1、spark都有哪些组件,每个组件的作用?
答:spark组件如下:
1)、master:管理集群和节点,不参与计算
2)、Driver:运行程序的main方法,创建spark context对象
3)、Worker:计算节点,进程本身不参与计算,向master汇报
4)、Executor:真正进行计算的组件(task)
5)、client:用户提交程序的入口
2、RDD、dataFrame、DataSet三者的概念、关系以及异同点和转换。
答:
1、概念:
1)、RDD:弹性分布式数据集,Spark中最基础的数据抽象,特点是RDD只包含数据本身。
优点:
①:编译时类型安全,编译的时候就能检测出类型错误
②:面向对象的编程风格:直接通过对象调用方法的形式来操作数据。
缺点:
①:序列化和反序列化性能开销大:无论是集群的通信,还是IO操作,度需要将对对此昂的结构和数据进行序列化和发序列化
②:GC的性能开销大:频繁的创建和销毁对象,增加了GC的负担
2)、dataFrame:也是一个分布式的数据容器,除了数据本身,记录了数据的结构信息。
优点:
DF通过引入schema(数据的结构信息)和off-heap(不在堆里的内存,使用操作系统上的内存),Spark通过schema就能够读懂数据,因此在通信和IO时候就只需要序列化和反序列化数据,而结构的部分就可以省略了;通过off-heap的引入,可以快速的操作数据,避免大量的GC。
缺点:
DF不是类型安全的,API也不是面向对象风格的。
3)、dataSet:面向对象的思想,将数据变成对象的属性。不仅包含数据本身和数据的结构信息,还包含了数据结构的类型。
优点:DS兼容了RDD和DF的优点,在以后spark的使用中,DS将会逐步替代RDD和DF的使用。
2、三者的关系:
RDD是最底层(spark1.0)----》dataFrame添加数据结构(spark1.3)-----》dataSet 将数据对象化,spark中最上层的数据抽象。(spark1.6)
DF是特殊的RDD,相当于RDD+schema,即RDD+表结构。可以将它看做数据库中的一张表,但是只知道这个“表”中的各个字段,不知道字段的数据类型。 DS是DF的父类,当DS中存储一个ROW(Row是一个类型,跟Car、Person这些的类型一样,所有的表结构数据都用Row来表示)时,两者等价(DataSet[Row] = DataFrame)
3、相同点:
1)、RDD,DataFrame、DataSet三者全是spark平台下的弹性分布式数据集,未处理大型数据提供便利。
2)、三者都是惰性执行。在执行创建、转换等算子时不会立即执行,只有遇到Action算子时候,才会开始遍历运算,极端情况下,如果代码里边有创建、转换,但事后边没有在Action中使用对应的结果,在执行时候会被跳过。
val conf=new SparkConf().setMaster("local").setAppName("test").set("spark.port.maxRetries","1000")
val sc =SparkSession.builder().config(conf).getOrCreat()
val rdd =sc.SparkContext.parallelize(Seq(("a",1),("b",1),("a",1)))
//map不运行
rdd.map{line=>
println("运行")
line._1
}
3)、三者都会根据Spark的内存情况自动缓存运算,这样即使数据量大,也不用担心内存溢出。
4)、三者都有partition的概念
5)、三者都有许多共同函数,如 filter,排序等
6)、在DataFrame和DataSet进行操作时候度需要这个包进行支持
import spark.implicits._
7)、DataFrame和DataSet均可使用模式匹配获取各个字段的值和类型
4、三者的区别:
RDD:
1)、RDD不支持SparkSQL
2)、RDD 一般和spark mlib同时使用
DataFrame:
1)、与RDD和DS不同,DF每一行的类型固定为Row,只有通过解析后才能获取各个字段的值,每一列的值无法直接访问。
2)、DF与DS一般不和spark mlib同时使用
3)、DF和DS均支持是parkSQL操作,比如select,groupby之类,还能注册临时表/视图,进行SQL操作
dataDF.createOrReplaceTempView("tmp")
spark.sql("select Row,date from tmp where date is not null order by date").show(100,false)
4)、DF和DS度支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然。
//保存
val save=Map("heard"->true,"delimiter" -> "\t" , "path" -> "hdfs://master01:9000/test")
datawDF.write.format("com.myc.spark.csv").mode(SaveMode.Overwrite).options(save).save()
//读取
val options=Map("heard"->true,"delimiter" -> "\t" , "path" -> "hdfs://master01:9000/test")
val datarDF=spark.read.options(options).format("com.myc.spark.csv").load()
利用上述的保存方式,可以方便的获得字段和列的对应,并且分隔符(delimiter)可以自由指定。
5)、三者的转换:
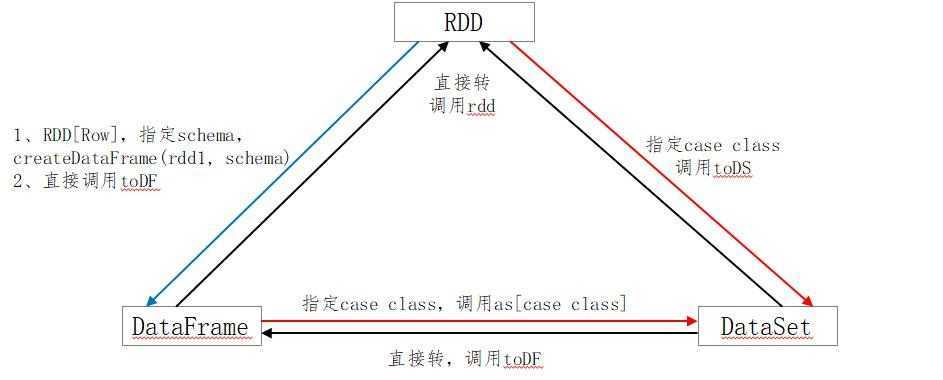
rdd---->dataFrame
//一般用元组把一行数据写在一起,然后在toDF中指定字段名
import spark.implicits._
val testDF = rdd.map{line =>
(line._1,line._2)
}.toDF("col1","col2")
rdd---->dataSet:
//核心是要定义case class
//一般用元组把一行数据写在一起,然后在toDF中指定字段名
import spark.implicits._
case class Coltest(col1:String,col2:Int)
val testDF = rdd.map{line =>Coltest(line._1,line._2)}.toDS
dataFrame----> rdd:
val rdd=testDF.rdd
dataSet----> rdd:
val rdd=testDS.rdd
dataFrame----> dataSet:
// 每一列的类型后,使用as方法(as后边还得跟case class,这个是核心),转成DataSet import spark.implicits._ case class Col1 ... ... ... val testDS =testDF.as[Col1]
dataSet----> dataFrame:
//将case class 封装成Row import spark.implicits._ val testDF = testDS.toDF
注意:
在使用一些特殊操作的时候,一定要加上 import spark.implicits._ ,否则toDF,ToDS无法使用。
三者的关系转换图:
3、Spark中的stage的定义。
答:一个job包含一个或多个stage,一个stage包含一个或多个task。
1)、Stage的task的数量由输入文件的切片个数来决定的,在HDFS中不大于128M的文件算是一个切片,通过算子修改某一个RDD的分区数量,task数量也会同步修改。
2)、Stage中的并行度取决于application任务运行时使用的executor拥有的cores的数量
3)、Spark任务会根据RDD之间的依赖关系,形成一个有向无环图DAG,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分为多个相互依赖的stage,划分依据就是宽依赖,遇到宽依赖就画风stage,每个stage包含一个或多个task,然后将这些task以taskSet的方式提交给TaskScheduler运行,stage是由一组并行的task组成。
-- Stage的划分标准:宽依赖
--切割规则:从后往前,遇到宽依赖就切割stage。
4、spark中的宽窄依赖
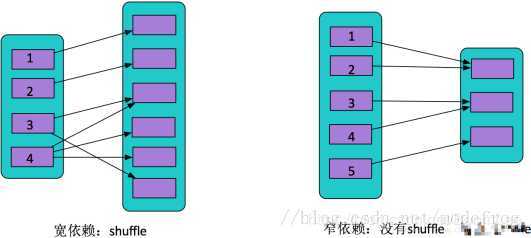
宽依赖:一对多,一个父RDD的partition对应多个子RDD的partition,有shuffle产生。例如groupByKey,reduceByKey,join,sortBykey等。
窄依赖:一对一,一个父RDD的partition对应一个子RDD的partition,没有shuffle产生。例如map,filter等等。
shuffle可以理解为数据从原分区打乱重组到新的分区。
总结:如果一个父RDD的一个partition被一个子RDD的partition所使用就是窄依赖,否则就是宽依赖。
原文:https://www.cnblogs.com/mayucheng123/p/12844365.html