Go语言中的并发程序可以用两种手段来实现。本章讲解goroutine和channel,其支持“顺序通信进程”(communicating sequential processes)或被简称为CSP。CSP是一种现代的并发编程模型,在这种编程模型中值会在不同的运行实例(goroutine)中传递,尽管大多数情况下仍然是被限制在单一实例中。
主函数返回时,所有的goroutine都会被直接打断,程序退出。除了从主函数退出或者直接终止程序之外,没有其它的编程方法能够让一个goroutine来打断另一个的执行,但是之后可以看到一种方式来实现这个目的,通过goroutine之间的通信来让一个goroutine请求其它的goroutine,并让被请求的goroutine自行结束执行。
ch := make(chan int) // ch has type ‘chan int‘
ch = make(chan int, 3) // buffered channel with capacity 3
和map类似,channel也对应一个make创建的底层数据结构的引用。当我们复制一个channel或用于函数参数传递时,我们只是拷贝了一个channel引用,因此调用者和被调用者将引用同一个channel对象。和其它的引用类型一样,channel的零值也是nil。
两个相同类型的channel可以使用==运算符比较。如果两个channel引用的是相同的对象,那么比较的结果为真。一个channel也可以和nil进行比较。
ch <- x // 传x给ch
x = <-ch // 传ch内的值给x
<-ch // 无接收对象也是合法的
Channel还支持close操作,用于关闭channel,随后对基于该channel的任何发送操作都将导致panic异常。对一个已经被close过的channel进行接收操作依然可以接受到之前已经成功发送的数据(虽然关闭了,但是通道里可能还有数据,可以“倒”出来);如果channel中已经没有数据的话将产生一个零值的数据。
close(ch)
基于无缓存Channels的发送和接收操作将导致两个goroutine做一次同步操作。因为这个原因,无缓存Channels有时候也被称为同步Channels。当通过一个无缓存Channels发送数据时,接收者收到数据发生(happens before)在唤醒发送者goroutine之前。
当我们说x事件既不是在y事件之前发生也不是在y事件之后发生,我们就说x事件和y事件是并发的。这并不是意味着x事件和y事件就一定是同时发生的,我们只是不能确定这两个事件发生的先后顺序。
我们需要让主函数等待后台goroutine完成工作后再退出,我们使用了一个channel来同步两个goroutine:
func main() {
conn, err := net.Dial("tcp", "localhost:8000")
if err != nil {
log.Fatal(err)
}
done := make(chan struct{})
go func() {
io.Copy(os.Stdout, conn) // NOTE: ignoring errors
log.Println("done")
done <- struct{}{} // 通知主函数,协程执行完毕
}()
mustCopy(conn, os.Stdin)
conn.Close()
<-done // 由于是无缓存channel,无法取值时会自动阻塞。
}
channel除了当做同步值外,他还能作为发送信息的机制。在前者情景下,我们称其为消息事件,因为他不携带额外的消息,只是作为同步信息来用,所以我们可以使用bool或int类型实现的消息,如done<-1。
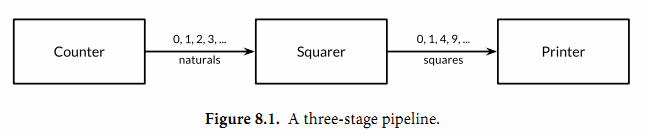
使用range循环是上面处理模式的简洁语法,它依次从channel接收数据,当channel被关闭并且没有值可接收时跳出循环。
func main() {
naturals := make(chan int)
squares := make(chan int)
// Counter
go func() {
for x := 0; x < 100; x++ {
naturals <- x
}
close(naturals)
}()
// Squarer
go func() {
for x := range naturals {
// 当naturals关闭或者没有值时自动关闭
squares <- x * x
}
close(squares)
}()
// Printer (in main goroutine)
for x := range squares {
fmt.Println(x)
}
}
这种场景是典型的。当一个channel作为一个函数参数时,它一般总是被专门用于只发送或者只接收。
为了表明这种意图并防止被滥用,Go语言的类型系统提供了单方向的channel类型,分别用于只发送或只接收的channel。类型chan<- int表示一个只发送int的channel,只能发送不能接收。相反,类型<-chan int表示一个只接收int的channel,只能接收不能发送。(箭头<-和关键字chan的相对位置表明了channel的方向。)这种限制将在编译期检测。
chan<- type //只发送
<-chan type // 只接收
ch = make(chan string, 3)
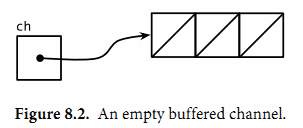
向缓存Channel的发送操作就是向内部缓存队列的尾部插入元素,接收操作则是从队列的头部删除元素。如果内部缓存队列是满的,那么发送操作将阻塞直到因另一个goroutine执行接收操作而释放了新的队列空间。相反,如果channel是空的,接收操作将阻塞直到有另一个goroutine执行发送操作而向队列插入元素。
下面的例子展示了一个使用了带缓存channel的应用。它并发地向三个镜像站点发出请求,三个镜像站点分散在不同的地理位置。它们分别将收到的响应发送到带缓存channel,最后接收者只接收第一个收到的响应,也就是最快的那个响应。因此mirroredQuery函数可能在另外两个响应慢的镜像站点响应之前就返回了结果。(顺便说一下,多个goroutines并发地向同一个channel发送数据,或从同一个channel接收数据都是常见的用法。)
func mirroredQuery() string {
responses := make(chan string, 3)
go func() { responses <- request("asia.gopl.io") }()
go func() { responses <- request("europe.gopl.io") }()
go func() { responses <- request("americas.gopl.io") }()
return <-responses // return the quickest response
}
func request(hostname string) (response string) { /* ... */ }
如果我们使用了无缓存的channel,那么两个慢的goroutines将会因为没有人接收而被永远卡住。这种情况,称为goroutines泄漏,这将是一个BUG。和垃圾变量不同,泄漏的goroutines并不会被自动回收,因此确保每个不再需要的goroutine能正常退出是重要的。
像处理多个文件这种问题,是并行的最佳场景,因为这类问题可以通过并行来隐藏掉文件IO时间。
比如下面的例子,我们要为所有图片生成一些缩略图。将文件IO的延迟隐藏掉,并用上多核cpu的计算能力来拉伸图像。
// 非并行写法
//这种写法,第二张图片的IO过程需要等待第一张图片计算完成
func makeThumbnails(filenames []string) {
for _, f := range filenames {
if _, err := thumbnail.ImageFile(f); err != nil {
log.Println(err)
}
}
}
//并行写法
// 这个版本没有错误处理
func makeThumbnails3(filenames []string) {
ch := make(chan struct{})
for _, f := range filenames {
go func(f string) {
thumbnail.ImageFile(f) // NOTE: ignoring errors
ch <- struct{}{}
}(f) //显式地添加这个参数,我们能够确保使用的f是当go语句执行时的“当前”那个f。
}
// Wait for goroutines to complete.
for range filenames {
<-ch
}
}
回忆一下之前在5.6.1节中,匿名函数中的循环变量快照问题。上面这个单独的变量f是被所有的匿名函数值所共享,且会被连续的循环迭代所更新的。当新的goroutine开始执行字面函数时,for循环可能已经更新了f并且开始了另一轮的迭代或者(更有可能的)已经结束了整个循环,所以当这些goroutine开始读取f的值时,它们所看到的值已经是slice的最后一个元素了。显式地添加这个参数,我们能够确保使用的f是当go语句执行时的“当前”那个f。
//并行完整版
func makeThumbnails5(filenames []string) (thumbfiles []string, err error) {
type item struct {
thumbfile string
err error
}
ch := make(chan item, len(filenames))
for _, f := range filenames {
go func(f string) {
var it item
it.thumbfile, it.err = thumbnail.ImageFile(f)
ch <- it
}(f)
}
for range filenames {
it := <-ch
if it.err != nil {
return nil, it.err
}
thumbfiles = append(thumbfiles, it.thumbfile)
}
return thumbfiles, nil
}
为了知道最后一个goroutine什么时候结束(最后一个结束并不一定是最后一个开始),我们需要一个递增的计数器,在每一个goroutine启动时加一,在goroutine退出时减一。这需要一种特殊的计数器,这个计数器需要在多个goroutine操作时做到安全并且提供在其减为零之前一直等待的一种方法。这种计数类型被称为sync.WaitGroup,下面的代码就用到了这种方法:
func makeThumbnails6(filenames <-chan string) int64 {
sizes := make(chan int64)
var wg sync.WaitGroup // number of working goroutines
for f := range filenames {
wg.Add(1)
// worker
go func(f string) {
defer wg.Done() //使用defer能保证在出错的情况下也能正确关闭
thumb, err := thumbnail.ImageFile(f)
if err != nil {
log.Println(err)
return
}
info, _ := os.Stat(thumb) // OK to ignore error
sizes <- info.Size()
}(f)
}
// closer
go func() {
wg.Wait()
close(sizes)
}()
var total int64
for size := range sizes {
total += size
}
return total
}
Done却没有任何参数;其实它和Add(-1)是等价的。我们使用defer来确保计数器即使是在出错的情况下依然能够正确地被减掉。上面的程序代码结构是当我们使用并发循环,但又不知道迭代次数时很通常而且很地道的写法。
一种可能的手段是向abort的channel里发送和goroutine数目一样多的事件来退出它们。如果这些goroutine中已经有一些自己退出了,那么会导致我们的channel里的事件数比goroutine还多,这样导致我们的发送直接被阻塞。另一方面,如果这些goroutine又生成了其它的goroutine,我们的channel里的数目又太少了,所以有些goroutine可能会无法接收到退出消息。
所以,一般情况下我们是很难知道在某一个时刻具体有多少个goroutine在运行着的。
回忆一下我们关闭了一个channel并且被消费掉了所有已发送的值,操作channel之后的代码可以立即被执行,并且会产生零值。我们可以将这个机制扩展一下,来作为我们的广播机制:
不要向channel发送值,而是用关闭一个channel来进行广播。
var done = make(chan struct{})
func cancelled() bool {
select {
case <-done:
return true
default:
return false
}
}
go语言圣经第8章Goroutines 和 Channels
原文:https://www.cnblogs.com/Jun10ng/p/12879592.html