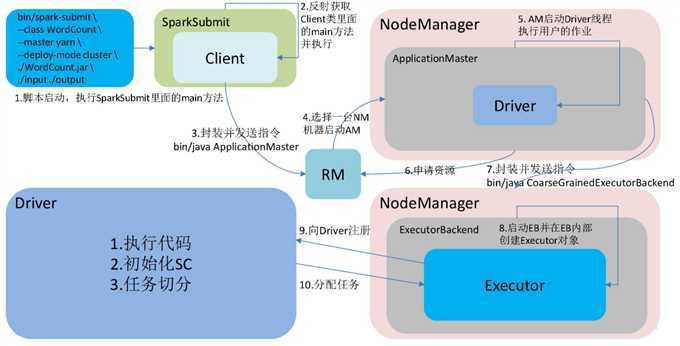
原文:https://www.cnblogs.com/eugene0/p/12839567.html