1.经过自己在网上的学习和自己摸索,学会了如何去爬取网页上的东西,和进行数据分析。
2,首先先安装必要的库。然后就到了最烦人的找网站环节,借鉴了别的同学的网站后,我也开始往他们那方面找,找一些与排行有关的网站,但都找不到像他们那样爬取效果比较好的网站,最后在邱泽宇同学推荐的排行榜网站上,找到了一个关于汽车发动机排行的网站,就决定是它了。
3,源代码:
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
url="https://www.270top.com/yongche/19432.html"
r=requests.get(url)
try:
r.raise_for_status()
r.encoding=r.apparent_encoding
data=r.text
except:
print("ERROR")
soup=BeautifulSoup(data,"html.parser")
a=soup.find_all(‘p‘)
for i in range(3,14):
print(a[i].get_text())
plt.xlabel("year")
plt.ylabel("ranking")
plt.title("Ford engine ranking over the years")
x=[2009,2010,2011,2012,2013,2014,2015,2016,2017,2018,2019]
y=[6,4,5,5,5,4,1,4,4,7,2]
plt.plot(x,y,"g-s")
plt.show()
4,效果:
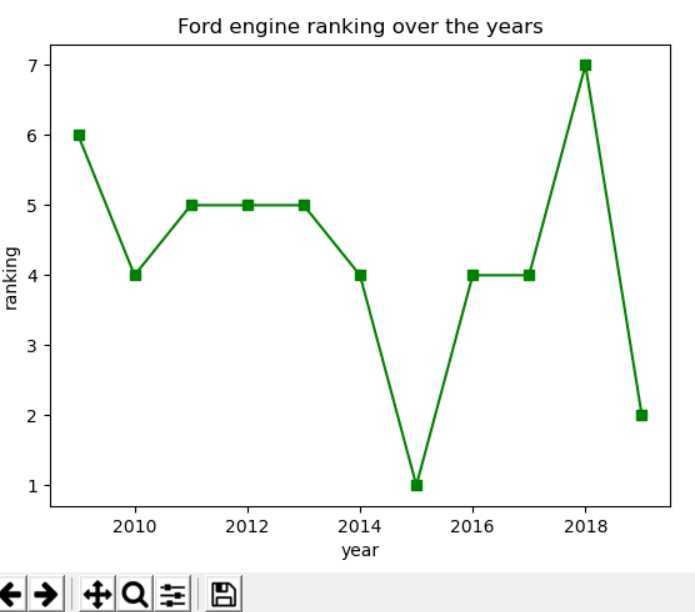
5,总结:
学到这里不得不感慨python功能的强大,还有我们掌握的还太少,想要发现python更多强大的功能还需我们不断的去探索,去学习。
原文:https://www.cnblogs.com/qq9962/p/12875221.html