计算机网络基础
网络层次划分
为了是不同计算机厂家生产的计算机能够相互通信,以便在更大的范围内建立计算机网络,国际标准化组织(ISO)在1978年提出了“开放系统互联参考模型”,即著名的ISO/RM模型,他将计算机网络体系结构的通信协议划分为七层,自下而上依次为:物理层(PhysicsLayer)、数据链路层(DataLinkLayer)、网络层(Network Layer)、传输层(Transport Layer)、会话层(Session Layer)、表示层(Presentation Layer)、应用层(Application Layer)。其中第四层完成数据传送服务,上面三层面向用户。
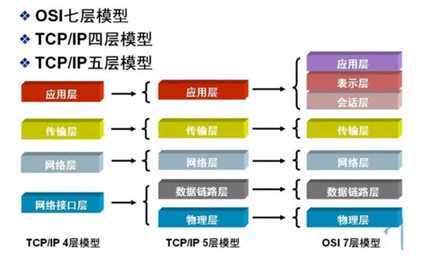
除了标准的OSI七层模型之外,常见的网络层次划分还有TCP/IP四层协议以及TCP/IP五层协议,它们之间的对应关系如下图所示:
拓展知识:如果想知道某个IP地址的详细信息,例如国家、城市、经纬度等信息,可以使用Python扩展库pygeoip配合数据库GeoLiteCity.dat来获取这些信息。其中pygeoip可以使用pip工具安装,GeoLiteCity.dat数据库可以从网上下载。当然,信息的准确程度主要取决于下载的数据库版本。
>>> import pygeoip
>>> gi = pygeoip.GeoIP(‘GeoLiteCity.dat‘)
>>> gi.record_by_name(‘221.0.95.247‘)
{‘longitude‘: 116.99720000000002, ‘area_code‘: 0, ‘region_code‘: ‘25‘, ‘country_name‘: ‘China‘, ‘dma_code‘: 0, ‘postal_code‘: None, ‘continent‘: ‘AS‘, ‘city‘: ‘Jinan‘, ‘time_zone‘: ‘Asia/Shanghai‘, ‘country_code‘: ‘CN‘, ‘country_code3‘: ‘CHN‘, ‘metro_code‘: None, ‘latitude‘: 36.66829999999999}
Socket编程
UDP和TCP是网络体系结构的运输层(也称为传输层)运行的两大重要协议。
TCP协议适用于对效率要求相对低而对准确性要求相对高的场合,例如文件传输、电子邮件等等;
而UDP协议适用于对效率要求相对高,对准确性要求相对低的场合,例如视频在线点播、网络语音通话等等。
在Python中,主要使用socket模块来支持TCP和UDP编程。
UDP协议编程
(首先启动一个命令提示符环境并运行接收端程序,这时接收端程序处于阻塞状态,接下来再启动一个新的命令提示符环境并运行发送端程序,此时会看到接收端程序继续运行并显示接收到的内容以及发送端程序所在计算机IP地址和占用的端口号。)
UDP适用于对效率要求相对较高而对准确性要求相对较低的场合,例如视频在线点播、网络语音通话等等。
!!!socket模块中经常用于UDP编程的方法主要有:
socket([family[,type[,proto]]]):创建一个socket对象,其中family为socket.AF_INET表示IPV4,socket.AF_INET6表示IPV6;type为SOCK_STREAM表示TCP协议,SOCK_DGRAM表示UDP协议。
sendto(string,address):把string指定的字节串内容发送给address指定的地址,address是一个元组,格式为(IP地址,端口号)
recvfrom(bufsize[,flags]):接收数据
实例:编写UDP通信程序,发送端发送一个字符串“Hello world!”。接收端在计算机的5000端口进行接收,并显示接收内容,如果收到字符串bye(忽略大小写)则结束监听。
发送端代码:
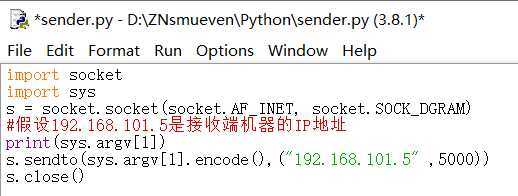

1 import socket 2 import sys 3 s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) 4 #假设192.168.101.5是接收端机器的IP地址 5 print(sys.argv[1]) 6 s.sendto(sys.argv[1].encode(),("192.168.101.5" ,5000)) 7 s.close()
接收端代码:
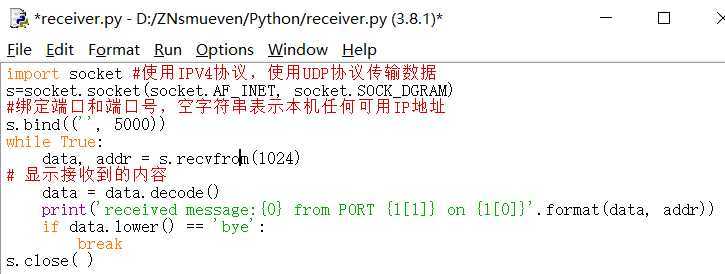
1 import socket 2 #使用IPV4协议,使用UDP协议传输数据 3 s=socket.socket(socket.AF_INET, socket.SOCK_DGRAM) 4 #绑定端口和端口号,空字符串表示本机任何可用IP地址 5 s.bind((‘‘, 5000)) 6 while True: 7 data, addr = s.recvfrom(1024) 8 # 显示接收到的内容 9 data = data.decode() 10 print(‘received message:{0} from PORT {1[1]} on {1[0]}‘.format(data, addr)) 11 if data.lower() == ‘bye‘: 12 break 13 s.close( )
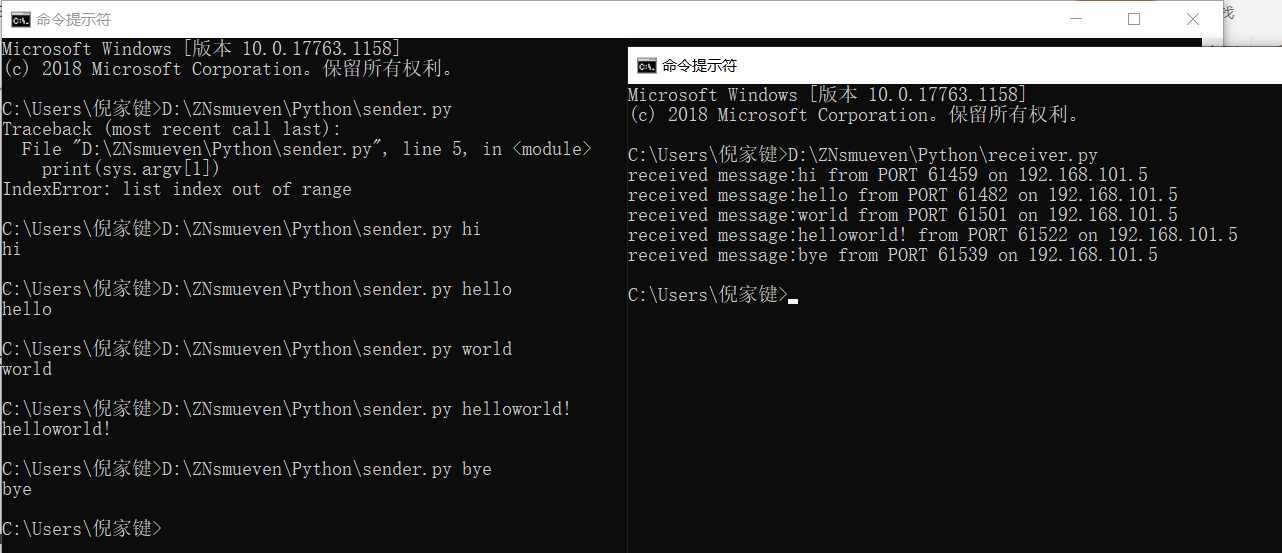
运行效果截图:
拓展知识:使用Python查看本机IP地址与网卡物理地址。

网络爬虫和自动化
requests库的使用
安装requests库:采用pip 指令安装requests 库,如果在Python 2 和Python 3 并存的系统中,采用pip3 指令:\>pip install requests # 或者 pip3 install requests
requests库的概述
requests 库是一个简洁且简单的处理HTTP请求的第三方库,其最大优点是程序编写过程更接近正常URL 访问过程。request 库支持非常丰富的链接访问功能,包括:国际域名和URL 获取、HTTP 长连接和连接缓存、HTTP 会话和Cookie 保持、浏览器使用风格的SSL 验证、基本的摘要认证、有效的键值对Cookie 记录、自动解压缩、自动内容解码、文件分块上传、HTTP(S)代理功能、连接超时处理、流数据下载等。有关requests 库的更多介绍请访问:
http://docs.python‐requests.org
| 函数 | 描述 |
| get(url[,timeout=n]) | 对应于HTTP的GET方式,获取网页最常用的方法,可以增加timeout=n参数,设定每次请求超时时间为n秒 |
| post(url,data={‘key‘:‘value‘}) | 对应于HTTP的POST方式,其中字典用于传递客户数据 |
| delete(url) | 对应于HTTP的DELETE方式 |
| head(url) | 对应于HTTP的HEAD方式 |
| options(url) | 对应于HTTP的OPTIONS方式 |
| put(url,data={‘key‘:‘value‘}) | 对应于HTTP的PUT方式,其中字典用于传递客户数据 |
get()是获取网页最常用的方式,其中,get()函数的参数url 必须链接采用HTTP 或HTTPS方式访问,在调用requests.get()函数后,返回的网页内容会保存为一个Response 对象,
返回内容作为一个对象更便于操作,Response 对象的属性如下表所示,需要采用<a>.<b>形式使用。
| 属性 | 描述 |
| status_code | HTTP请求的返回状态,整数200表示连接成功,404表示失败。在处理数据之前要先判断状态情况,如果请求未被响应,需要终止内容处理。 |
| text | HTTP响应内容的字符串形式,即是url对应的页面内容 |
| encoding | HTTP响应内容的编码形式,可以通过对encoding 属性赋值更改编码方式,以便于处理中文字符 |
| content | HTTP响应内容的二进制形式 |


Response 对象的方法
| 方法 | 描述 |
| json() | 如果HTTP相应内容包括JSON格式数据,该方法解析JSON数据 |
| raise_for_status() | 只要返回的请求状态status_code 不是200,这个方法会产生一个异常,用于try…except 语句。使用异常处理语句可以避免设置一堆复杂的if 语句,只需要在收到响应调用这个方法,就可以避开状态字200 以外的各种意外情况。 |
requests 会产生几种常用异常。当遇到网络问题时,如:DNS 查询失败、拒绝连接等,requests 会抛出ConnectionError 异常;遇到无效HTTP 响应时,requests 则会抛出HTTPError 异常;若请求url 超时,则抛出Timeout 异常;若请求超过了设定的最大重定向次数,则会抛出一个TooManyRedirects 异常。
获取一个网页
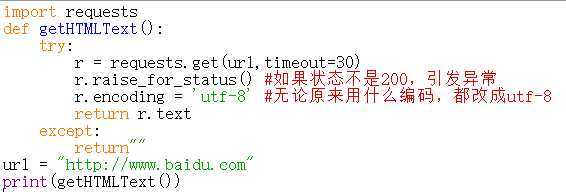
1 import requests 2 def getHTMLText(): 3 try: 4 r = requests.get(url,timeout=30) 5 r.raise_for_status() #如果状态不是200,引发异常 6 r.encoding = ‘utf-8‘ #无论原来用什么编码,都改成utf-8 7 return r.text 8 except: 9 return"" 10 url = "http://www.baidu.com" 11 print(getHTMLText())
结果如图:

原文:https://www.cnblogs.com/ni23/p/12861103.html
