一、目的
1、 熟悉jieba库和wordcloud库的使用方法;
2、 熟悉文本词频统计和词云生成的基本方法。
二、内容
1. 从网上自行下载一个长篇英文小说,统计并输出该小说中词频最大的TOP 20结果。利用该文本和wordcloud库、imageio库等,生成一个属于自己的词云图形。
代码:
1 import wordcloud 2 import imageio 3 image=imageio.imread("苹果.jpg") 4 f=open("Free Realms.txt","r").read() 5 txt=f.lower() 6 w=wordcloud.WordCloud(width=1000,font_path="msyh.ttc",height=700,7 mask=image,background_color="white") 8 w.generate(txt) 9 w.to_file("Free Realms.png")
所选图片:

运行结果:

2. 从网上自行下载一个长篇中文小说,统计并输出该小说中词频最大的TOP 20结果。利用该文本和jieba库、wordcloud库、imageio库等,生成一个属于自己的词云图形。
词频统计代码:
1 import jieba 2 txt=open(‘小王子.txt‘,‘r‘,encoding=‘utf-8‘).read() 3 words=jieba.lcut(txt) 4 counts={} 5 for word in words: 6 if len(word)==1: 7 continue 8 else: 9 rword=word 10 counts[rword]=counts.get(rword,0)+1 11 items=list(counts.items()) 12 items.sort(key=lambda x:x[1],reverse=True) 13 for i in range(20): 14 word,count=items[i] 15 print("{0:<10}{1:>5}".format(word,count))
运行结果:
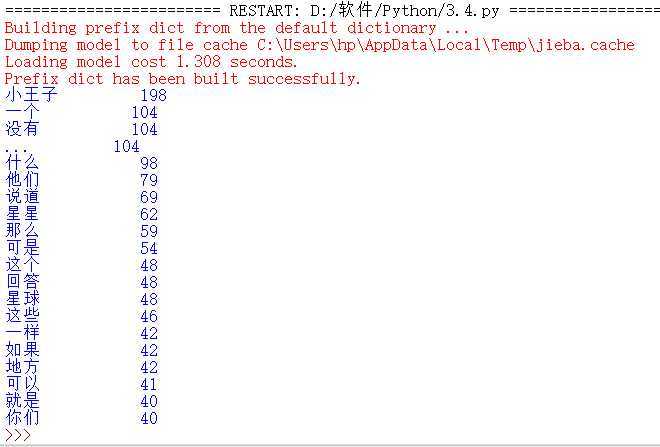
词云生成代码:
1 import jieba 2 import wordcloud 3 import imageio 4 image=imageio.imread("王冠.jpg") 5 6 f=open("小王子.txt",‘r‘,encoding="utf-8") 7 t=f.read() 8 f.close() 9 ls=jieba.lcut(t) 10 txt=" ".join(ls) 11 w=wordcloud.WordCloud(width=1000,font_path="msyh.ttc",height=700,12 mask=image,background_color="white") 13 w.generate(txt) 14 w.to_file("王冠耶.png")
所选图片:

运行结果:


三、实验总结
通过本次实验,掌握了集合与字典的定义及其操作使用方法;熟悉了jieba库和wordcloud库的使用方法;熟练掌握文本词频统计和词云生成的基本方法。对Python的了解又多了一层,在傲视的帮助下完成了此次实验,很棒。
原文:https://www.cnblogs.com/ynly/p/12843864.html