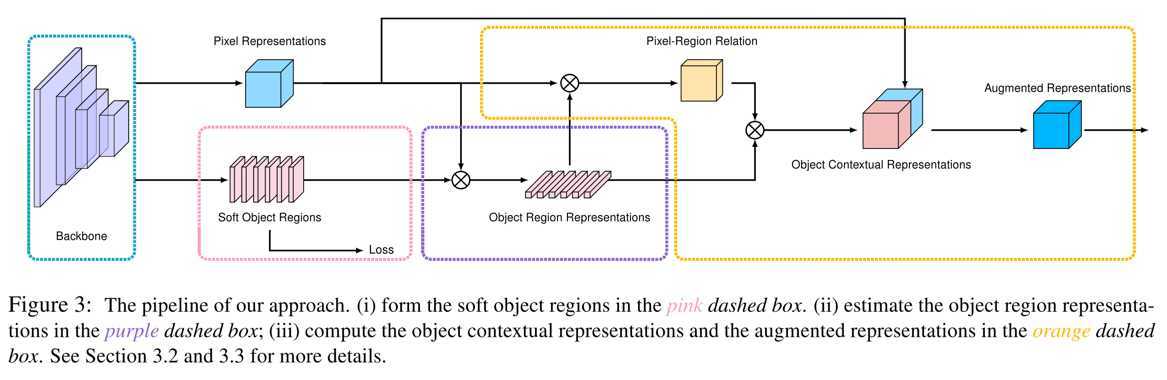
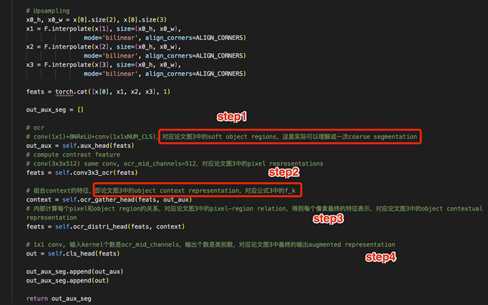
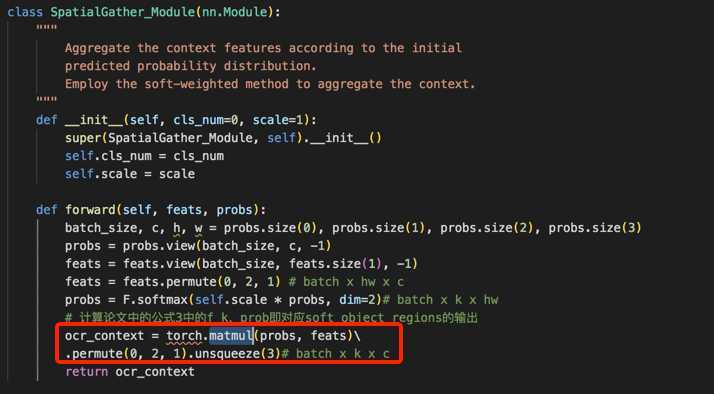
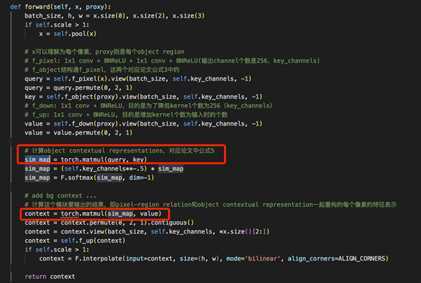
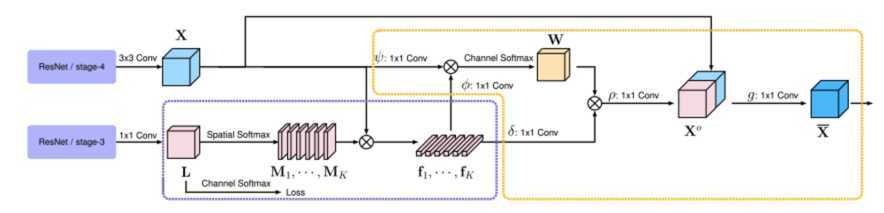
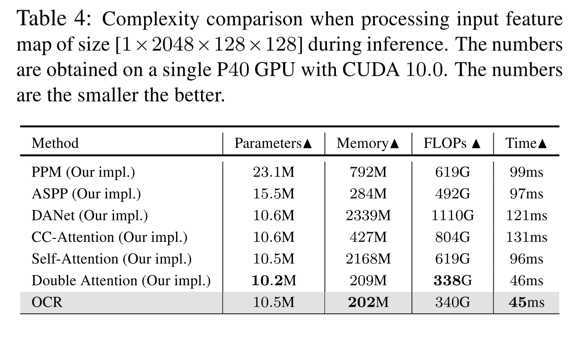
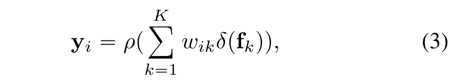paper: Object-Contextual Representations for Semantic Segmentation
code: PyTorch
写在后面
论文笔记-OCR-Object-Contextual Representations for Semantic Segmentation
原文:https://www.cnblogs.com/xiangs/p/12863173.html