任务型对话中的开源系统
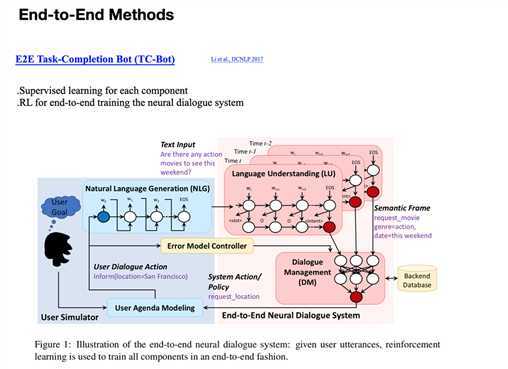
本文使用SL(监督学习)来监督每个模型部件的学习,同时RL(强化学习)做end-to-end的训练。虽然是End2End的方法,但是还是单独设计模型的部件,不同部件解决Pipeline方法中的某个或多个模块。
原文地址: https://arxiv.org/abs/1703.01008
网络结构:
微软+台湾
源码:https://github/com/MiuLab/TC-Bot
原文:https://www.cnblogs.com/xuehuiping/p/12835446.html