AutoEncoder作为NN里的一类模型,采用无监督学习的方式对高维数据进行高效的特征提取和特征表示,并且在学术界和工业界都大放异彩。本文主要介绍AutoEncoder系列模型框架的演进,旨在梳理AutoEncoder的基本原理。首先上图,然后再对他们进行逐一介绍。
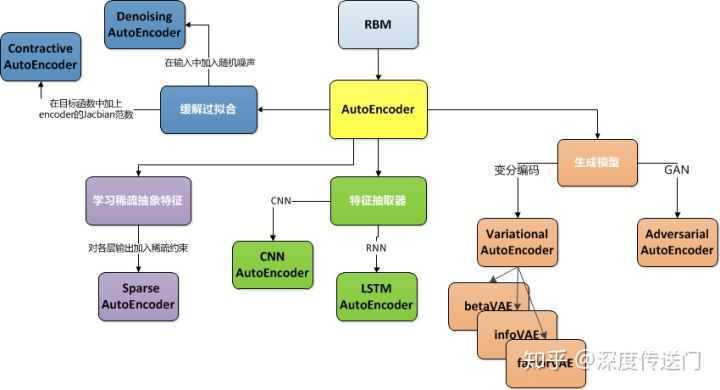
AutoEncoder的思想最早被提出来要追溯到1988年[1],当时的模型由于数据过于稀疏高维计算复杂度高很难优化,没能得到广泛的引用。直到2006年,Hinton等人[2]采用梯度下降来逐层优化RBM从而实现对原始样本/特征的抽象表示,并在特征降维上取得显著效果。这才使得采用神经网络来构建AutoEncoder的方法得到广泛关注。
在介绍经典的基于神经网络的AutoEncoder模型之前,先来整体看一下AutoEncoder框架的基本思想,如下图所示。AutoEncoder框架包含两大模块:编码过程和解码过程。通过encoder(g)将输入样本x映射到特征空间z,即编码过程;然后再通过decoder(f)将抽象特征z映射回原始空间得到重构样本x‘,即解码过程。优化目标则是通过最小化重构误差来同时优化encoder和decoder,从而学习得到针对样本输入x的抽象特征表示z。
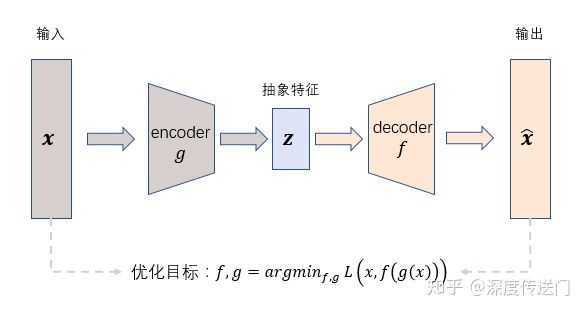
这里我们可以看到,AutoEncoder在优化过程中无需使用样本的label,本质上是把样本的输入同时作为神经网络的输入和输出,通过最小化重构误差希望学习到样本的抽象特征表示z。这种无监督的优化方式大大提升了模型的通用性。
对于基于神经网络的AutoEncoder模型来说,则是encoder部分通过逐层降低神经元个数来对数据进行压缩;decoder部分基于数据的抽象表示逐层提升神经元数量,最终实现对输入样本的重构。
这里指的注意的是,由于AutoEncoder通过神经网络来学习每个样本的唯一抽象表示,这会带来一个问题:当神经网络的参数复杂到一定程度时AutoEncoder很容易存在过拟合的风险。
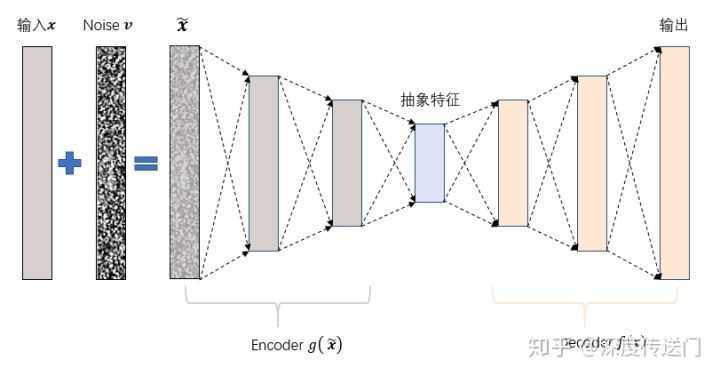
为了缓解经典AutoEncoder容易过拟合的问题,一个办法是在输入中加入随机噪声;Vincent等人[3]提出了Denoising AutoEncoder,在传统AutoEncoder输入层加入随机噪声来增强模型的鲁棒性。另一个办法就是结合正则化思想,Rifai等人[4]提出了Contractive AutoEncoder,通过在AutoEncoder目标函数中加上encoder的Jacobian矩阵范式来约束使得encoder能够学到具有抗干扰的抽象特征。
下图是Denoising AutoEncoder的模型框架。目前添加噪声的方式大多分为两种:添加服从特定分布的随机噪声;随机将输入x中特定比例置为0。有没有觉得第二种方法跟现在广泛石红的Dropout很相似,但是Dropout方法是Hinton等人在2012年才提出来的,而第二种加噪声的方法在08年就已经被应用了。这其中的关系,就留给你思考一下。
为了在学习输入样本表示的时候可以得到稀疏的高维抽象特征表示,Ng等人[5]在原来的损失函数中加入了一个控制稀疏化的正则项。稀疏约束能迫使encoder的各层只有部分神经元被激活,从而将样本映射成低维稀疏特征向量。
具体来说,如果单个神经元被激活的概率很小,则可认为该网络具有稀疏性。神经元是否被激活可以看做服从概率的伯努利分布。因此可以使用KL散度来衡量神经元被激活的概率ρ^与期望概率ρ之间的loss:

通过将D_KL加入到AutoEncoder的目标函数中,即可实现对神经网络稀疏性的约束。另外,还有一种方法就是对神经网络各层的输出加入L1约束。
其实无论是Convolutional Autoencoder[6]、 Recursive Autoencoder还是LSTM Autoencoder[7]等等,思路都是将传统NN网络的结构融入到AutoEncoder中。
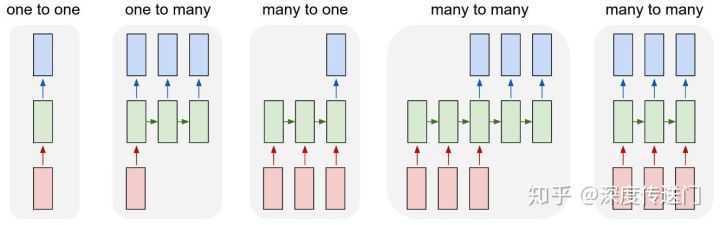
以LSTM AutoEncoder为例,目标是针对输入的样本序列学习得到抽象特征z。因此encoder部分是输入一个样本序列输出抽象特征z,采用如下的Many-to-one LSTM;而decoder部分则是根据抽象特征z,重构出序列,采用如下的One-to-many LSTM。
将传统NN网络的结构引入AutoEncoder其实更多是一个大概的思想,具体实现的时候,编码器和解码器都是不固定的,可选的有CNN/RNN/双向RNN/LSTM/GRU等等,而且可以根据需要自由组合。
Vairational AutoEncoder(VAE)是Kingma等人与2014年提出。VAE比较大的不同点在于:VAE不再将输入x映射到一个固定的抽象特征z上,而是假设样本x的抽象特征z服从(μ,σ^2)的正态分布,然后再通过分布生成抽象特征z。最后基于z通过decoder得到输出。模型框架如下图所示:
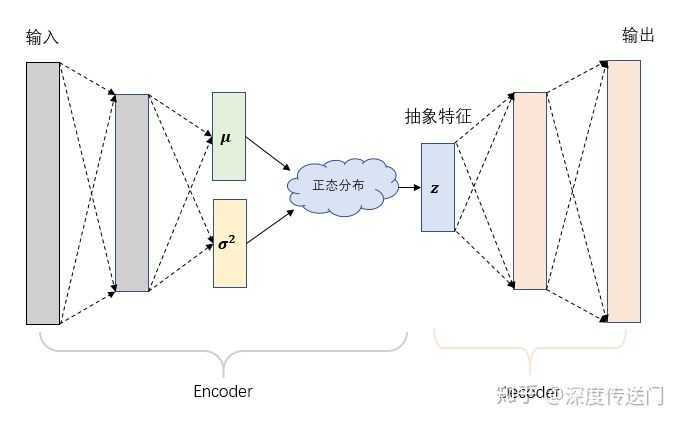
由于抽象特征z是从正态分布采样生成而来,因此VAE的encoder部分是一个生成模型,然后再结合decoder来实现重构保证信息没有丢失。VAE是一个里程碑式的研究成果,倒不是因为他是一个效果多么好的生成模型,主要是提供了一个结合概率图的思路来增强模型的鲁棒性。后续有很多基于VAE的扩展,包括infoVAE、betaVAE和factorVAE等。
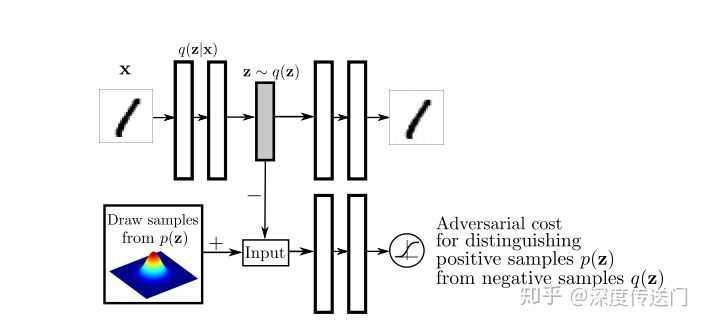
既然说到生成模型引入AutoEncoder,那必定也少不了将GAN的思路引入AutoEncoder[9],也取得了不错的效果。
对抗自编码器的网络结构主要分成两大部分:自编码部分(上半部分)、GAN判别网络(下半部分)。整个框架也就是GAN和AutoEncoder框架二者的结合。训练过程分成两个阶段:首先是样本重构阶段,通过梯度下降更新自编码器encoder部分、以及decoder的参数、使得重构损失函数最小化;然后是正则化约束阶段,交替更新判别网络参数和生成网络(encoder部分)参数以此提高encoder部分混淆判别网络的能力。
一旦训练完毕,自编码器的encoder部分便学习到了从样本数据x到抽象特征z的映射关系。
[1] Auto-association by multilayer perceptrons and singular value decomposition, Bourlard etc, 1988
[2] Reducing the dimensionality of data with neural networks, Geoffrey Hinton etc, 2006
[3] Extracting and composing robust features with denoising autoencoders, Pascal Vincent etc, 2008
[4] Contractive auto-encoders: Explicit invariance during feature extraction, Rifai S etc, 2011
[5] Sparse autoencoder, Andrew Ng, etc, 2011
[6] Stacked Convolutional Auto-Encoders for Hierarchical Feature, Jonathan Masci, Jurgen Schmidhuber etc, 2011
[7] Unsupervised Learning of Video Representations using LSTMs, Nitish Srivastava etc, 2015
[8] Auto-encoding variational bayes, Diederik Kingma etc, ICLR 2014
[9] Adversarial Autoencoders, Alireza Makhzani, Ian Goodfellow etc, 2015
自编码器AutoEncoder,降噪自编码器DAE,稀疏自编码器SAE,变分自编码器VAE 简介
原文:https://www.cnblogs.com/jins-note/p/12883863.html