本文中的排序皆以升序(从小到大)来排列,参考博客:
https://www.jianshu.com/p/bbbab7fa77a2
https://www.cnblogs.com/aishangJava/p/10092341.html
https://www.cnblogs.com/onepixel/articles/7674659.html
冒泡排序会重复遍历数组,每次比较相邻的两个元素,如果顺序错误,则交换两个元素.
def bubble_sort(items, comp=lambda x, y: x > y): """冒泡排序, 比较相邻的元素, 满足条件则交换位置""" length = len(items) for i in range(length): for j in range(1, length - i): if comp(items[j - 1], items[j]): items[j - 1], items[j] = items[j], items[j - 1] return items
若我们在某次遍历的过程中没有发生交换,说明数组已经完成排序,那么就可以退出循环.可以设置一个标记,来判断上一次循环中是否发生了元素交换,若没发生则跳出循环.
def bubble_sort(items, comp=lambda x, y: x > y): """冒泡排序, 比较相邻的元素, 满足条件则交换位置""" length = len(items) for i in range(length): swapped = False for j in range(1, length - i): if comp(items[j - 1], items[j]): items[j - 1], items[j] = items[j], items[j - 1] swapped = True if not swapped: # 某一次遍历没有发生任何交换,说明已经排序完成,退出 break return items
假设有一个数组[2,1,4,6,5,3,8,9],在第一次遍历时,最后发生交换的元素是3和6,那么从6开始的后面的元素必然是排好序的
那么我们在每一次遍历时,记录下最后一次发生交换的位置,这样我们下一次遍历的范围就是(0-最后发生交换的位置)
def bubble_sort(items, comp=lambda x, y: x > y): """冒泡排序, 重复比较相邻的元素, 满足条件则交换位置""" length = len(items) last_index = length for i in range(length): swapped = False for j in range(1, last_index): if comp(items[j - 1], items[j]): items[j - 1], items[j] = items[j], items[j - 1] swapped = True last_index = j # 记录最后发生交换的位置, 这里last_index会在循环结束后再改变值 if not swapped: # 某一次遍历没有发生任何交换,说明已经排序完成,退出 break return items
选择排序,首先在未排序序列中找到最小的元素,存放到排序序列的起始位置,然后再从剩余未排序元素中继续寻找最小元素,以此类推,直到排序完
无论是什么数据,选择排序都会遍历n-1次序列,时间复杂度为O(n2)
def select_sort(items, comp=lambda x, y: x < y): """简单选择排序, 默认从小到大排序""" length = len(items) for i in range(length - 1): min_index = i for j in range(i + 1, length): if comp(items[j], items[min_index]): min_index = j items[i], items[min_index] = items[min_index], items[i] return items
插入排序,对于每个未排序的数据,在已排序的序列中从后往前扫描,找到相应的位置并插入.
def insert_sort(items, comp=lambda x, y: x > y): length = len(items) for i in range(1, length): key = i - 1 # 已排序的序列长度 mark = items[i] # 要插入的元素 while key >= 0 and comp(items[key], mark): # 步骤3 items[key+1] = items[key] # 将元素往后移一位 key -= 1 # 重复步骤3 items[key+1] = mark # 步骤5 return items
希尔排序也称递减增量排序,是插入排序的一种更高效的改进版本.
希尔排序先将整个待排序的序列分割为若干个子序列分别进行插入排序,这样整个序列会变得"基本有序",然后再对整个序列进行插入排序
def shell_sort(items, comp=lambda x, y: x > y): length = len(items) gap = 1 while gap < length // 3: gap = gap * 3 + 1 # 动态定义间隔序列 while gap > 0: for i in range(gap, length): key = i - gap mark = items[i] # 待插入的元素 while key >= 0 and comp(items[key], mark): items[key + gap] = items[key] key -= gap items[key + gap] = mark gap //= 3 # 下一个动态间隔 return items
归并排序采用分治法,先把序列一直二分,直到所有子序列长度为1, 然后两两合并为一个有序序列
def merge_sort(items, comp=lambda x, y: x < y): """归并排序--递归实现""" def merge(left, right): result = [] # 保存归并后的结果 i = j = 0 while i < len(left) and j < len(right): if comp(left[i], right[j]): result.append(left[i]) i += 1 else: result.append(right[j]) j += 1 result = result + left[i:] + right[j:] return result if len(items) < 2: return items mid = len(items) // 2 left1 = merge_sort(items[:mid], comp) right1 = merge_sort(items[mid:], comp) return merge(left1, right1)
def merge_sort1(items, comp=lambda x, y: x < y): """归并排序--迭代实现""" def merge(head1, head2, tail2): """ 当序列的头大于序列尾时,说明该序列已完成排序,若此时另一个序列还未完成排序,则该序列中的未排序的元素 全部都在已排序序列的后面,当左序列和右序列都完成排序后,用排完序的序列替换原序列 :param head1: 左序列的头 :param head2: 右序列的头 :param tail2: 右序列的尾 :return: 排序后的序列 """ result = [] # 保存归并后的结果 tail1 = head2 - 1 # 左序列的尾 start = head1 # 插入的位置 while head1 <= tail1 or head2 <= tail2: if head1 > tail1: # 说明左序列已经完成了排序 result.append(items[head2]) head2 += 1 elif head2 > tail2: # 说明右序列已经完成了排序 result.append(items[head1]) head1 += 1 else: if comp(items[head1], items[head2]): result.append(items[head1]) head1 += 1 else: result.append(items[head2]) head2 += 1 for i in range(tail2 - start + 1): # 替换 items[start + i] = result[i] return items length = len(items) step = 1 while step <= length: offset = step * 2 for index in range(0, length, offset): merge(index, min(index + step, length - 1), min(index + offset - 1, length - 1)) step *= 2 return items
快速排序是对冒泡排序的改进,通过多次比较和交换来实现排序

def quick_sort(items, comp=lambda x, y: x < y): """快速排序, 这种写法平均空间复杂度为O(n log n)""" if len(items) < 2: return items pivot = items[0] # 基准值 left = [items[i] for i in range(1, len(items)) if comp(items[i], pivot)] # 左数组 right = [items[i] for i in range(1, len(items)) if not comp(items[i], pivot)] # 右数组 return quick_sort(left) + [pivot] + quick_sort(right) # 拼接 def quick_sort1(items, leftNum=None, rightNum=None, comp=lambda x, y: x < y): """ 快速排序,这种写法的平均空间复杂度为O(log n) :param items: 待排序数组 :param leftNum: 数组上界 :param rightNum: 数组下界 :param comp: 正序或反序 """ def partition(left, right): pivot = items[left] # 基准值 while left < right: while left < right and not comp(items[right], pivot): # 判断右边数组的值是否大于基准值,若大于则继续从右边遍历,若小于则跳出循环 right -= 1 items[left] = items[right] # 把右边数组中小于基准值的数据放到左边数组中,因为左边数组第一个就是基准值,所以数据不会丢失 while left < right and comp(items[left], pivot): # 判断左边数组的值是否小于基准值,若小于则继续从左边遍历,若大于则跳出循环 left += 1 items[right] = items[left] # 把左边数组中大于基准值的数据放到右边刚刚大于基准值的数据的位置 items[left] = pivot # 最后left一定等于right,这时的位置就是基准值的位置 return left if leftNum is None or rightNum is None: leftNum = 0 rightNum = len(items) - 1 if leftNum < rightNum: pivotIndex = partition(leftNum, rightNum) quick_sort1(items, leftNum, pivotIndex - 1, comp) quick_sort1(items, pivotIndex + 1, rightNum, comp) return items
堆排序是利用堆这种数据结构设计的一种排序算法
大根堆: 每个节点的值都大于或等于其子节点的值, 用于升序排列
小根堆: 每个节点的值都小于或等于其子节点的值, 用于降序排列
def heap_sort(items): """堆排序""" # 调整堆 def adjust_heap(root, size_heap): l_child = 2 * root + 1 # 左孩子 r_child = l_child + 1 # 右孩子 larger = root # 当前节点 # 在当前节点,左孩子,右孩子中找到最大元素的索引 if l_child < size_heap and items[larger] < items[l_child]: larger = l_child if r_child < size_heap and items[larger] < items[r_child]: larger = r_child # 如果当前节点不是最大元素,那么把最大的节点与当前节点交换 if larger != root: items[larger], items[root] = items[root], items[larger] adjust_heap(larger, size_heap) def built_heap(): for j in range(len(items) // 2)[::-1]: # 从有子节点的最后一个根节点开始调整 adjust_heap(j, size) size = len(items) built_heap() for i in range(size)[::-1]: # 将堆顶与堆底对换,堆size-1 items[0], items[i] = items[i], items[0] adjust_heap(0, i) return items
计数排序会根据序列中的最大值N,开辟一个大小为N的计数空间,将序列中的数据值作为键, 数据出现的次数作为值.
def counting_sort(items): """计数排序""" bucket = [0] * (max(items) + 1) # 桶的个数 for item in items: # 计数 bucket[item] += 1 i = 0 # 待排序列表的索引 for j in range(len(bucket)): while bucket[j] > 0: items[i] = j bucket[j] -= 1 i += 1 return items
桶排序是计数排序的升级版,根据函数映射设定桶的个数与范围,然后将数据分到对应的桶里,对每个桶分别排序(可以使用别的排序算法来排序)
若想要桶排序更高效,有两种思路:
def bucket_sort(items, bucketSize=5): """桶排序,计数排序的升级版,若想桶排序更高效,可以尽量增大桶的数量;尽量平均的分配数据到桶中""" maxVal, minVal = max(items), min(items) bucketCount = (maxVal - minVal) // bucketSize + 1 buckets = [[] for _ in range(bucketCount)] # 二维桶 for item in items: buckets[(item - minVal) // bucketSize].append(item) # 将数据放入对应的桶中 items.clear() for bucket in buckets: if bucket: insert_sort(bucket) # 对桶中的元素进行排序 items.extend(bucket) # 将排好序的元素放入数组中 return items
基数排序有两种方法:
1.MSD(主位优先法): 从高位开始进行排序
2.LSD(次位优先法): 从低位开始进行排序
以LSD为例
def radix_sort(items): """基数排序,LSD -- 从低位开始排序""" mod = 10 div = 1 mostBit = len(str(max(items))) # 获取数组中最大数据的位数 buckets = [[] for _ in range(mod)] while mostBit: for item in items: buckets[item // div % mod].append(item) # 类似于计数排序 i = 0 for bucket in buckets: while bucket: items[i] = bucket.pop(0) i += 1 div *= 10 mostBit -= 1 return items
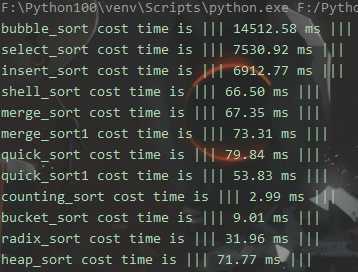
对一个用随机数生成的长度为10000的列表进行排序,各个算法所用时间
def sort(item, func): ary = item[:] start_time = time.time() func(ary) end_time = time.time() print(‘%s cost time is ||| %.2f ms |||‘ % (func.__name__, (end_time - start_time) * 1000)) if __name__ == ‘__main__‘: list1 = [random.randint(0, 10000) for _ in range(10000)] sorts = [bubble_sort, select_sort, insert_sort, shell_sort, merge_sort, merge_sort1, quick_sort, quick_sort1, counting_sort, bucket_sort, radix_sort, heap_sort, ] for foo in sorts: sort(list1, foo)
结果:
原文:https://www.cnblogs.com/gnlhzzz/p/12861057.html
