以线性回归为例说明。(术语“线性回归”用来指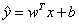 ,截距项b常称为仿射变换的偏置(bias)参数。仿射函数,即最高次数为1的多项式函数,常数项为0则为线性函数。)
,截距项b常称为仿射变换的偏置(bias)参数。仿射函数,即最高次数为1的多项式函数,常数项为0则为线性函数。)
我们的目标是建立一个系统,将向量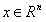 作为输入,预测标量
作为输入,预测标量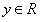 作为输出。
作为输出。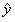 表示模型预测y应该取的值。定义输出为线性函数
表示模型预测y应该取的值。定义输出为线性函数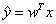 ,
,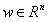 是参数向量。
是参数向量。
是度量模型性能的一种方法,计算模型在测试集上的均方误差。(测试误差=泛化误差)

当预测值与目标值之间的欧几里得距离增加时,误差增加。
为了构建一个机器学习算法,需要设计算法,通过观察训练集( x(train) , y(train) )获得经验,减少MSE(test)以改进权重w。
一种直观方式是最小化训练集均方误差MSE(train)。
我们可以简单求解其导数为0的情况:

这里的m是训练集的样本数,其实应该写成m(train)。
5.10到5.11,用到了向量和矩阵求导公式。5.6-5.12就是在MSE(train)取极小值时(导数=0),求解w的过程。
5.12是正规方程(normal equation),代入数值就是w的最优解,也就是MSE(train)取最小值时对应的w值。
参考:
lanGoodfellow,Yoshua,Bengio《深度学习》
原文:https://www.cnblogs.com/sybil-hxl/p/12864644.html