1.
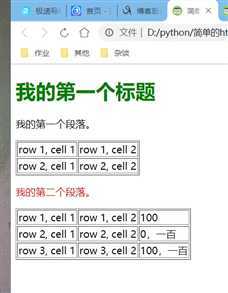
<!--简单的html页面--> <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>简单的html页面 53</title> </head> <body> <h1 style="color:green">我的第一个标题</h1> <p id="first">我的第一个段落。</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> </tr> </table> <p style="color:red">我的第二个段落。</p> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> <td>100</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> <td>0,一百</td> </tr> <tr> <td>row 3, cell 1</td> <td>row 3, cell 2</td> <td>100,一百</td> </tr> </table> </html>
2.爬取中国大学排名网站内容
import requests from bs4 import BeautifulSoup allUniv=[] def get(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return "" def f(soup): data=soup.find_all(‘tr‘) for tr in data: ltd=tr.find_all(‘td‘) if len(ltd)==0: continue s=[] for td in ltd: s.append(td.string) allUniv.append(s) def p(num): print("{:^4}{:^10}{:^5}{:^8}{:^10}".format("排名","学校名称","省市","总分","人才培养得分","生源质量(新生高考成绩得分)")) for i in range(num): u=allUniv[i] print("{:^4}{:^10}{:^5}{:^8}{:^10}".format(u[0],u[1],u[2],u[3],u[6])) def main(num): u=‘http://http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html‘ h=get(u) soup=BeautifulSoup(h,"html.parser") f(soup) p(num) main(10)
3.用requests库的get()函数访问百度20次
import requests def getHTMLText(url): try: r=requests.get(url,timeout=20) r.raise_for_status() r.encoding=‘utf-8‘ return r.status_code except: return"" url="http://www.sogou.com" for i in range(20): print(getHTMLText(url))

原文:https://www.cnblogs.com/LCXYJTM/p/12884089.html