在上一篇文章中《程序是如何在 CPU 中运行的(一)》笔者讲述了程序中一条一条指令以及一条一条数据是如何在 CPU 中运行的,在本文笔者将以 ARM Cortex M3 的内核为背景分析指令是如何有序的执行。
为了更好地介绍指令是如何在 ARM Cortex M3 内核中运行的,在这里先介绍一下 ARM Cortex M3 的寄存器组,引用 ARM Cortex M3 权威指南的一张图,图片如下:

如上图所示,寄存器组主要包含四种类型的寄存器,分别是:
通用寄存器:用于数据操作
堆栈指针:堆栈指针有两个,但是在任一时刻只能使用其中的一个。
连接寄存器:当呼叫一个子程序时,由 R14 存储返回地址。
程序计数器:用于存储下一条即将运行的指令的地址。
寄存器组介绍完之后,我们来看具体的实例。
首先看一个顺序执行的例子,代码如下,C 语言下面对应的是汇编代码,汇编代码冒号前的是当前指令对应的地址。
int main(void)
{
int a = 123;
0x0800021E : MOVS r1,#0x7B
int b = 456;
0x08000220 : MOV r2,#0x1CB
int result = a + b;
0x08000224 : ADDS r3,r1,r2
return 0;
0x08000226 : MOVS r0,#0x00
}
上述代码的汇编语言涉及到的寄存器都是通用寄存器,通过 C 语言代码我们也可以知道对应的汇编代码的意思,这也印证了前面所说的通用寄存器的功能就是用于数据操作的。
那上述程序是如何运行的呢,这时之前说到的程序计数器,也就是我们所说的 PC 指针就要排上用场了,如下图片展示了程序计数器在上述指令运行过程中的一个变化。
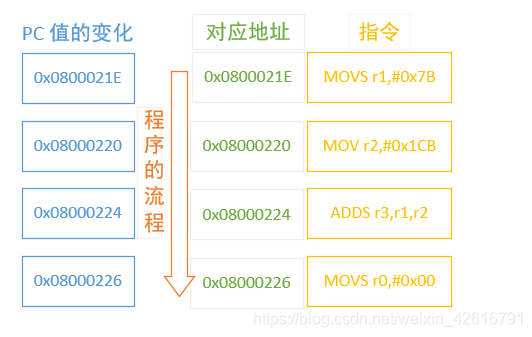
通过上图可以看出,左边是即将执行的指令,中间是指令存储的位置,那么 PC 存储的值一直是即将执行的下一条指令的地址,这样程序也就可以顺序的执行下去了。
条件分支是根据条件执行任意地址的指令,也就是说程序不是向上述一样顺序执行了,那 CPU 又如何处理这种情况呢?我们来看一个简单 if 语句例子:
int main(void)
{
int a = 123;
0x0800021E : MOVS r1,#0x7B
int b = 456;
0x08000220 : MOV r2,#0x1CB
int result = a - b;
0x08000224 : SUBS r1,r2,r3
if (result > 0)
0x08000226 : CMP r1,#0x00
0x08000228 : BLE 0x0800022E
result = result + 1;
0x0800022A : ADDS r1,r1,#1
else
result = 1 - result;
0x0800022E : RSB r1,r1,#0x01
return 0;
0x08000232 : MOVS r0,#0x00
}
上述的汇编与 C 语言一一对应,很容易知道每条指令的意思,在这里笔者单独拿出来两个与语句跳转相关的指令说一下:
现在来看汇编代码,比较关键的地方就是使用 CMP 判断,判断结果小于 0 ,所以跳转到 0x0800022E 地址对应的指令进行执行,也就是执行 result = 1 - result; 同样的,我们也用示意图的形式表示一下在这个过程 PC 值的变化。
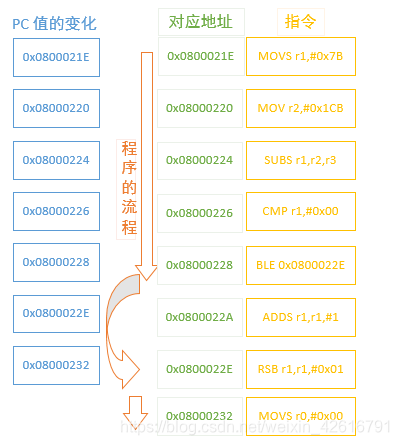
如上图所示,由于使用了条件分支,程序在执行到地址为 0x08000228 的时候,下一条要执行的指令地址并不是 0x0800022A,而是直接跳转到地址为 0x0800022E 的指令进行执行,那 PC 值的变化也就是图中左侧所示,因为没有没有执行一条指令,所以 PC 的变化次数也就比总的指令数少一条。
函数调用和使用条件分支有所不同,因为单纯的跳转指令无法实现函数的调用。函数调用需要在完成函数内部的处理之后,处理流程再返回到函数调用点,也就是返回到函数调用指令的下一条指令,因此针对于函数调用来讲,涉及到函数返回地址的处理。
涉及到函数调用我们都有一个概念,就是说函数调用时会把函数返回地址进行压栈,也就是说把返回地址存入到堆栈里,函数返回时再从堆栈里取出返回地址,但是对于 ARM Cortex M3 的处理器来讲,再处理一级函数调用时,它并没有将函数返回地址进行压栈,而是将子程序的返回地址存放在 R14 连接寄存器里,函数返回时再从这个寄存器里取出返回值就可以了。这也印证了前文所说的这个寄存器是用于存储子程序的返回地址的,下面用一个简单的例子来说明这个问题:
int MyFunc(int a,int b)
{
int temp;
0x0800019A MOV r2,r0
temp = a + b;
return temp;
0x0800019C ADDS r0,r2,r1
0x0800019E BX lr
}
int main(void)
{
int a = 123;
0x08000224 MOVS r4,#0x7B
int b = 456;
0x08000226 MOV r5,#0x1C8
int result = a - b;
0x0800022A SUBS r6,r4,r5
result = MyFunc(a,b);
0x0800022C MOV r1,r5
0x0800022E MOV r0,r4
0x08000230 BL.W MyFunc (0x0800019A)
0x08000234 MOV r6,r0
return 0;
0x08000236 MOVS r0,#0x00
}
同样的,我们给出一级函数调用的示意图:
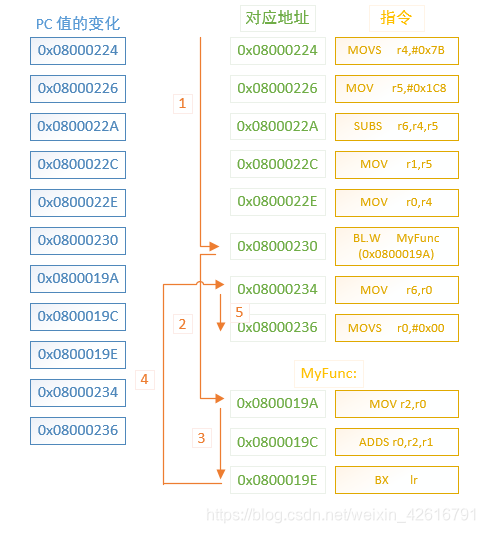
通过上述的汇编代码也可以看到虽然有了函数调用,但是在这里并没有进行压栈操作,整个程序的执行流程也如图中序号所示,在执行到函数调用的语句时,就执行 BL.W 指令跳转到函数的入口地址,子单数执行完之后,再返回至函数调用指令的下一条指令的地址,继续执行主函数没有执行完的内容,相应的 PC 指针寄存器的值也在发生变化。
二级函数调用和多级函数调用的原理是一样的,但是不同于一级函数调用,在进行二级函数调用时,会涉及到两个子函数的返回地址,但是只有一个 R14(LR) 寄存器,只能存储一个返回地址,那要怎么办呢?这个时候,就要使用到堆栈的机制,堆栈的特性是先入后出,在函数嵌套调用过程中,先调用的函数的返回地址要在后返回,而后调用的函数返回地址要在先返回,所以堆栈刚好能够处理这样的事情。同样,我们来看一个二级函数调用的例子:
int MyFunc2(int a)
{
int temp;
0x080001AC MOV r1,r0
temp = a + 1;
return temp;
0x080001AE ADDS r0,r1,#1
0x080001B0 BX lr
}
int MyFunc(int a,int b)
{
int temp;
0x0800019A PUSH {r4-r5,lr}
0x0800019C MOV r4,r0
0x0800019E MOV r5,r1
temp = MyFunc2(temp);
0x080001A0 MOV r0,r3
0x080001A2 BL.W MyFunc2 (0x080001AC)
0x080001A6 MOV r3,r0
return temp;
0x080001A8 MOV r0,r3
0x080001AA POP {r4-r5,pc}
}
int main(void)
{
int a = 123;
0x08000238 MOVS r4,#0x7B
int b = 456;
0x0800023A MOV r5,#0x1C8
int result = a - b;
0x0800023E SUBS r6,r4,r5
result = MyFunc(a,b);
0x08000240 MOV r1,r5
0x08000242 MOV r0,r4
0x08000244 BL.W MyFunc (0x0800019A)
0x08000248 MOV r6,r0
return 0;
0x0800024A MOVS r0,#0x00
}
二级函数调用比一级函数调用要略复杂一些了,同样的,我们给出二级函数调用的示意图:
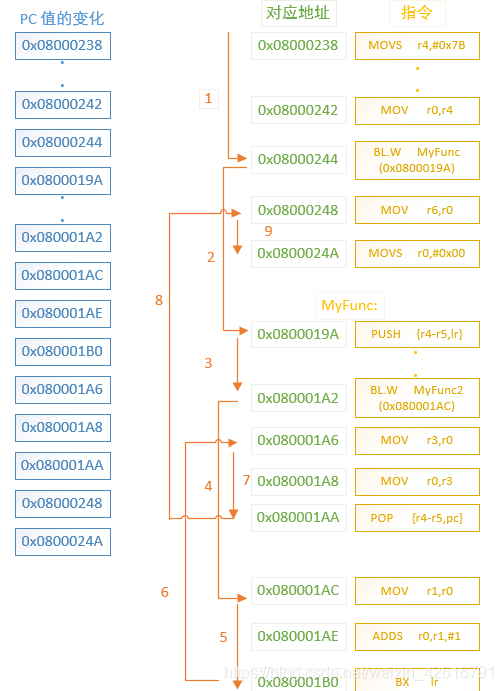
由于指令数有点多,通过省略号来替代一些与函数调用无关的指令。通过图片我们也可以更清楚地看到函数的调用过程以及 PC 值的变化,PC 值的变化是一直跟随着箭头的走向的。在这小节的开头,笔者也说到涉及到二级函数调用时,需要使用堆栈,现在看到汇编代码,也的确是这样,当程序进入到 MyFunc 的第一时间,就是将 LR 寄存器的值压入堆栈,因为 MyFunc2 是最后一层函数调用,因此 MyFunc2 函数调用的返回地址不需要进行压栈,直接使用 LR 寄存器的值进行返回就好,我们再看,当 MyFunc2 返回后,MyFunc 也要返回,这时候,需要出栈,即将刚刚压入堆栈的 LR 寄存器的值赋值给 PC 指针寄存器,PC 指针寄存器永远存放的是即将指令的下一条指令的地址,MyFunc 返回主函数后执行剩余的内容。
上述就是涉及到的顺序执行,条件分支,和函数调用的相关内容。可以看到无论是哪一种形式,其实本质就是 PC 值的变化,PC 值永远存储的是即将运行的下一条指令的地址,控制这个值就能够控制程序的走向。另外需要注意的一点是,对于 ARM Cortex M3 系列的内核来说,涉及到一级函数调用的时候,不需要进行压栈操作,涉及到多级函数调用的时候,才会使用到堆栈。
最后,如果您觉得我的文章对您有帮助,欢迎添加我的个人公众号:wenzi嵌入式软件

原文:https://www.cnblogs.com/wenziw5/p/12884142.html