在PyTorch自定义数据集中,我们介绍了如何通过重写Dataset类来自定义数据集,但其实对于图像数据,自定义数据集有一个更简单的方法,那就是直接调用ImageFolder。
ImageFolder假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名,其构造函数如下:
ImageFolder(root, transform=None, target_transform=None, loader=default_loader)
各参数含义:
root:在root指定的路径下寻找图片
transform:对PIL Image进行的转换操作,transform的输入是使用loader读取图片的返回对象
target_transform:对label的转换
loader:给定路径后如何读取图片,默认读取为RGB格式的PIL Image对象
label是按照文件夹名顺序排序后存成字典,即{类名:类序号(从0开始)}
从kaggle官网下载dogsVScats的数据集(下载链接见文末),该数据集包含test1文件夹和train文件夹,train文件夹中包含12500张猫的图片和12500张狗的图片,图片的文件名中带序号:
cat.0.jpg cat.1.jpg cat.2.jpg ... cat.12499.jpg dog.0.jpg dog.1.jpg dog.2.jpg ... dog.12499.jpg
假设我们希望把train文件夹中90%猫的图片和90%狗的图片作为训练集,剩下的10%作为验证集:
import os
import shutil
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset
from torchvision import transforms, datasets
# kaggle原始数据集在本地电脑的文件路径
original_dataset_dir = ‘/Users/wangpeng/Desktop/all/CS/Datasets/kaggle_dogs_cats/train‘
total_num = int(len(os.listdir(original_dataset_dir)) / 2)
random_idx = np.array(range(total_num))
np.random.shuffle(random_idx)
# 待处理的数据集地址
base_dir = ‘/Users/wangpeng/Desktop/dogsVScats‘
if not os.path.exists(base_dir):
os.mkdir(base_dir)
# 训练集、验证集的划分
sub_dirs = [‘train‘, ‘validate‘]
animals = [‘cats‘, ‘dogs‘]
train_idx = random_idx[:int(total_num * 0.9)]
validate_idx = random_idx[int(total_num * 0.9):]
numbers = [train_idx, validate_idx]
for idx, sub_dir in enumerate(sub_dirs):
dir = os.path.join(base_dir, sub_dir)
if not os.path.exists(dir):
os.mkdir(dir)
for animal in animals:
animal_dir = os.path.join(dir, animal)
if not os.path.exists(animal_dir):
os.mkdir(animal_dir)
fnames = [animal[:-1] + ‘.{}.jpg‘.format(i) for i in numbers[idx]]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(animal_dir, fname)
shutil.copyfile(src, dst)
# 训练集、验证集的图片数目
print(animal_dir + ‘ total images : %d‘ % (len(os.listdir(animal_dir))))
划分并复制完成之后,在我的电脑的桌面上将会有一个dogsVScats文件夹,其文件结构如下:
dogsVScats | |----train | | | |---cats(包含11250张猫的图片) | |---dogs(包含11250张狗的图片) | |-----validate | |---cats(包含1250张猫的图片) |---dogs(包含1250张狗的图片)
接着我们就可以用ImageFolder创建数据集了,并把创建好的数据集放到DataLoader中:
data_transform = transforms.Compose([
transforms.Resize(256), # 把图片resize为256*256
transforms.CenterCrop(224), # 随机裁剪224*224
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
train_dataset = datasets.ImageFolder(root=‘/Users/wangpeng/Desktop/dogsVScats/train‘, transform=data_transform) # 标签为{‘cats‘:0, ‘dogs‘:1}
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=8, shuffle=True)
validate_dataset = datasets.ImageFolder(root=‘/Users/wangpeng/Desktop/dogsVScats/validate‘, transform=data_transform)
validate_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)
我们可以测试一下,看一下train_loader可不可以用了:
if __name__ == ‘__main__‘:
image, label = iter(train_loader).next() # iter()函数把train_loader变为迭代器,然后调用迭代器的next()方法
sample = image[0].squeeze()
sample = sample.permute((1, 2, 0)).numpy()
sample *= [0.229, 0.224, 0.225]
sample += [0.485, 0.456, 0.406]
sample = np.clip(sample, 0, 1)
plt.imshow(sample)
plt.show()
print(‘Label is: {}‘.format(label[0].numpy()))
运行结果:
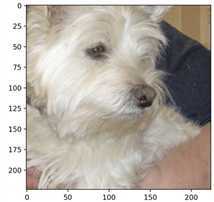
Label is: 1
同样的我们可以测试validate_loader,这里就不再赘述了。
原文:https://www.cnblogs.com/picassooo/p/12856042.html