摘要:对于线性方程组Ax=b,系数矩阵A非奇异,且b≠0,从而具有唯一的非零解。其中非奇异矩阵是矩阵A的秩是满秩(线性代数内容)。【如果A是满秩,b=0,线性方程组只有零解。因此,需要限定A是非奇异矩阵,且b≠0】
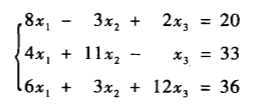
本文无特殊说明,都是用这个线性方程组作为示例。
一.jacobi迭代法
从第i个方程组解出xi。
线性方程组Ax=b,先给定一组x的初始值,如[0,0,0],第一次迭代,用x2=0,x3=0带入第一个式子得到x1的第一次迭代结果,用x1=0,x3=0,带入第二个式子得到x2的第一次迭代结果,用x1=0,x2=0带入第三个式子得到x3的第一次迭代结果。得到第一次的x后,重复第一次的运算。

二.Gauss-Seidel迭代法【收敛速度更快】
这个可以和jacobi法对比进行理解,我们以第二次迭代为例(这里的第一次迭代结果都用一样的,懒得去换)
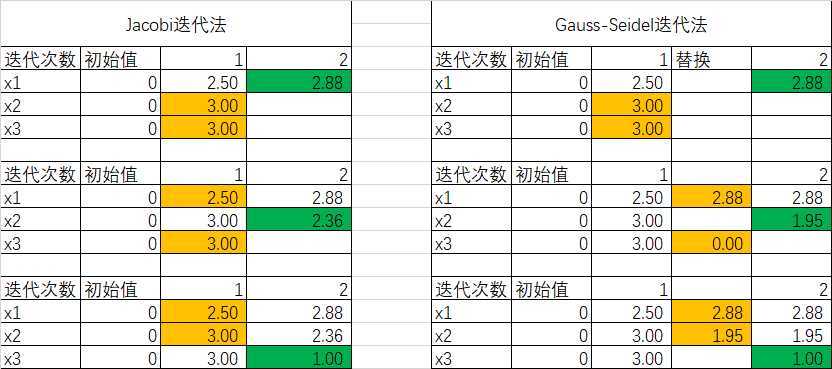
从上表对比结果可以看出,Jacobi方法的第二次迭代的时候,都是从第一次迭代结果中,获取输入值。
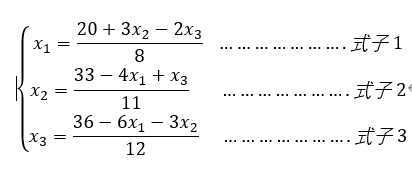
上一次迭代结果[2.5,3.0,3.0],将这个结果带入上面式子1,得到x1=2.88,;将[2.5,3.0,3.0]替换成[2.88,3.0,3.0]带入第二个式子的运算,这里得到x2=1.95,所以把[2.88,3.0,3.0]替换成[2.88,1.95,3.0]输入第三个式子计算X3=1.0.这就完成了这一次的迭代,得到迭代结果[2.88,1.95,1.0],基于这个结果,开始下一次迭代。
特点:jacobi迭代法,需要存储,上一次的迭代结果,也要存储这一次的迭代结果,所以需要两组存储单元。

而Gauss-Seidel迭代法,每一次迭代得到的每一个式子得到的值,替换上一次迭代结果中的值即可。所以只需要一组存储单元。

三.逐次超松弛法SOR法
上面仅仅通过实例说明,Jacobi和Seidel迭代的运算过程。并没有构造其一般的计算公式。
Gauss-Seidel迭代法的一般公式:
![]() .......................式1.1
.......................式1.1
对于这个公式,怎么看着都比较别扭,分解一下就是
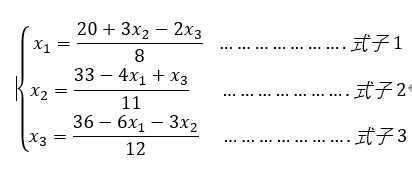
将式1.1改写:
![]() .......................式1.2
.......................式1.2
同样分解一下:
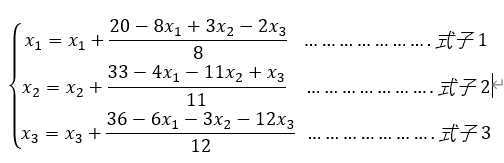
注意:左侧的x是本次(k+1)需要求的迭代结果,右侧的x是上次(k)的迭代结果。
![]() .......................式1.3
.......................式1.3
![]() .......................式1.4
.......................式1.4
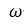 松弛因子,当松弛因子=1时,就是seidel迭代法,当调节松弛因子时,可以加快或减缓迭代速度。(和深度学习中的学习因子一个意思)
松弛因子,当松弛因子=1时,就是seidel迭代法,当调节松弛因子时,可以加快或减缓迭代速度。(和深度学习中的学习因子一个意思)
改写成矩阵形式:
![]()
分解一下:
这个特别有意思,怎么公式中出来了下三角矩阵L和上三角矩阵U。
原文:https://www.cnblogs.com/liuhuacai/p/12884151.html